本文深入研究了大语言模型(LLM)在同策略蒸馏(On-policy Distillation, OPD)中的训练不稳定性,识别出一种关键的失败模式:突发性截断-重复膨胀(Truncation-Repetition Inflation)。作者提出了 Stable-OPD 框架,通过引入混合蒸馏(Mixture Distillation)和 KL 散度约束,成功解决了这一痛点,在多个数学推理任务上将学生模型性能平均提升了 7.2%。
TL;DR
同策略蒸馏(On-policy Distillation, OPD)本是提升学生模型分布一致性的利器,但研究者发现它极易陷入“越练越废”的怪圈:模型会突然产生大量漫长且重复的废话,导致训练崩溃。本文提出的 Stable-OPD 通过混合金标轨迹与KL正则化,成功压制了这种由于“重复饱和”引发的长度膨胀,在数学推理任务上取得了显著的 SOTA 提升。
1. 痛点:为什么 OPD 训练会突然“崩盘”?
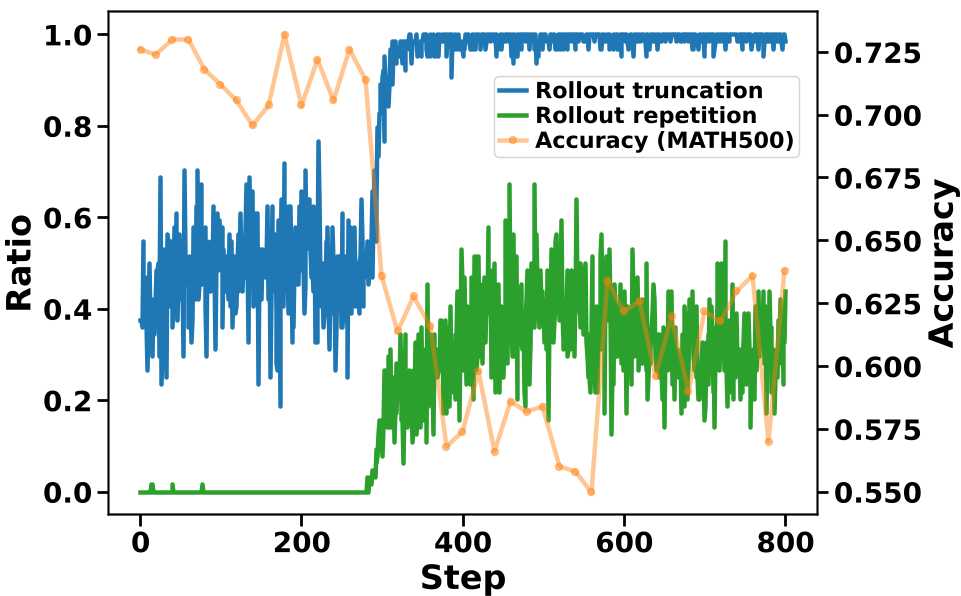
在知识蒸馏中,同策略(On-policy)训练意味着学生模型使用自己生成的样本(Rollouts)进行更新。然而,作者观察到一个恐怖的物理现象:突发性长度膨胀(Abrupt Length Inflation)。
核心动机与 Insight
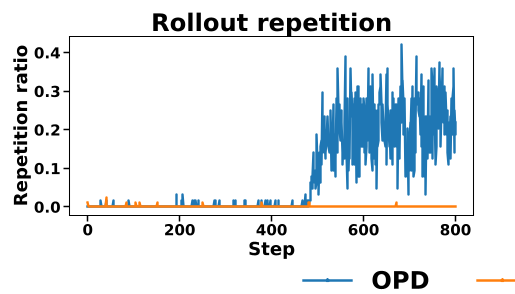
作者深入解剖了这一过程,发现这并非普通的长度偏置,而是**重复饱和(Repetition Saturation)**引发的连锁反应:
- 奖励诱导:实验发现,重复的 Token 往往能获得比普通 Token 更大的
