本文提出了 Cola DLM,一种分层连续潜变量扩散语言模型。该模型结合了 Text VAE 与 block-causal DiT,在连续潜空间内执行 Prior Transport,在多项生成任务中达到了与强基线(如 Llama-2-70B 级别)相当的性能。
TL;DR
ByteDance Seed 团队提出的 Cola DLM 挑战了“大语言模型必须是自回归(AR)”的固有印象。它通过 Text VAE + Block-Causal DiT 的分层设计,将文本生成拆解为“全局语义组织”与“局部文本实现”。实验证明,在连续潜空间中通过扩散模型传输 Prior,不仅能获得极强的扩展性(Scaling Law),还为图文统一建模铺平了道路。
痛点深挖:自回归的“围城”与离散扩散的“泥潭”
当前 LLM 统治范式是 Next-Token Prediction。尽管成功,但这种“逐词蹦迪”的方式存在三大痛点:
- 顺序耦合:推理是严格串行的,无法进行全局规划。
- 归纳偏置局限:模型被限制在单一的左向右视角,处理 Infilling(填空)或编辑任务时极其笨拙。
- 离散空间的陷阱:单纯的离散扩散模型(如 LLaDA)虽然打破了顺序限制,但在不连续的 token 空间里进行“硬恢复”,采样效率低且由于缺乏平滑的几何结构,难以捕获高维语义层面的变换。
Cola DLM 的核心直觉在于:生成不应该是在 token 空间里修修补补,而应是在连续语义空间里进行 Prior Transport(先验传输)。
Methodology:层次化信息分解的艺术
Cola DLM 的架构分为三步走:
