本文提出了 CoVerRL,一种在无监督(Label-free)环境下通过生成器(Generator)与验证器(Verifier)协同进化来突破 LLM 推理“共识陷阱”的强化学习框架。该方法在数学推理任务上显著超越了传统的多数投票基线(TTRL),且大幅提升了模型的自验证准确率。
TL;DR
在没有标准答案(Label-free)的情况下,如何让 AI 实现自我进化?当前的 SOTA 方法通常依赖“多数投票(Majority Voting)”来生成伪标签,但这会导致模型陷入共识陷阱 (Consensus Trap):AI 会在错误的道路上反复强化,最终丧失多样性。本文提出的 CoVerRL 通过让模型同时扮演“选手(生成器)”和“裁判(验证器)”,利用验证器识别并过滤掉那些“虽然大家都认同、但逻辑全是坑”的自一致性错误,实现了 5% 左右的榜单提升。
痛点深挖:为何多数投票正变得危险?
在无监督强化学习中,由于没有 Ground-truth,研究者通常假设“如果模型多次生成同一个答案,那么这个答案大概率是对的”。然而,作者发现了一个关键的不稳定性:
- 多样性崩溃 (Diversity Collapse):在 RL 目标下,模型会趋向于预测概率最高的答案。
- 系统性错误强化:如果模型对某个问题存在思维定式(Wrong Way),它会高概率、高一致性地输出错误答案。
- 负反馈机制消失:当错误答案成为统治性的“共识”时,传统的 TTRL 等方法不仅无法修正错误,反而会奖励这些自信的谎言。
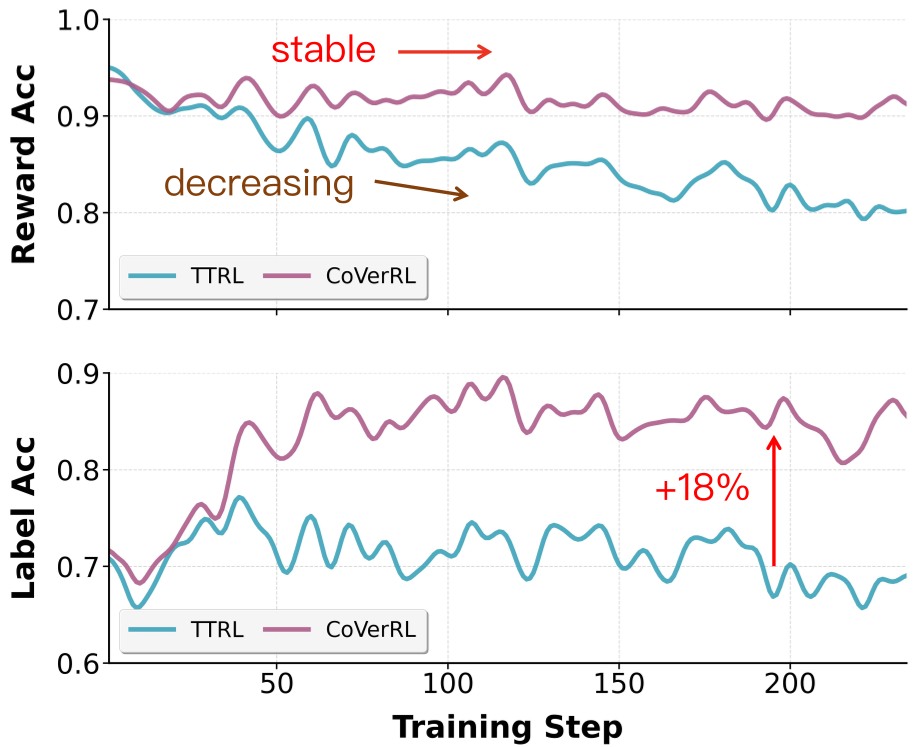 如上图所示,TTRL 随着训练进行,奖励准确率反而下降,因为它在强化错误的共识;而 CoVerRL 保持了极高的奖励质量。
如上图所示,TTRL 随着训练进行,奖励准确率反而下降,因为它在强化错误的共识;而 CoVerRL 保持了极高的奖励质量。
Methodology:CoVerRL 的协同进化逻辑
CoVerRL 处理的核心逻辑是让验证器监督伪标签的生成。
1. 流程架构
整个过程被拆解为多轮策略:
- 第一步(生成):Generator 产生 N 条路径,通过多数投票锁定一个“草稿答案”。
- 第二步(过滤):Verifier 对这些高一致性的路径进行审查。公式 (1) 规定,只有当多数验证通过时,该样本才被用于训练。这有效地剔除了由于系统误差产生的虚假共识。
- 第三步(对比学习/自纠错):利用低频答案(少数派)构建负样本,训练验证器的判别力;同时让生成器根据验证器的意见进行纠错(Self-Correction)。
