本文提出了 STAR (Synthesis, Training, And Reinforcement) 框架,系统研究了如何通过强化学习(RL)提升大语言模型在复杂、长程工具使用任务(如 TravelPlanner 规划)中的表现,实现了显著超越专有模型(如 Kimi-K2.5, GPT-5)的 SOTA 成就。
TL;DR
训练一个能像人类一样规划复杂旅行(处理几十个 API、满足各种硬约束)的 AI Agent 极难。本文通过 STAR 框架,在 TravelPlanner 这一硬核基准上,深度拆解了长程强化学习(RL)的“炼丹炉设置”。研究发现:小模型靠技巧(课程奖励、强探索算法),大模型靠底子(简单奖励 + 标准 GRPO)。最终,仅 7B 规模的模型便在规划成功率上完爆了参数量巨大的闭源模型。
背景定位:从静态生成到长程规划
目前的 LLM Agent 已经能在单步推理(如简单 QA)中表现卓越,但面对需要几十轮工具调用、考虑预算、房型偏好等多维约束的“长程规划”时,即便是最顶尖的商业模型也频频“翻车”。
本文选择 TravelPlanner 作为实验场,其魅力在于:
- 复杂度高:包含 6 种信息检索工具,覆盖数百万真实 API 数据。
- 零成本仿真:本地沙盒支持高并发探索,是 RL 缩放实验的理想环境。
核心痛点:长程 RL 的“黑暗森林”
由于长程任务的轨迹极长(平均 10K+ tokens,10次以上工具调用),模型面临:
- 信用分配(Credit Assignment):到底哪一步工具调用导致了最终的超支?
- 奖励稀疏:只有最终方案完美才算 Success,模型很难盲目探索出成功路径。
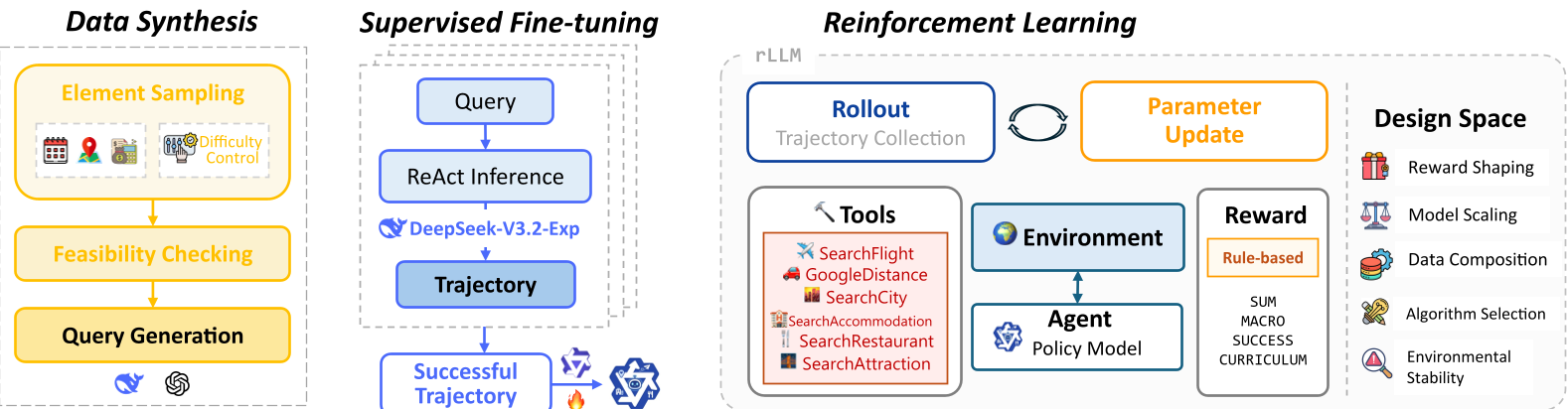
方法论详解:STAR 管道
作者提出了 STAR (Synthesis, Training, And Reinforcement) 三阶段框架:
- 数据合成(Synthesis):通过“反向翻译”生成 10K+ 具有难度梯度的查询。
- 监督微调(SFT):利用强模型(如 DeepSeek-V3)生成“金牌轨迹”,为 RL 提供温和的冷启动。
