本文提出了 CoVR-R,一种面向“推理优先”的组合视频检索(Composed Video Retrieval)方法。该方法利用大语言多模态模型(LMM)在 Zero-shot 设置下显式推断编辑指令背后的隐含因果和时序后效(After-effects),并发布了首个带有推理轨迹和强负样本的 benchmark。
TL;DR
在视频检索的世界里,搜“把这头牛变成马”很简单,但搜“由于变成了马,原本平静的草地应该变得尘土飞扬”却极难。传统的组合视频检索(CoVR)方法往往只盯着文字表面。CoVR-R 提出了一个全新的范式:在检索之前,先让模型“想一想”这个改动会引发哪些连锁反应(After-effects)。 凭借其独特的推理链条,该方法在不进行任何任务特定微调的情况下,大幅刷新了 SOTA 战绩。
痛点深挖:消失的“后效”
目前的组合视频检索(Reference Video + Edit Text → Target Video)大多将其视为关键词匹配。例如,指令是“给这个厨师一个近景”,传统模型可能只会寻找带有“近景”标签的视频。
然而,真实的视觉编辑具有动力学关联:
- 动作相位演变:指令是“切完菜后”,隐含的视觉结果应该是“菜在锅里”。
- 状态转移:指令是“煎牛排”,隐含的视觉特征是“冒烟”和“红肉变褐”。
- 电影感契合:特定的动作往往伴随着特定的镜头推拉(Zoom/Pan)。
由于现有的数据集(如 WebVid-CoVR)极其简陋,导致模型学会了偷懒——只看文本,不理逻辑。
核心机制:Reason-then-Retrieve (先推理,再检索)
作者的核心直觉是:利用通用大模型(LMM)的常识推理能力,补全编辑指令中“没说出口”的部分。
1. 结构化“后效”预测
论文使用 Qwen3-VL 作为推理引擎,针对每一个 (Video, Edit) 对,生成五个维度的结构化记录:
- States (状态):物体表面、颜色的变化(如:从生到熟)。
- Actions (动作):细微动作的转换(如:从打字到合上电脑)。
- Scene (场景):背景、环境、天气的隐含改变。