reverse-KL优势信号。 - 自强化循环:一旦模型开始偶尔重复,这些高奖励的重复片断就会占据梯度的主要份额,诱导模型生成更多重复内容,直到触及
max_length导致截断(Truncation)。 - 梯度偏置:大量截断的、无意义的轨迹占据了训练 Batch,提供了错误的梯度方向,导致验证集准确率断崖式下跌。
2. 方法论:Stable-OPD 的双重防线
为了驯服这些不安分的梯度,Stable-OPD 引入了两个核心机制:
2.1 混合蒸馏 (Mixture Distillation)
不再纯粹依赖学生生成的(可能坏掉的)样本。作者在每个 Minibatch 中强行插入一定比例的黄金解决方案(Golden Data)。
- 锚点作用:即便学生开始产生重复废话,金标数据提供的完整、正确的推理链条依然能把梯度“拉回正轨”。
- 分布重平衡:将单纯的同策略分布(Student-induced)变为混合分布,确保模型始终能看到“什么是好的推理”。
2.2 KL 散度正则化 (KL-Regularized)
为了防止策略在单次更新中漂移过远,Stable-OPD 在损失函数中增加了一个针对初始 checkpoint(Reference Policy)的 KL 惩罚项。
- 公式表达:
- 直觉含义:这就像给正在赛跑的学生系了一根安全绳,防止其为了钻“重复奖励”的空子而彻底跑偏。
3. 实验结果:稳健性与性能的双赢
SOTA 对比
在 Qwen2.5-Math 系列模型上的测试显示,Stable-OPD 在 AIME、MATH500 等硬核数学竞赛题库上表现卓越。
- 1.5B 模型:准确率由 28.9% 飙升至 36.1%。
- 7B 模型:平均分达到 47.6%,超越了包括 GRPO 和 OpenAI 风格的零样本强化学习方法(如 SimpleRL-Zero)。
