CUBE (Common Unified Benchmark Environments) is a universal protocol standard designed to unify the fragmented landscape of AI agent evaluation. By integrating the Model Context Protocol (MCP) and Gymnasium interfaces, it allows benchmarks to be "wrapped once and used everywhere" across diverse training and evaluation platforms.
Executive Summary
TL;DR: CUBE (Common Unified Benchmark Environments) is a newly proposed open standard that unifies how AI agent benchmarks are packaged, discovered, and executed. By bridging the gap between the Model Context Protocol (MCP) and Gymnasium, CUBE allows developers to wrap a benchmark once and instantly run it across any evaluation or RL training platform.
Background Positioning: This is a high-impact infrastructure and standards proposal co-authored by a massive consortium (ServiceNow, IBM, MILA, CMU, UC Berkeley, etc.). It aims to resolve the fragmentation in the agentic AI ecosystem before the projected explosion of agent benchmarks in 2026.
The "Integration Tax": Why Research is Stalling
Currently, there are over 300 benchmarks for AI agents (e.g., SWE-Bench, WebArena, OSWorld). However, each one comes with a different "flavor" of infrastructure:
- WebArena requires a persistent "micro-internet" of VMs.
- SWE-Bench depends on ephemeral Docker containers for coding.
- OSWorld demands heavy RAM snapshots for desktop GUI states.
The result? Researchers act more like Systems Engineers than AI Scientists. Integrating five benchmarks into a training pipeline often requires five unique, complex drivers. This "N-to-M" mapping problem is what the authors call the Integration Tax.
Methodology: The Four Layers of CUBE
CUBE doesn't just provide a wrapper; it defines a rigorous four-layer API contract to decouple environment logic from execution infrastructure.
1. Task Level (The Interface)
CUBE solves the "Async Problem." Standard RL (Gym) is blocking, but web agents need to perform asynchronous tool calls (e.g., searching the web while planning). CUBE fuses MCP (asynchronous tool execution) with Gym (reward/reset semantics).
2. Benchmark Level (The Orchestrator)
This layer manages shared resources. For example, if ten agents are testing on a "Social Media" benchmark, CUBE manages the single persistent server that all task instances talk to.
3. Package Level (The Provider)
It separates What (Resource requirements like "I need 8GB RAM") from How (Provisioning via Docker, Slurm, or Cloud VMs). This allows a benchmark to move from a local laptop to a massive HPC cluster with zero code changes.
4. Registry Level (The Discovery)
A centralized, lightweight catalog that indexes metadata, hardware requirements, and licenses, making new benchmarks discoverable without manual literature searches.
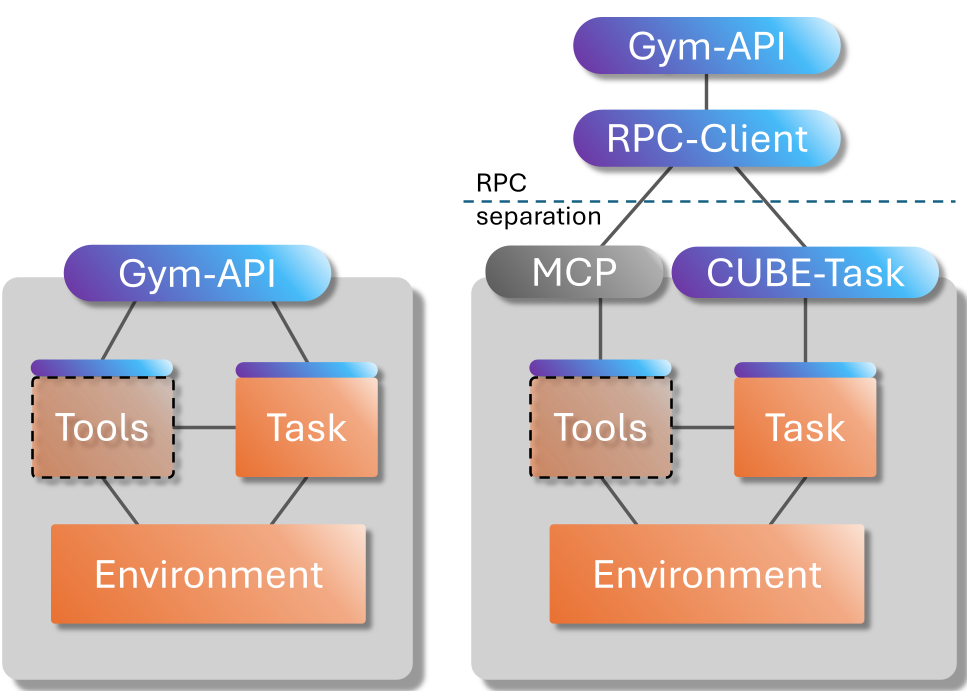 Figure 1: Task-level diagram showing the separation between tasks and tools, and the dual Python/RPC interface support.
Figure 1: Task-level diagram showing the separation between tasks and tools, and the dual Python/RPC interface support.
Comparing the Landscape
CUBE isn't competing with platforms like NVIDIA NeMo Gym or Meta's OpenEnv; it is the "glue" that makes them better.
| Feature | CUBE | NeMo Gym | AgentBeats | |:---|:---|:---|:---| | Primary Focus | Protocol Standard | Scaling RL Training | Evaluation Orchestration | | Design Goal | "Wrap Once, Use Anywhere" | High-performance rollouts | Judge-based Assessment | | Interface | MCP + Gym | OpenAI Tool Spec | A2A Protocol |
 The table above highlights the diverse infrastructure needs—from VM-based simulated webs to static file sets—that CUBE seeks to unify.
The table above highlights the diverse infrastructure needs—from VM-based simulated webs to static file sets—that CUBE seeks to unify.
Critical Analysis & Conclusion
Takeaway
CUBE is the "TCP/IP" moment for AI agents. By standardizing the communication layer, it enables multi-benchmarking at scale, which is the only way to verify if an agent is truly a "generalist" or just overfitting to a specific environment like SWE-Bench.
Limitations
- Adoption Deadlock: Standards only work if everyone uses them. The authors are fighting a two-sided battle to get both benchmark creators and platform owners (NVIDIA, Meta, Hugging Face) on board.
- Complexity Overhead: For very simple, static benchmarks, the four-layer CUBE abstraction might feel like "over-engineering."
Future Outlook
As we head into 2026, the industry is moving toward Post-training and RL on thousands of diverse tasks. CUBE provides the necessary plumbing to make this data-hungry transition possible. If successful, it will democratize agent research, allowing smaller labs to evaluate their models against the same diverse environments used by industry giants.