- 稳定映射 (Text VAE):使用因果 VAE 将离散文本压缩入连续潜空间 。
- 先验建模 (Block-Causal DiT):在 空间,利用流匹配(Flow Matching)学习矢量场,实现从高斯噪声到语义潜变量的传输。
- 条件解码:Decoder 根据生成的潜变量 还原出最终文本。
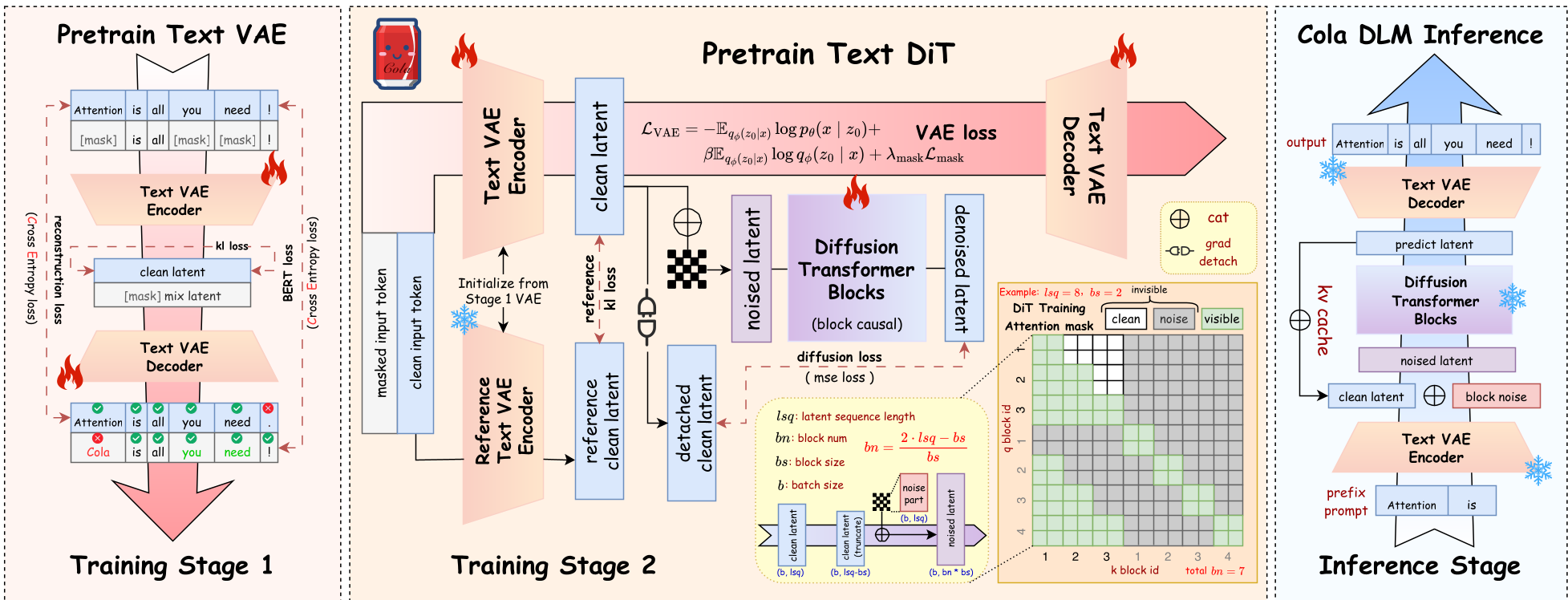
关键创新点:块因果(Block-Causal)机制
为了兼顾非自回归的并行性与长文本的逻辑连贯,作者设计了 Block-Causal 约束。这意味着:在块内(Intra-block),模型可以并行双向关注,提高效率;在块间(Inter-block),保持因果依赖,确保语义逻辑不崩塌。
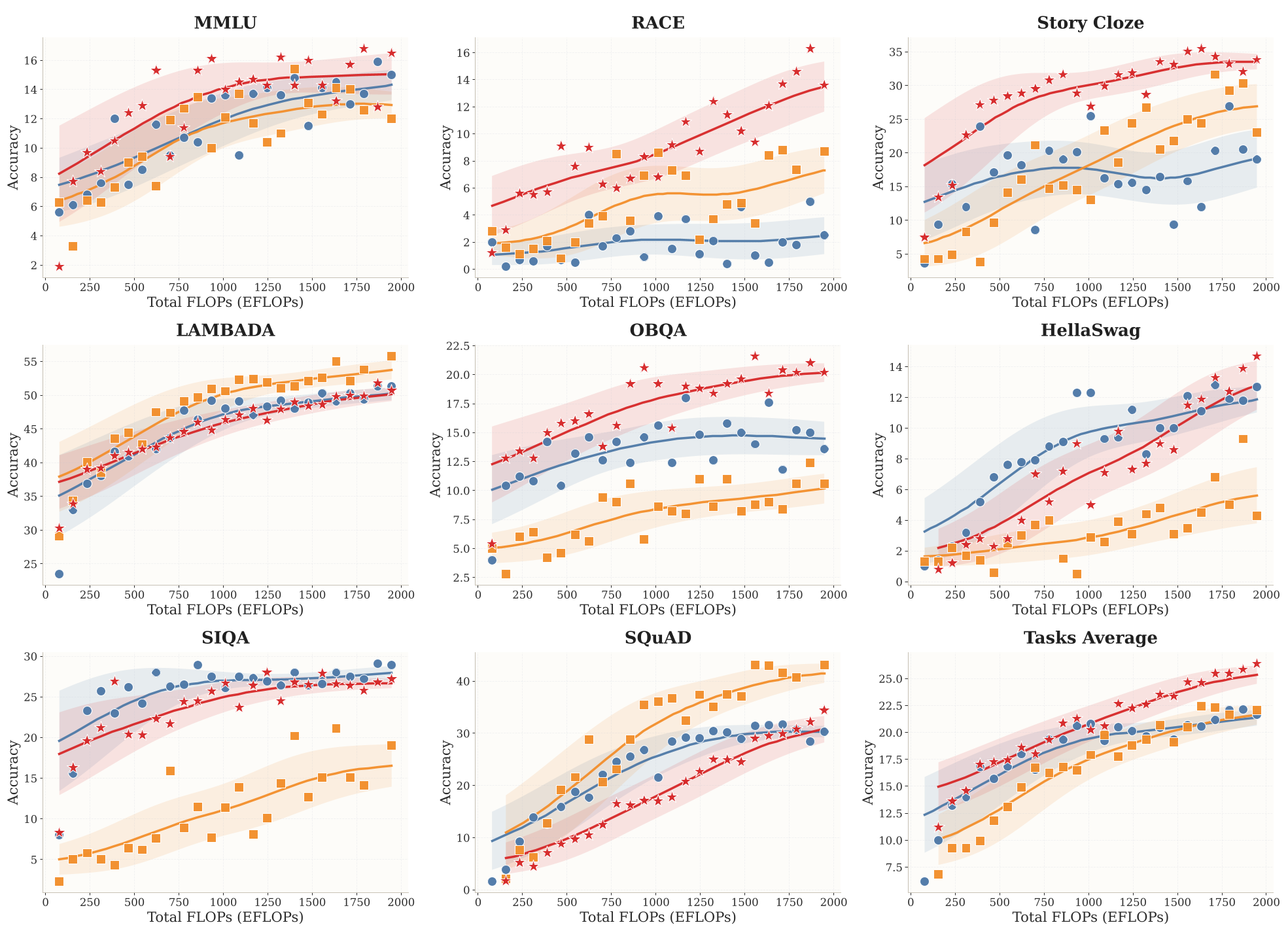
实验与结果:Scaling Law 的胜利
作者通过横跨 8 个 Benchmark 的实验,验证了 Cola DLM 的强大性能:
- 扩展性(Scaling Capacity):随着训练算力(EFLOPs)的增加,Cola DLM 的性能表现出比 AR 和 LLaDA 更持久的增长曲线。
- 推理效率:在推理时,Cola DLM 仅需 10-32 步采样即可达到 SOTA 效果。实验发现,8-10 步采样已经能够覆盖大部分性能增益,这相较于逐 token 生成的 AR 模型,极大地降低了串行操作的深度。
语义平滑性分析 (Ablation Study)
研究发现,在 VAE 训练中加入 BERT-style Masking Loss 至关重要。它能显著提升潜空间的语义平滑度(Semantic Smoothness),使模型在推理时的降噪过程更加稳健。
