本文推出了 CT Open,这是一个专为临床试验结果预测(Clinical Trial Outcome Prediction)设计的开源动态评测平台。该平台通过每季度自动更新的、经过专家验证且具备抗污染(Decontamination)机制的基准测试(Benchmark),评估 AI 系统在真实世界高风险事件发生前的预见能力。
TL;DR
临床试验结果预测是医疗领域的“圣杯”,不仅风险极高且数据由于极度碎片化而难以处理。加州大学圣迭戈分校(UCSD)等机构的研究人员推出了 CT Open:一个每季度更新的动态评测平台,专门用来考研 AI 是否能在结果公开前准确预言临床试验的生死。实验发现,即便是如 o3-mini 和 Claude 4.5 这样的顶级模型,面对这种超高难度的推理任务时,也未必能稳赢传统的机器学习基线。
痛点深挖:为什么 AI 预测临床试验这么难?
在学术界,预测未来一直被视为检验通用人工智能(AGI)成熟度的最高标准。临床试验不仅关乎数亿美元的投资,更关乎患者的生命。
目前的研究面临两大核心障碍:
- 静态数据集的陷阱:一旦数据发布,LLM 的预训练数据很快就会包含这些答案。模型得分高,往往是因为它“背过题”,而不是因为它懂推理。
- “信息污染”的隐蔽性:一个试验的结果可能先出现在某个医学顶会的 Poster 上,或者出现在某家药企的财务报表中,而非官方注册网站。要确保模型在预测时完全没接触过这些“剧透”极其困难。
Methodology:CT Open 的抗污染防御塔
为了解决上述问题,CT Open 构建了一套极为严苛的自动抗污染流水线(Decontamination Pipeline)。
1. 动态时间戳隔离
CT Open 并不提供一份一成不变的试卷,而是每三个月发布一次挑战。它只选取那些在预测截止日期(Cutoff Date)之后才公开结果的项目。
2. 双重 LLM 验证搜索
系统不仅使用关键词搜索。它调用了 GPT-5 和 Gemini 的 Web 搜索能力,配合 Agent 进行多轮检索:
- Round 1 (Matching):验证搜到的文档是否真的属于该试验(通过 NCT ID、入排标准、赞助商等多维比对)。
- Round 2 (Verification):判定文档是报告了结果(Result),还是仅仅提到了试验启动。
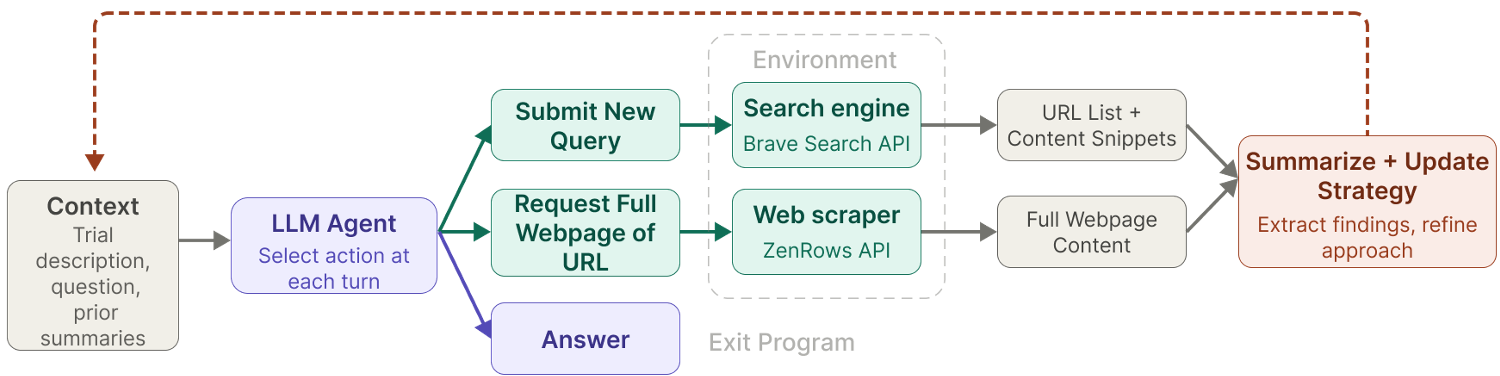 图注:Agentic LLM 的搜索与浏览工作流,展示了模型如何自主决定搜索策略并提取关键结论。
图注:Agentic LLM 的搜索与浏览工作流,展示了模型如何自主决定搜索策略并提取关键结论。
实验结果:大模型真的比传统 ML 强吗?