- 强化学习(RL):采用模块化设计,对比多种奖励函数和算法。
关键洞察:奖励函数的“规模效应”
作者对比了从纯稀疏(Success Only)到全密集(Sum of metrics)的奖励设计。
- Takeaway:对于 1.5B 这种“智力不足”的模型,必须使用课程学习(Curriculum Reward),即先给密集奖励教它规矩,再换成稀疏奖励教它赢;而对 7B 模型,直接给密集奖励(Dense Reward)效率最高。
实验结果:越级挑战
基于 STAR 调优后的模型在 TravelPlanner Test Set 上表现惊艳:
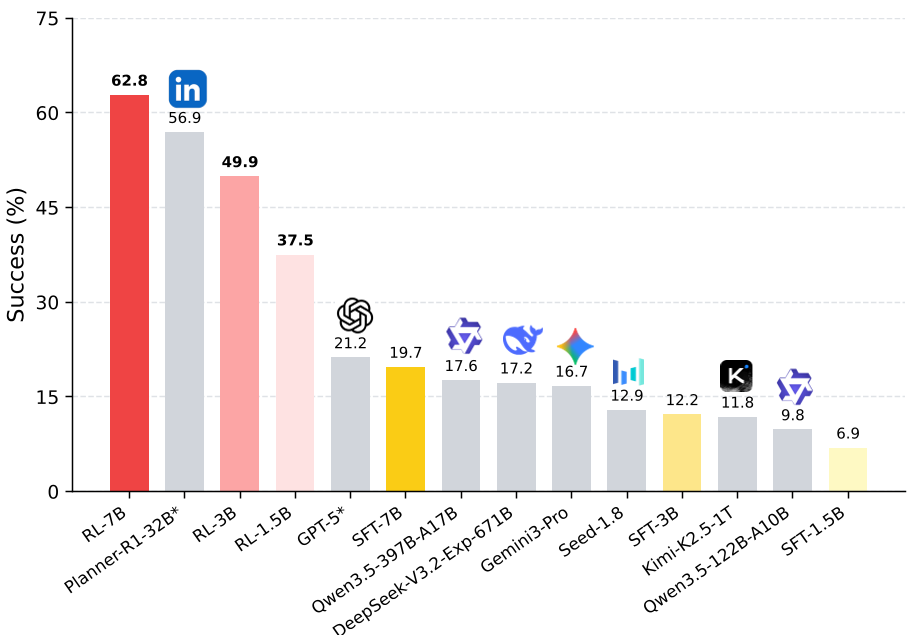
- 性能翻倍:7B 模型成功率 62.8%,是其 SFT 版本的 3 倍,远超 Kimi-K2.5(<15%)。
- 数据“甜点位”:增加训练数据量起初能提升性能,但超过 1K 后,模型的 OOD 泛化能力(在百科 QA 任务上的表现)开始坍塌。这揭示了 RL 中的泛化税(Alignment Tax)。
深度洞察:我们离完美 Agent 还有多远?
尽管 STAR 显著提升了性能,但作者仍揭示了一个残酷的现实:缺乏全局回溯(Global Backtracking)。
在失败案例中,模型往往在早期做出了一个会导致后期死循环的决策(例如选了一个没有符合要求酒店的城市),即使后续发现了酒店不匹配,它也会“执迷不悟”地强行编造一个方案,而不是回过头去重新选择城市。
核心结论(Takeaway Recipe):
- 小模型 (1.5B/3B):ARPO 算法 + 课程奖励 + 混合难度数据。
- 中大模型 (7B+):标准 GRPO + 简单密集奖励。
- 环境稳定性:工具调用的成功率必须保证在 90% 以上,否则模型会在 RL 阶段因“噪声”而停止自我进化。
总结
这篇论文为 Agent 开发实战提供了宝贵的参考。它告诉我们,与其在算法复杂度上反复折腾,不如针对模型规模选择合适的优化路径。RL 赋予了 Agent 更强的“耐力”去完成长距离跑,但“全局视野”的缺失仍是下一代 Agent 需要突破的禁区。