本文提出了名为 Megadocs 的预训练数据增强框架,通过将同一原始文档的多个合成变体(如 Rephrase 或 Latent Thoughts)组合成超长文档,显著提升了语言模型的预训练效率。在 300M 参数模型的实验中,该方法实现了高达 1.80 倍的数据效率提升,并在长文本建模和下游任务中打破了常规合成数据的性能瓶颈。
TL;DR
面对互联网文本即将被模型“吃光”的困局,斯坦福大学团队提出了一种全新的合成数据利用范式:Megadocs。他们发现,与其将模型生成的重述内容(Rephrasing)打散作为独立样本,不如将它们与原件“缝合”成超长文档。这种方法不仅将预训练的数据效率提升了 80%,更在长文本处理能力上实现了跨越式进步。
背景定位:当计算量不再是瓶颈,数据才是
在传统的 Scaling Laws 中,我们习惯于增加 Compute。但在“数据荒”时代,如何压榨有限真实数据的价值成了核心挑战。本文定位在 Data-constrained Pre-training 坐标系中,探讨如何设计合成数据算法,使其在计算量趋于无穷大时,依然能让 Loss 持续下降。
痛点深挖:合成数据的“增益消失”之谜
目前主流的方法(如 WRAP)是将网页内容重述后加入训练集。然而,作者观察到一个现象:
- 独立性偏见:简单的重述将同一来源的 G 个副本视为完全无关的文档,浪费了跨文档的关联信息。
- 过拟合风险:当每个真实文档对应的合成副本增加时,性能提升很快会遇到“平台期”。
- 缺乏深度:单一的重述只是改变了表述,没有增加逻辑深度。
核心方法论:从短篇到 Megadoc 的演变
作者提出了两种构建“超长巨文档”(Megadocs)的策略:
1. Stitched Rephrasing (缝合重述)
受 In-context Pre-training (ICPT) 启发,作者将同一原始文档生成的 N 个重述版本按顺序拼接。
- 关键发现:将“原始真实文档”放在序列的最后效果最好。作者认为这涉及到 Epiplexity(学习复杂度),模型通过理解弱质的合成数据后,再去预测高质的真实原件,能学到更普适的特征。
2. Latent Thoughts (潜意识拉伸)
这种方法更具侵略性。它将原始文档切开,在裂缝中插入模型生成的 Rationale(推理逻辑),解释为什么上一段话会引出下一段。
- 效果:这种“拉伸”不仅增加了 Token 数量,更重要的是引入了合成的逻辑链。