研究人员对比了多种方案:纯 Prompt LLM、RAG(搜索类似的历史试验)、智能体(Agentic)搜索,以及传统的随机森林(RF)和神经网络。
关键发现:
- 传统模型的韧性:在 Summer 2025 基准上,传统的 Feed-Forward NN 在某些指标上甚至优于 o3-mini(见下表)。这说明对于结构化数据(如试验相位、样本量),传统模型抓取相关性的能力依然极强。
- RAG 的双刃剑:引入类似试验的历史数据通常能提升 2-5% 的性能,但如果模型无法理解当前试验与历史试验在“给药剂量”或“患者群体”上的微妙差异,反而会产生误导。
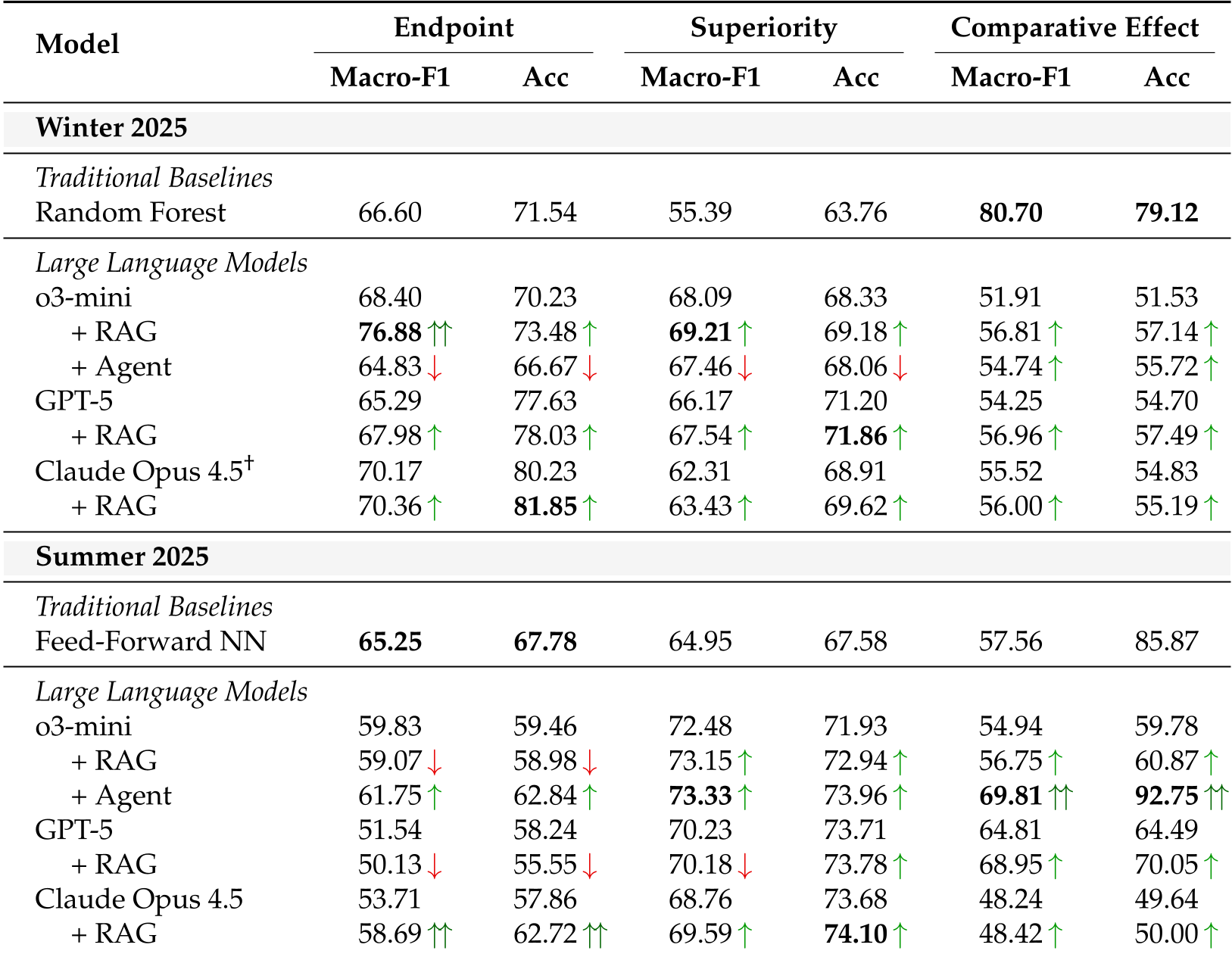 图注:不同模型在 Winter/Summer 2025 基准上的战绩,可见 RAG 和 Agent 的引入对性能的复杂影响。
图注:不同模型在 Winter/Summer 2025 基准上的战绩,可见 RAG 和 Agent 的引入对性能的复杂影响。
深度洞察:我们学到了什么?
- 数据污染是真实存在的:研究发现,当测试集的时间戳早于模型的知识截止日期时,模型表现往往会虚高。这警示我们,任何针对 LLM 的医学评估必须是动态且有时间戳保护的。
- Agentic 推理成本极高:在文中提到,使用 o3-mini 运行 Agent 工作流完成一次测评的 Token 成本竟然高达 1000 美元以上,且效果并非次次拔群。这说明如何让 Agent 进行“高效、低成本”的专业调研任务仍是一个未解之题。
- 预测比理解更难:AI 擅长解释已有的事,但要在信息不全(试验进行中)的情况下模拟药效动力学、统计功效和临床异质性,AI 还有很长的路要走。
总结
CT Open 不仅仅是一个测试集,它代表了学术界对 AI 评测公平性的一次深刻反思。对于制药企业、临床医生和 AI 研究者来说,这个平台提供了一个最真实的战场。未来,也许真正能拯救生命的 AI,就在这些动态刷新的排行榜中诞生。
局限性:目前该平台主要依赖于公开搜索到的非结构化文本,如果某些临床细节从未在网上公开,AI 的推理链条将出现断层。
未来展望:CT Open 正接受 Summer 2026 的预测提交,邀请全球研究者共同冲击这个医学预测的极限。