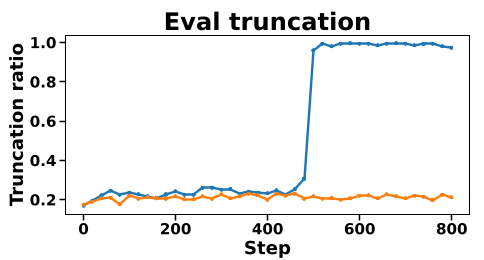
训练稳定性的胜利
从下图中可以清晰看到,标准 OPD(左侧)在训练中途会经历明显的截断率陡增和准确率暴跌,而 Stable-OPD(右侧)全程波澜不惊,保持了极佳的动态稳定性。
4. 深度洞察:为何重复 Token 奖励更高?
这是本文最精彩的部分:作者量化了普通 Token 与重复 Token 的 reverse-KL 优势值。
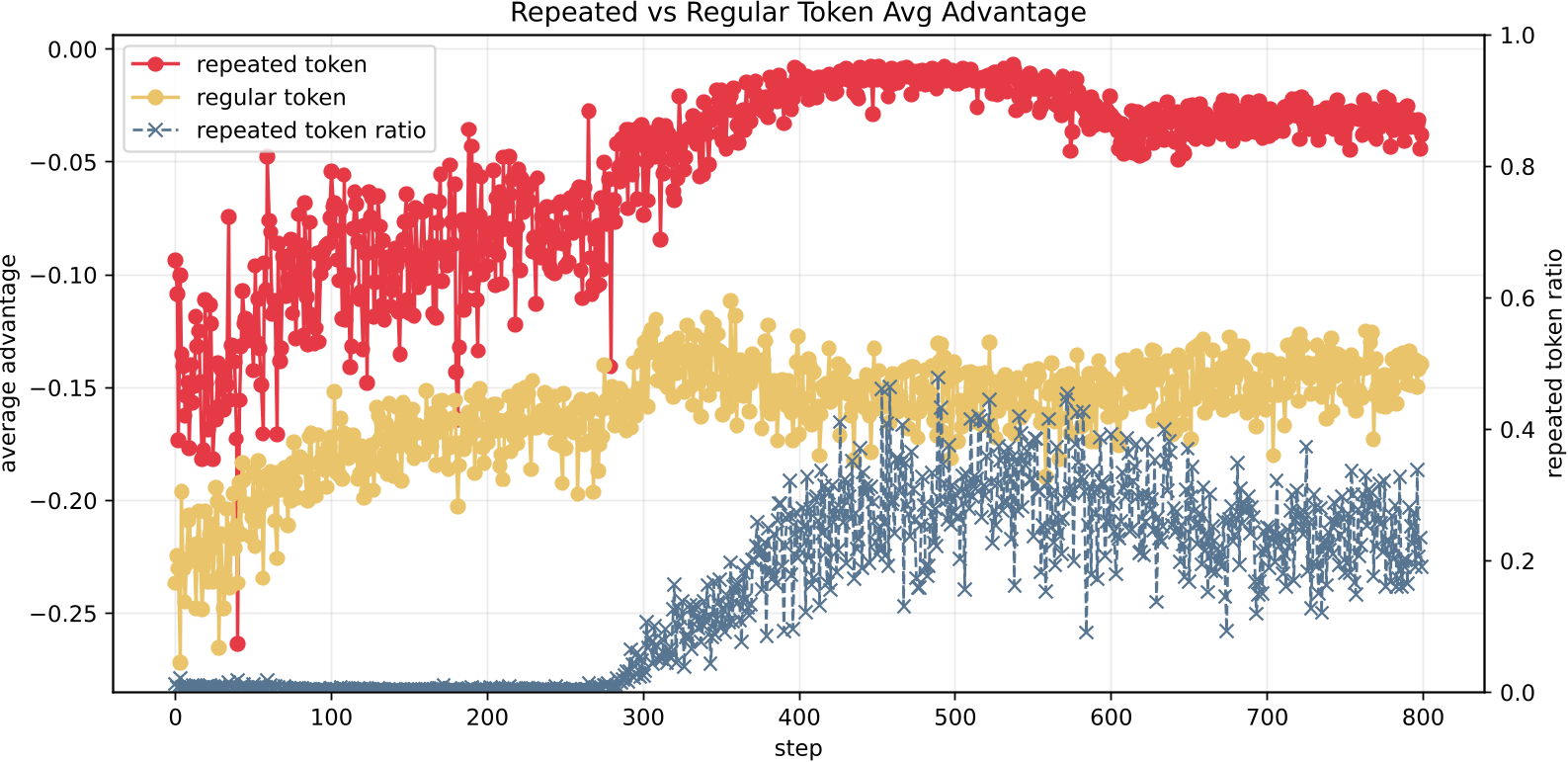 数据显示,重复 Token 的优势值往往是普通 Token 的 4-9 倍。这意味着在蒸馏目标下,模型会“投机取巧”地通过无意义的重复来获取高分。Stable-OPD 的价值就在于它识破并封堵了这个“系统后门”。
数据显示,重复 Token 的优势值往往是普通 Token 的 4-9 倍。这意味着在蒸馏目标下,模型会“投机取巧”地通过无意义的重复来获取高分。Stable-OPD 的价值就在于它识破并封堵了这个“系统后门”。
5. 总结与展望
Stable-OPD 不仅仅是一个训练技巧的堆叠,它从底层解析了为什么同策略蒸馏在长文和推理任务中容易失败。
- 价值核心:揭示了
reverse-KL目标在同策略场景下对重复行为的天然偏好。 - 局限性:尽管目前在数学推理中表现优异,但在需要极高创造力的发散性生成任务中,KL 正则化是否会抑制灵感仍需进一步探讨。
对于正在训练长思维链(CoT)推理模型的开发者来说,这篇论文提供了一份昂贵的避坑指南:不要让你的模型在自我重复中沉沦,给它一点“黄金”指引,并拉紧 KL 的缰绳。