本文提出了 DA-VAE,一种通过细节对齐(Detail Alignment)实现 Diffusion 模型潜空间(Latent Space)插件式压缩的方法。该方法在保持 Token 数量不变的情况下,通过扩展通道维度实现了 2 倍分辨率提升,在 SD3.5 上仅需 5 个 H100-days 的微调即可实现 4 倍推理加速并支持 2K 图像生成。
TL;DR
在生成式 AI 领域,高分辨率(如 1024px 或 2048px)的计算开销一直是痛点。传统的做法是重新训练一个超高压缩比的 VAE,但这意味着昂贵的 Diffusion 训练也要推倒重来。DA-VAE (Detail-Aligned VAE) 提供了一种天才的“插件式”方案:通过在原有 VAE 潜空间上“嫁接”细节通道,并利用**细节对齐(Detail Alignment)**技术,仅需极小算力(5 个 H100-days)即可让现有模型(如 SD3.5)在 Token 数量不变的前提下,生成分辨率翻倍的图像,推理速度提升 400%。
痛点深挖:为何高压缩比 VAE 难以训练?
目前大多数 LDM(潜扩散模型)使用 8 倍下采样。若要生成 1024px 图像,Token 数量会激增,导致 Self-Attention 计算量爆炸。
- 重训代价高:一旦改变 VAE 架构,预训练的 Diffusion 权重全部失效。
- 潜空间丧失结构:为了补偿空间压缩,开发者会增加通道数(C)。但如果没有特殊约束,新增的通道往往会学习一些杂乱的噪声(Residuals),导致 Diffusion 模型在这些“无意义”的维度上难以收敛。
核心方法:DA-VAE 的显式结构化设计
1. 结构化潜空间 (Structured Latent)
作者并没有改变图像的 Token 布局,而是将潜空间拆分为:
- Base Channels (C):完全复用原有的预训练 VAE 通道,负责全局结构。
- Detail Channels (D):新增通道,专门负责捕获高分辨率下的细微纹理。
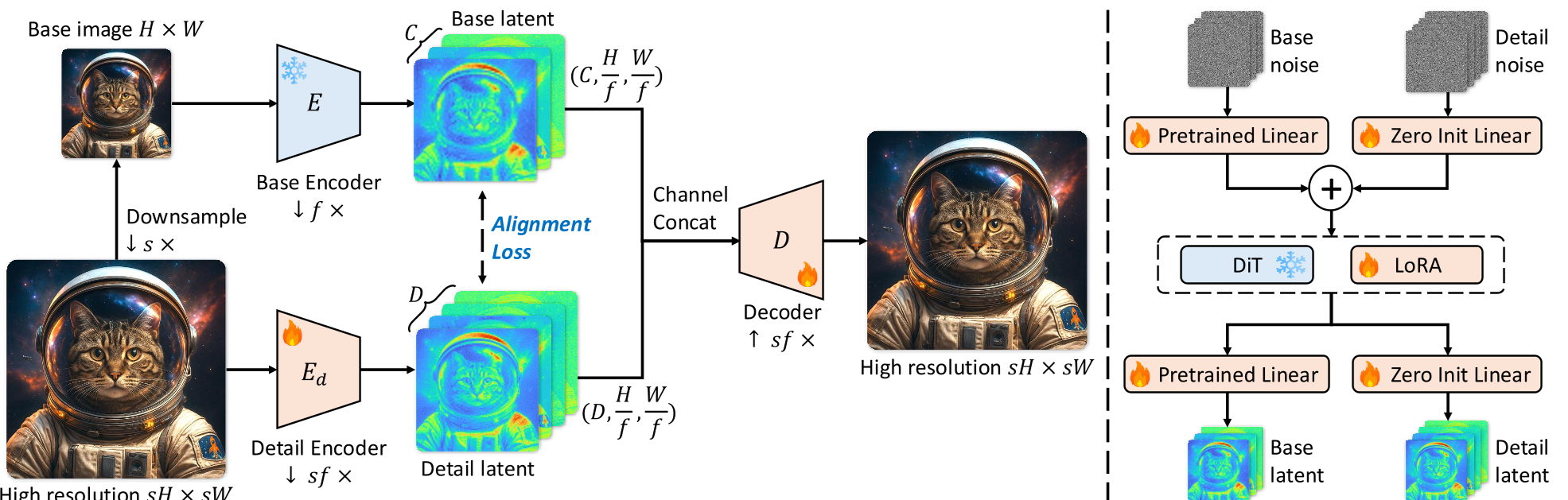