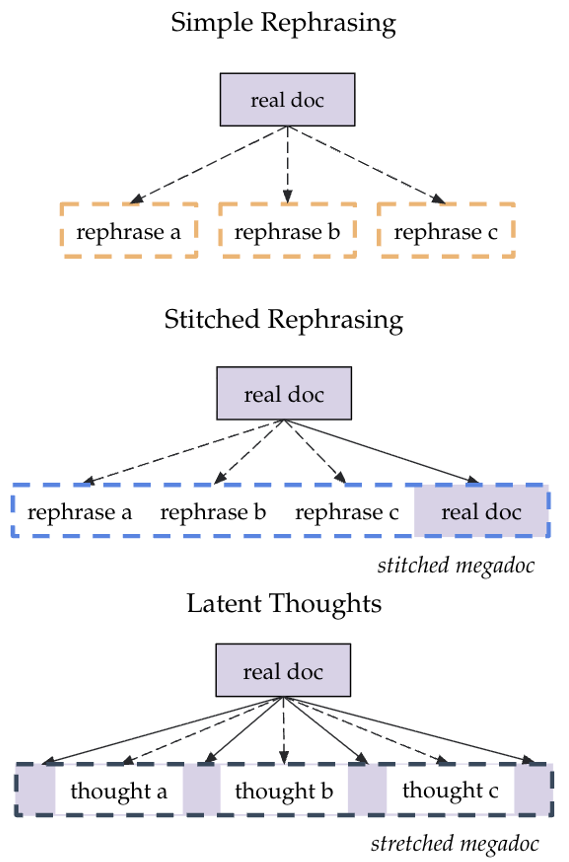 图 1:左侧展示了 Megadoc 的两种构造方式:Stitched(拼接)与 Latent Thoughts(潜意识插入)
图 1:左侧展示了 Megadoc 的两种构造方式:Stitched(拼接)与 Latent Thoughts(潜意识插入)
实验与结果:打破平台期的Scaling
实验在 300M 参数的 Transformer 模型上展开,使用了 200M 真实的 DCLM Token。
- Loss 持续下降:相比于简单重述(Simple Rephrasing)在 32 个副本附近陷入停滞,Megadocs 展现了更好的横向扩展性。
- 量化提升:Latent Thoughts 达到了 1.80x 的数据效率,意味着你只需要一半左右的真实数据,就能达到基线的 Loss。
- 下游任务:在 PIQA、SciQ 等基准测试中,准确率提升了 9%,这证明了这种预训练增益是可迁移的。
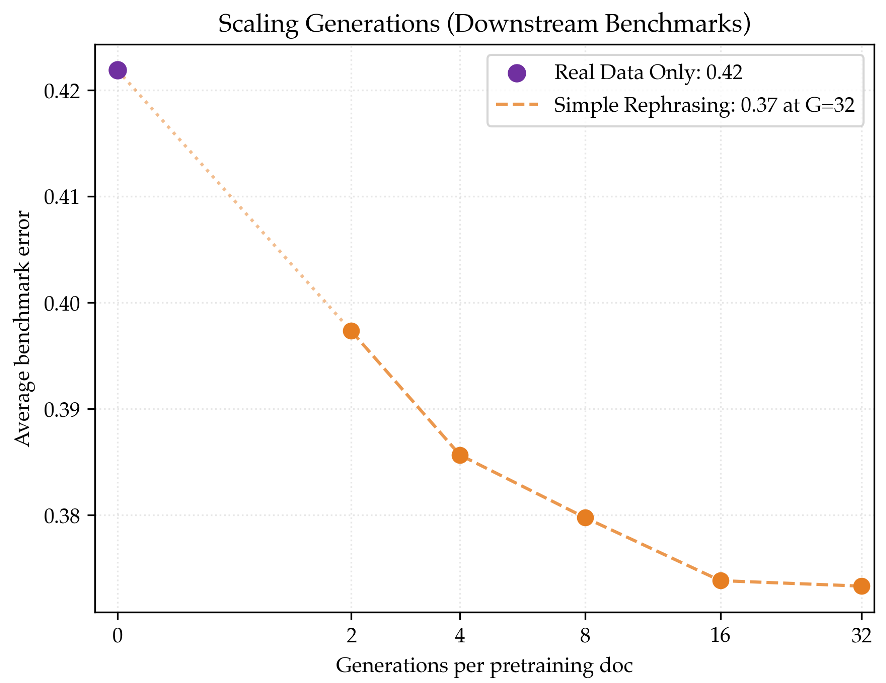 图 2:随着合成生成数量 G 的增加,Megadocs (Stitched & Latent) 的 Loss 下降斜率明显优于橙色的简单重述。
图 2:随着合成生成数量 G 的增加,Megadocs (Stitched & Latent) 的 Loss 下降斜率明显优于橙色的简单重述。
深度洞察:为什么 Megadocs 有效?
作者提出了一个深刻的假说:Megadocs 延长了有效训练的步数。 在有限数据下,模型很快会过拟合。但 Megadoc 这种复杂的长序列结构提高了超参数(如 Epoch, Mixing Fraction)的容忍上限。实验显示,Megadoc 允许模型对真实数据进行更多次的迭代(多达 32 个 Epoch)而不产生严重的过拟合,从而在有限的“矿藏”中挖掘出了更多的知识。
总结与局限性
Takeaway: Megadocs 证明了合成数据的组织形式(Structure)与内容本身同样重要。通过构建长程依赖任务,我们可以打破数据规模的物理限制。
局限性:
- 教师模型依赖:实验使用了 Llama 3.1 8B 作为教师。虽然作者通过 Ablation 证明了这种增益不仅仅是蒸馏,但在完全没有强大基座模型的冷启动阶段,该方法的有效性仍需验证。
- 计算成本:生成长文档和处理超长上下文对推理和训练算力提出了更高要求。
这项研究为未来的预训练数据工程指明了方向:不要只做数据的搬运工,要做数据的“编织者”。