深度洞察:为什么 PPL 不再是唯一指标?
Cola DLM 揭示了一个有趣的现象:生成质量与困惑度(PPL)并不总是对齐的。 在连续潜变量模型中,PPL 对概率空间的局部校准(VAE logSNR)极其敏感,而人的主观生成质量更依赖于潜空间的语义连贯性。这意味着我们评价未来生成模型时,需要从“点对点匹配”转向“分布覆盖”的评估维度。
展望:迈向原生多模态统一
Cola DLM 最令人兴奋的贡献不仅在于文本,而在于其 天然的多模态兼容性。由于文本被转化为了连续潜变量,它现在可以与图像、视频的潜变量共享同一个 DiT Prior 骨架。

如图所示,由于统一了表征空间,Cola DLM 不费吹灰之力就展示了初级的 Image-to-Text (Captioning) 和 Text-to-Image 互通能力。这预示着,未来的原生多模态模型可能不再需要复杂的对齐层,而是基于同一套连续扩散 Prior 的层次化系统。
总结
Cola DLM 的出现标志着语言建模正从“ token 的炼金术”转向“潜空间的几何传输”。它不仅解决了 AR 模型的推理瓶颈,更为我们提供了一个优雅的框架,去构建真正理解世界几何规律的统一生成智能体。
Senior Tech Editor's Insight: Cola DLM 的本质是将原本由 Transformer 逐层堆叠产生的表征(Hidden States)显式化为可训练的分布传输问题。这种层次化分解(Hierarchical Decomposition)有效地降低了模型在单一离散序列上的 Inductive Bias 压力。