2. 细节对齐 (Detail Alignment) —— 论文的神来之笔
为了防止细节通道 zd 变成“废维度”,作者引入了一个简单的对齐损失: 通过这种方式,强制细节通道的激活模式在语义上向基础通道对齐。实验证明,这种 Inductive Bias 极大地降低了 Diffusion 的微调难度。
3. 微调黑科技:Zero-init 与 Gradual Scheduling
为了实现“热启动”,作者对新增的 Patch Embedder 进行了 零初始化。这意味着在微调开始瞬间,模型完全退化为原有的预训练状态,随后通过一个 Cosine 调度的 Loss 权重,慢慢让模型感知并学习新增的细节通道。
实验与结果:性能与效率的双重飞跃
SOTA 对比
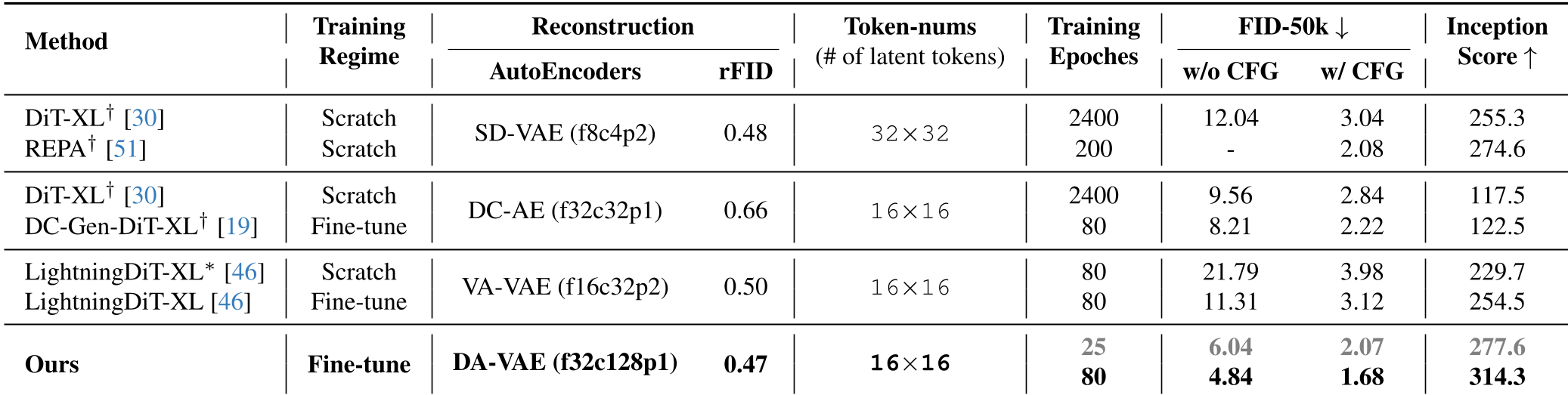
在 ImageNet 512x512 任务上,DA-VAE 在相同的 Token 预算(16x16)下,FID 表现远超 DC-AE 和原来的 VA-VAE 基线。
真实性能评估 (SD3.5 Medium)
- 推理加速:在 1024px 下,吞吐量从 0.25 img/s 飙升至 1.03 img/s。
- 2K 挑战:原生 SD3.5 在 2048px 下经常出现布局崩溃(Layout Collapse),而搭载 DA-VAE 的版本能够完美保持全局结构。

深度洞察:为什么不直接用超分 (SR)?
论文在补充材料里给出了非常有力的回答:
- 全局连贯性:超分模型只能修补局部纹理,无法修正低分辨率模型在生成时就搞错的物体数量。
- 单次推理:SR 需要两步走,而 DA-VAE 是端到端单次生成,推理延迟(Latency)优势极大。
总结与局限
Takeaway: DA-VAE 为大模型时代的“降本增效”提供了一条极具启发性的路径:与其重塑轮子,不如在原有的结构上进行对齐扩展。
局限性: 目前主要在 SD3.5 这种 DiT 架构上验证,且依赖于合成数据进行微调,这可能会在一定程度上影响图像的真实感(Photorealism)。未来的研究可以尝试在更庞大的实时数据集上进行全量微调。