本文提出了 D-OPSD,一种针对步进蒸馏(Step-distilled)少步扩散模型的在线策略自蒸馏(On-Policy Self-Distillation)微调框架。通过利用现代扩散模型中 LLM/VLM 编码器的上下文学习能力,该方法在不引入外部奖励函数的情况下,实现了 SOTA 级的新概念学习与风格迁移。
TL;DR
随着极速影像生成技术(如 FLUX.2-klein 和 Z-Image-Turbo)的普及,如何对这些“少步(Few-shot)模型”进行二次微调而不破坏其原有的生成质量成了业界难题。D-OPSD 提出了一种全新的在线策略自蒸馏方案。它巧妙地利用了模型自带的多模态 In-context 能力,让模型通过“自己教自己”的方式学习新概念,完美解决了传统 SFT 微调导致的画质崩塌问题。
背景:为什么你的少步模型一调就“糊”?
在多步扩散模型(如 SDXL)时代,微调只需遵循 Flow-matching 或噪声预测目标即可。但在步进蒸馏(Step-distillation)模型中,生成路径被极度压缩(通常仅 1-8 步)。
核心动机: 传统的 SFT 是典型的 Off-policy(离线策略):它强迫模型去拟合一张外部图像的噪声状态,而这些状态在模型实际进行 4 步或 8 步推理时根本不会跳过。这种训练与推理的分布不一致(Train-test Mismatch),会导致模型学到了新样式,却弄丢了原有的高质量采样轨迹,结果就是生成的图像变模糊、出现伪影。
核心方案:D-OPSD 的“角色扮演”机制
D-OPSD 的灵感来源于 LLM 领域的自蒸馏。它不再把目标图像当作死板的“标签”,而是当作一个“参考上下文”。
1. 发现新大陆:扩散模型的 In-context 能力
作者发现,现代扩散模型由于使用了像 Qwen 这样的强大 LLM/VLM 作为编码器,它们天然具备 In-context 属性。仅需在 Prompt 中加入图像特征,模型即便不训练也能生成极其相似的变体。
2. 构建师生博弈
在训练迭代中,模型被赋予两个角色:
- 学生(Student):仅输入文本 Prompt,按照正常的采样轨迹走。
- 老师(Teacher):输入文本 + 目标图像的多模态特征,提供更强的“先验指导”。
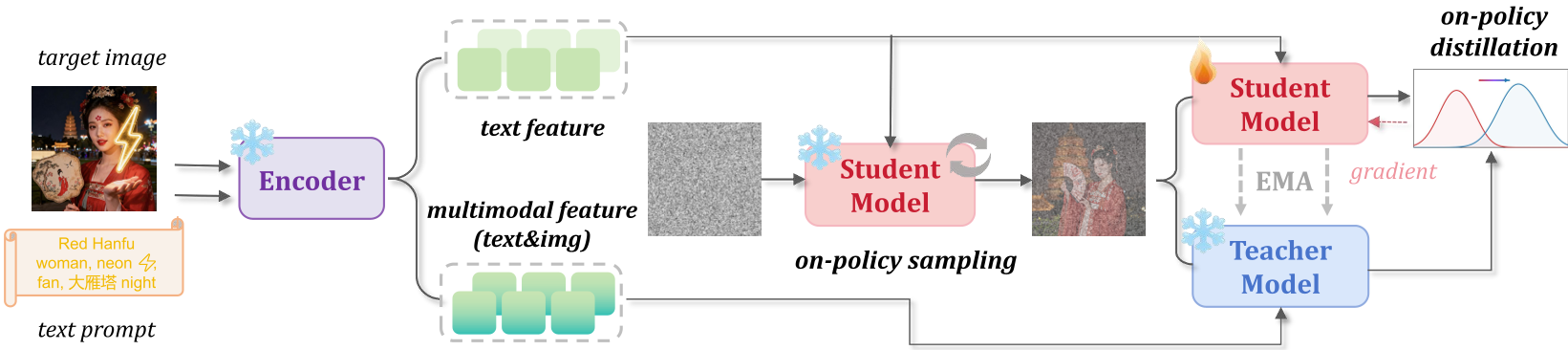
训练的目标极其优雅:让学生模型在自己走出的路径上,去预测老师模型看到的“正确速度(Velocity)”。这就保证了模型是在自己的采样分布内进行优化。
实验与战绩:画质、速度、知识全都要
研究团队在 Z-Image-Turbo 和 FLUX.2-klein 两个重量级基座上验证了效果。
- LoRA 任务:在 DreamBooth 数据集上,D-OPSD 不仅准确捕捉了特定物体的特征,其生成的图像在审美得分(Aesthetic Score)上远超传统 SFT。
- 全量微调任务:在 2.5 万张高质量动画数据上的测试显示,D-OPSD 将 FID 降低了 50% 以上,同时能够保持对原始域(如现实风格)的记忆,避免了灾难性遗忘。

从视觉对比图中可以清晰看到:SFT 和 PSO 方法在微调后图像明显模糊且细节丢失,而 D-OPSD 保持了极其锐利的画质和准确的细节。
深度洞察:为什么 D-OPSD 具有里程碑意义?
- 脱离奖励模型依赖:以往的 Online-RL 微调(如 GRPO)需要极其精准的 Reward Model(奖励模型),这对普通开发者来说门槛太高。D-OPSD 通过 Teacher 的多模态先验,提供了一种“隐式奖励”。
- 训练即推理:模型在训练中怎么生成的,推理时还是怎么生成的。这种一致性是少步模型保持高性能的生命线。
局限性与未来
虽然 D-OPSD 效果惊人,但其训练时的计算量约是 SFT 的两倍(因为需要同时跑师生两路推理)。此外,它高度依赖基座模型的编码器质量——如果编码器本身理解不了图文关系,自蒸馏也就无从谈起。
总结
D-OPSD 为蒸馏扩散模型的“终身学习”指明了方向。它告诉我们,要调教一个极速生成的 AI 模型,最好的导师不是外部的标注,而是它自己在更高信息量限制下的“潜能”。
