The paper introduces DA-VAE (Detail-Aligned VAE), a plug-in latent compression method that increases the compression ratio of pretrained Diffusion Transformers (DiTs). By expanding the latent channel dimension instead of reducing spatial tokens, it enables high-resolution image generation (e.g., 1024px) using the token budget of a lower resolution (e.g., 512px) with minimal retraining.
TL;DR
High-resolution image generation usually comes with a massive computational tax because Transformer complexity grows quadratically with the number of tokens. DA-VAE changes the game by keeping the token count constant while increasing the information density per token. By adding "Detail Channels" to a pretrained VAE and aligning them with the original latent structure, the authors enabled Stable Diffusion 3.5 to generate 1024px images with the cost of 512px images, achieving a 4x speedup with just 5 days of H100 training.
Problem & Motivation: The Token Bottleneck
In the world of Latent Diffusion Models (LDMs), the VAE usually compresses an image by a factor of $f=8$ or $f=16$. If you want to double the resolution, you quadruple the tokens. For a DiT (Diffusion Transformer), this means the self-attention cost jumps by 16x.
While there are "high-compression" tokenizers like DC-AE that aim for $f=32$ or higher, they usually suffer from two issues:
- Lack of Structure: High-dimensional latent spaces often look like "noise" to the diffusion model, making training unstable.
- Cold Start: You can't use your expensive pretrained weights (like SD3.5 or Flux); you have to train from zero.
The authors' insight? Don't change the number of tokens; change what's inside them.
Methodology: The Core of DA-VAE
1. Structured Latent Space
Instead of a "black box" encoder, DA-VAE splits the latent code into a Base Branch and a Detail Branch.
- Base ($z$): Uses the exact same weights as the pretrained VAE to capture global layout.
- Detail ($z_d$): A new set of channels specifically for high-frequency textures that only appear at high resolutions.
2. Detail Alignment (The "Secret Sauce")
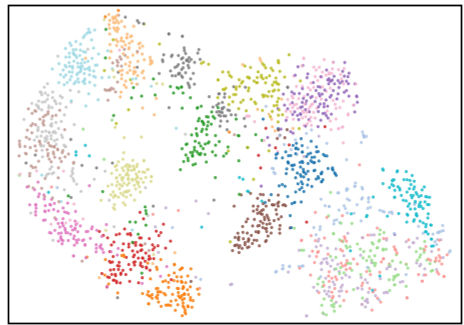
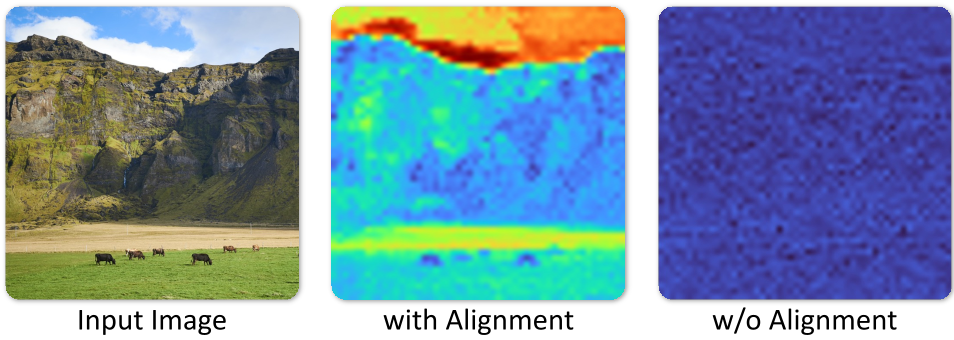
To prevent the $z_d$ channels from becoming "noisy residuals" that the DiT can't understand, the authors introduce a Latent Alignment Loss. It forces the new detail channels to follow the same spatial/semantic structure as the original base channels. As shown in the t-SNE visualizations below, skipping this step results in a chaotic latent space that breaks the diffusion process.
3. The Warm-Start Recipe
How do you inject new channels into a pretrained DiT?
- Zero-Init: The new patch embedders for the $D$ channels are initialized to zero. At Step 0, the model is mathematically identical to the original 512px model.
- Gradual Scheduling: A cosine-annealed weight is applied to the loss of the detail channels. Early in training, the model focuses on maintaining its original capability; as training progresses, it's "forced" to learn the new details.
Experiments & Results: Efficiency Gains
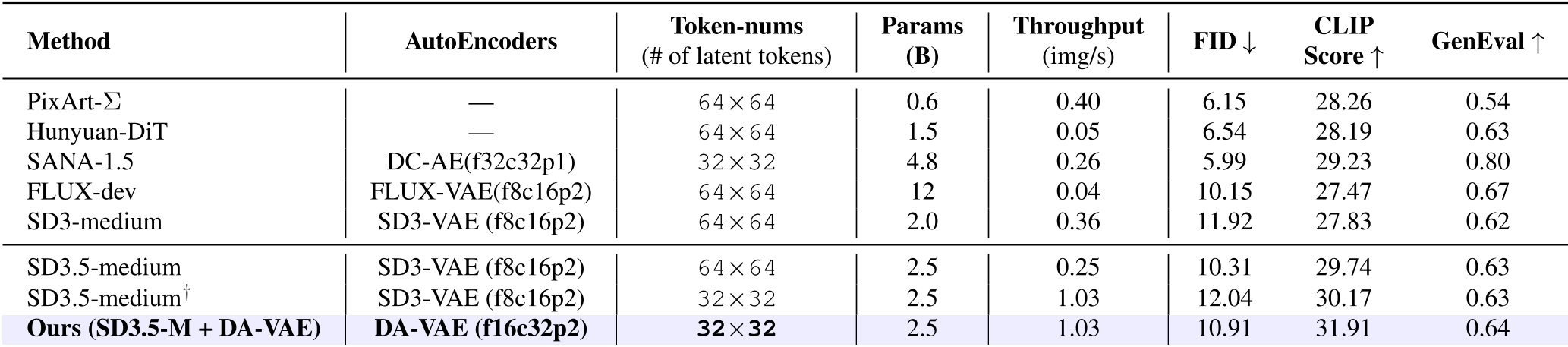
The results on Stable Diffusion 3.5 Medium are particularly striking. By adapting the model to use DA-VAE, researchers could generate 1024x1024 images using only 32x32 tokens (the standard for 512px).
- Throughput: 1.03 img/s (Ours) vs 0.25 img/s (Original SD3.5-M at 1K).
- Convergence: Achieved SOTA-level generation in just 20k steps.
- Extreme Scaling: It successfully unlocked 2048x2048 generation, maintaining global coherence where the base model usually repeats patterns or collapses.
Critical Analysis & Conclusion
Takeaway
DA-VAE proves that we don't need to reinvent the wheel (or the backbone) to move to higher resolutions. By treating "detail" as extra channel dimensions and enforcing structural alignment, any pretrained diffusion model can be upgraded into a high-resolution powerhouse with a modest compute budget.
Limitations
The authors acknowledge that the method was tested primarily on synthetic data for fine-tuning, which might explain why their 1K results are slightly less "photorealistic" than native 1K models in some cases. Additionally, while 5 H100-days is cheap, it's still not "free."
Future Outlook
This "plug-in" philosophy is likely the future of model iteration. Rather than the $10,000,000 training runs for every new resolution, modular updates like DA-VAE will allow the community to stack improvements on top of foundational giants like Flux or SD3.5.