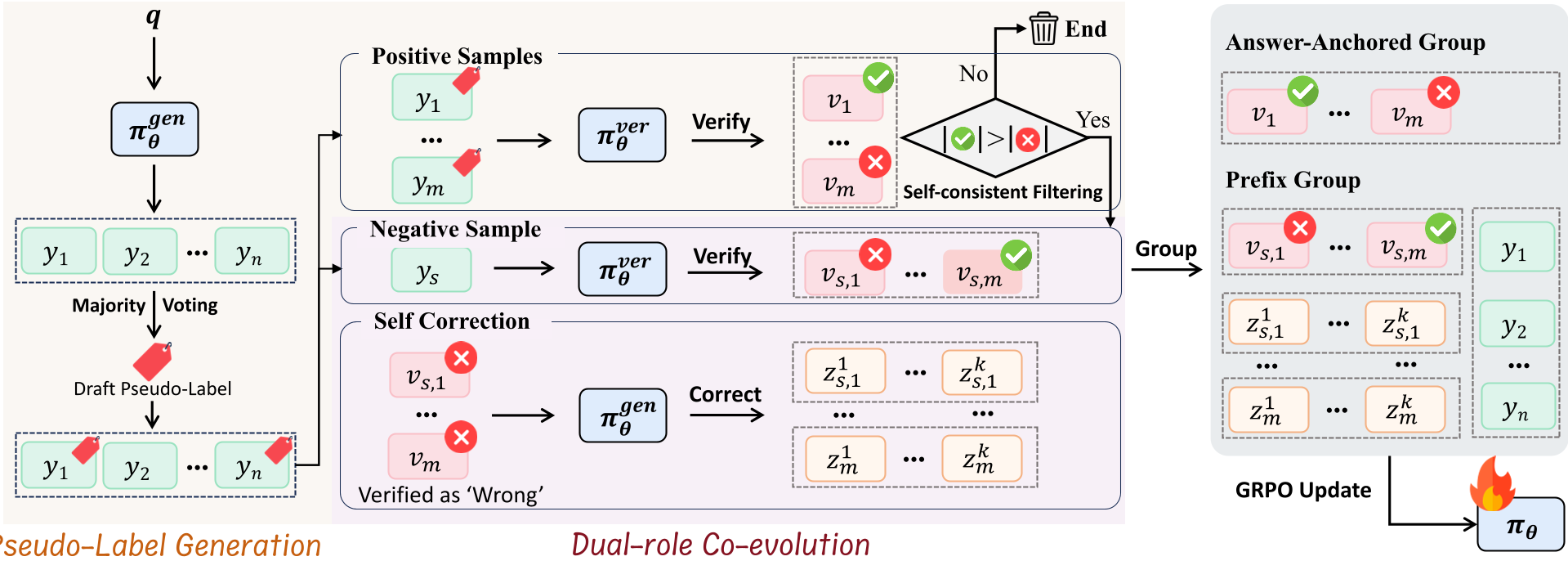 图 2 展示了生成器与验证器互助引导的闭环。
图 2 展示了生成器与验证器互助引导的闭环。
2. Answer-Anchored GRPO
为了解决多轮对话中的奖励方差问题,作者改进了 DeepSeek 提出的 GRPO。传统的 GRPO 基于前缀分组,而本文提出 Answer-Anchored GRPO:将所有指向相同伪标签答案的不同推理过程组合在一起进行优势(Advantage)计算。这种做法能更好捕捉正确推理模式的多样性。
实验与结果:验证能力的飞跃
实验在 MATH、AMC、AIME 等多个数学 benchmark 上展开。CoVerRL 在三个不同规模和家族的模型上均刷新了无监督训练的上限。
- 推理能力提升:Acc.@final 在 AMC 等任务上提升了 7-9%。
- 验证能力进化:最令人惊讶的是模型的验证准确率(Table 2)。Qwen2.5-7B 从 54.0% 增长到 86.5%。这表明模型不是在死记硬背答案,而是真的理解了如何评估一段推理过程的对错。
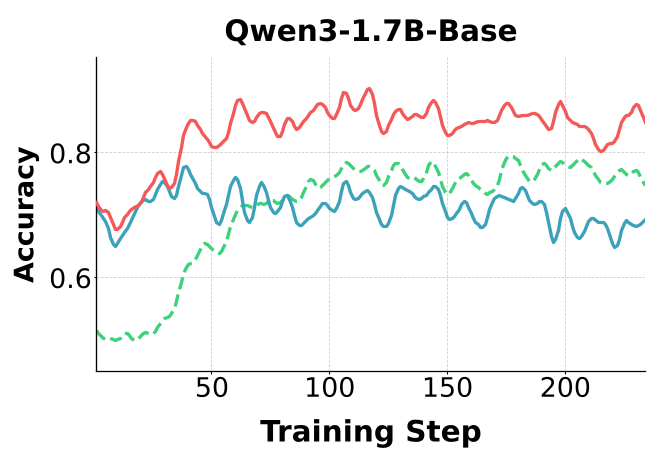 图 3 显示,验证准确率(绿虚线)的提升直接拉动了标签准确率(红线)的增长,形成良性循环。
图 3 显示,验证准确率(绿虚线)的提升直接拉动了标签准确率(红线)的增长,形成良性循环。
深度洞察:为什么验证器能不劳而获地变强?
论文在附录 C 中给出了有趣的理论证明:平衡的验证训练等价于隐式偏好优化(DPO)。 由于 CoVerRL 采取了 的样本平衡策略,这自然产生了一种“自动课程学习”效应:GRPO 的梯度会自动降低那些“容易样本(模型已确信)”的权重,转而集中攻克验证器感到困惑的边界样本( hard uncertain set)。
总结与局限
CoVerRL 证明了在没有外部人类标注的情况下,通过合理的架构设计,LLM 的生成与验证能力可以像“左脚踩右脚”一样螺旋上升。
局限性:
- 算力开销:多轮推理和验证增加了训练阶段的计算成本。
- 思维模式依赖:消融实验显示,如果模型本身不支持“Thinking Mode(思考链)”,验证器的表现会大幅缩水,甚至发生长度崩塌(Length Collapse)。
未来启示:这一范式不仅适用于数学,对于法律、医学等外部奖励昂贵且存在“虚假共识”的领域,CoVerRL 提供的协同进化思路具有巨大的产品化潜力。