This paper investigates how diverse language models (Transformers, RNNs, LSTMs, and word embeddings) develop numerical representations. It identifies that while "Spectral Convergence" (Fourier spikes at periods T=2, 5, 10) is nearly universal, "Geometric Convergence" (linearly separable modular features) depends on specific alignments of data, architecture, and optimizers.
TL;DR
Just because a Large Language Model (LLM) shows "periodic structure" in how it stores numbers doesn't mean it actually understands math. This paper uncovers a fascinating "two-tiered hierarchy" in number representations: Spectral Convergence (the appearance of Fourier spikes) is easy to achieve and even exists in raw word frequencies, but Geometric Convergence (the ability to actually use those numbers for logic) requires a perfect storm of the right architecture, data signals, and tokenization.
The "Spike" Illusion: Background & Motivation
In the world of mechanistic interpretability, researchers have been excited to find that LLMs often represent numbers using periodic functions—specifically with frequencies of 2, 5, and 10. For a long time, the community assumed that if you could see a "spike" in the Fourier transform of a model's embeddings, the model had successfully learned modular arithmetic.
However, the authors of this paper noticed a glaring inconsistency: why do some models (like Transformers) "get" math, while others (like LSTMs) struggle, even when both show the same beautiful periodic spikes in their internal "brain scans"?
Methodology: The Two-Tiered Hierarchy
The researchers define two levels of representational success:
- Spectral Convergence: The model's embeddings show heavy power at specific frequencies (T=2, 5, 10) in the Fourier domain.
- Geometric Convergence: The residue classes (e.g., ) are linearly separable, meaning a simple linear probe can distinguish them.
The Mathematics of "Noise"
By applying Theorem 1 (proven in the paper using Fisher’s Linear Discriminant Analysis), they demonstrate that a Fourier spike only guarantees that the centers of number groups are dispersed. It doesn't guarantee that the groups don't overlap. In LSTMs, the "within-class noise" is so massive and so aligned with the signal that the modular information becomes trapped and unusable, despite the presence of a clear spectral spike.
 Figure: The Transformer and Gated DeltaNet show both spikes and geometric separability (high Cohen’s κ), while the LSTM and raw token distribution fail the geometric test.
Figure: The Transformer and Gated DeltaNet show both spikes and geometric separability (high Cohen’s κ), while the LSTM and raw token distribution fail the geometric test.
Why Does Geometric Convergence Happen?
Through "Structural Attribution"—a method of surgically removing parts of the training data—the authors identified the "environmental pressures" that force models to evolve these features:
- Text-Number Co-occurrence: Knowing that "5" and "15" appear in similar sentence structures.
- Cross-Number Interaction: Seeing "2 + 3 = 5" in the same window.
- The Goldilocks Logic of Tokenizers: This is a crucial insight. When we tokenize large numbers (like
123into[1, 23]), we force the model to solve "carry propagation" problems. These carry problems are essentially modular arithmetic sub-tasks (), which pressure the model to organize its geometry.