- Camera (相机):镜头尺度、平移、缩放的变化。
- Tempo (节奏):动作快慢的演变。
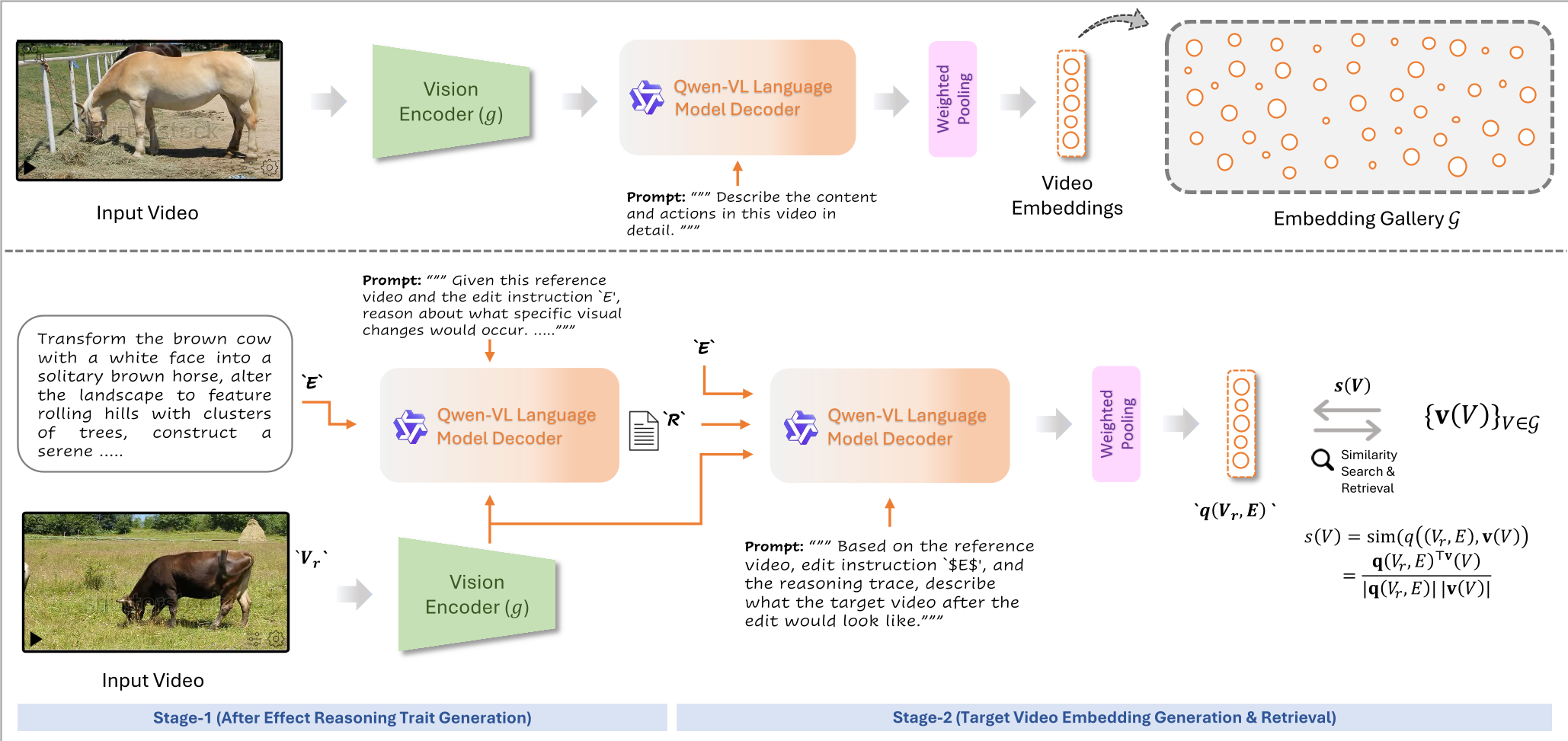
2. 重要性加权池化 (Importance Weighted Pooling)
不同于传统的 Mean Pooling 将所有文本词等同看待,CoVR-R 引入了词法权重:
- 高权重:动作动词、名词对象、描述性状态词。
- 低权重:冠词、介词等功能性词。 这种设计确保了检索向量被核心“视觉效应词”主导,而非噪音。
实验战绩
为了验证这种推理能力,作者构建了 CoVR-R Benchmark,特点是在负样本(Distractors)中加入了极具迷惑性的选项(例如物体一样但动作相位相反)。
- 性能暴涨:在 CoVR-R 榜单上,Recall@1 达到了 49.88%,比传统 CA 融合方案(37.9%)高出整整一大截。
- 无需微调:这是一个纯粹的 Zero-shot 方案,证明了 Foundation Model 的推理能力在垂直领域的普适价值。

深度洞察:推理真的是越多越好吗?
在 Ablation Study 中,作者发现了一个有趣的现象:适度的推理(Standard, 89 tokens)效果最好,而过于冗长(Verbose, 186 tokens)的推理反而会导致性能下降。
- 噪声干扰:过细的描述会引入模型主观臆断的细节(Hallucination),这些细节可能在真实的目标视频中并不存在,导致检索向量发生偏移。
- 效率权衡:推理流程会增加推理延迟。论文提出的单次结构化 Prompt 方案在效果和速度间找到了最佳平衡点。
总结与局限
CoVR-R 成效显著,它标志着组合检索从“特征对齐”阶段跨入了“常识驱动”阶段。
它的局限性: 对于过于琐碎、甚至具有破坏性的指令(比如要把视频里五个不相关的物体全部换掉),推理链路可能会在高维描述中迷路,导致 Top-1 匹配失败。
未来启示: 视频搜索不再是冷冰冰的向量检索,未来的搜索系统将更像是一个“导演助手”,它不仅理解你说了什么,更理解你想要的画面背后必然会发生什么。