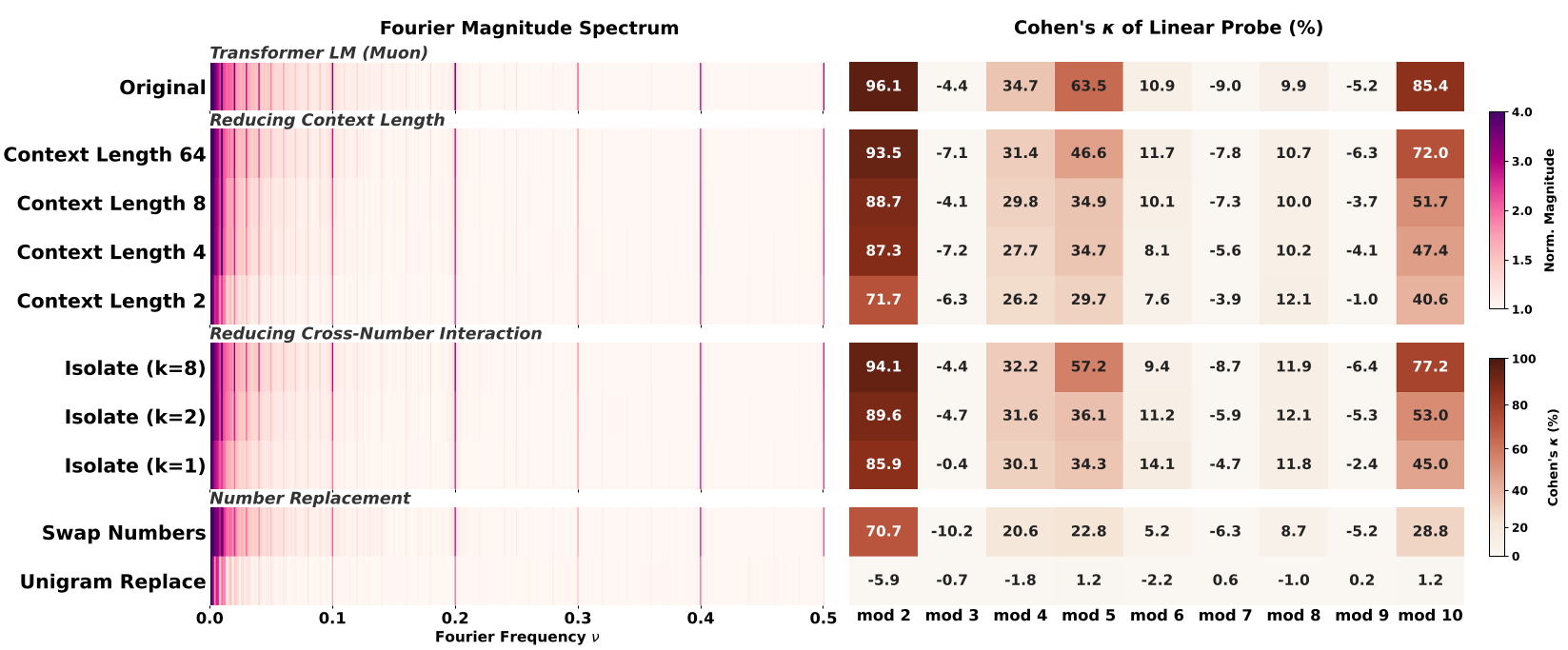 Figure: Spectral spikes (left) stay the same regardless of data changes, but geometric clarity (right) collapses when text-number associations or context lengths are restricted.
Figure: Spectral spikes (left) stay the same regardless of data changes, but geometric clarity (right) collapses when text-number associations or context lengths are restricted.
Architecture Matters: Transformers vs. LSTMs
One of the most striking findings is the failure of LSTMs. Even when trained on 10 billion tokens of the highest quality data, LSTMs failed to achieve geometric convergence. Meanwhile, Transformers and newer "Linear RNNs" (like Mamba and Gated DeltaNet) successfully aligned their internal geometry. The authors suggest this isn't a capacity issue, but an Inductive Bias issue: the way LSTMs handle recurrence might prevent them from isolating periodic signals from background noise.
Deep Insight: Convergent Evolution
The title "Convergent Evolution" refers to how different species (like octopuses and humans) both evolved eyes because they faced the same environmental pressure (light). Similarly, Transformers and Mamba models, despite being built differently, end up "evolving" the same internal number circle because they are both trying to predict the same "environment" (human language data).
Conclusion & Limitations
This work serves as a warning for AI safety and interpretability: Visualization is not Verification. We cannot assume a model "understands" a concept just because we see a pretty pattern in its embeddings.
The study primarily focuses on integers 0-999. Whether this hierarchical divergence applies to more abstract concepts—or how it scales to models with trillions of parameters—remains an open question for the next generation of AI "biologists."