本文提出了 DFM-VLA,一种基于离散流匹配(Discrete Flow Matching)的视觉-语言-动作模型。该模型通过引入令牌级概率速度场,实现了对动作序列的并行迭代修正,在 CALVIN (Avg. Len 4.44) 和 LIBERO (95.7% Success Rate) 等机器人操控基准测试中达到了 SOTA 性能。
TL;DR
在机器人操控领域,视觉-语言-动作模型(VLA)正面临一个尴尬的瓶颈:早期报错,满盘皆输。本文提出的 DFM-VLA 引入了离散流匹配(Discrete Flow Matching)技术,让模型具备了“反悔”的能力。通过在生成过程中动态调整已生成的动作令牌,DFM-VLA 在 CALVIN 和 LIBERO 等基准测试上全面刷新纪录,并实现了推理速度的翻倍。
1. 痛点:不可逆的“致命错误”
目前的 VLA 模型主要分为两派:
- 自回归 (AR):逐个令牌预测。一旦第一个动作令牌错位,后面的序列往往会错上加错。
- 离散扩散 (DD):虽然支持并行,但在早期迭代中确定的高置信度令牌在后期很难被大规模重写。
作者将此现象称为 Irreversible Commitment (不可逆承诺)。在精细的机器人操作(如开门、抓取细小物体)中,这种缺乏容错机制的解码方式正是导致模型性能触顶的主因。
2. 核心直觉:引入“速度场”的动态修正
DFM-VLA 的核心思想是不再把动作生成看作“填空题”,而是一个“演化过程”。
行动令牌的流匹配
模型通过建模一个令牌级概率速度场 (Probability Velocity Field) 来指导动作序列的更新。这意味着在每一个解码步骤中,模型不仅在预测“正确的动作是什么”,还在计算“当前令牌应该以多快的速度向目标状态演化”。
两种建模方案
论文深入探讨了两种构建速度场的方式:
- Auxiliary Velocity Head:额外增加一个预测头来输出更新速率。
- Action-Embedding-Guided (本文推荐):利用动作令牌在嵌入空间中的几何距离来引导路径。直观地说,语义越接近的动作,它们之间的“流动”就越顺滑。
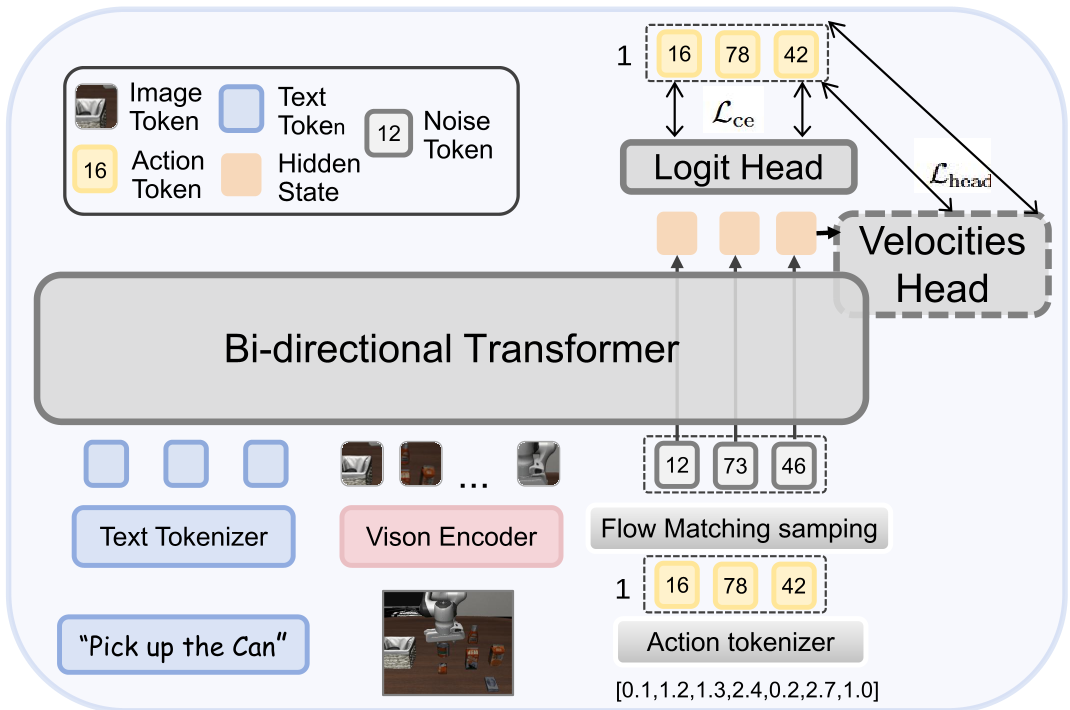 图 1:DFM-VLA 整体架构,统一了视觉、语言和动作的离散表示。
图 1:DFM-VLA 整体架构,统一了视觉、语言和动作的离散表示。
3. 解码黑科技:两阶段与自适应加速
为了平衡“灵活性”与“稳定性”,DFM-VLA 采用了一个聪明的两阶段解码策略:
- 迭代修正阶段 (Refinement Stage):使用 Euler 离散化采样,允许令牌通过随机跳变进行探索和错误修正。
- 确定性验证阶段 (Validation Stage):在最后几步切换为贪婪解码,强制收敛到稳定输出。
此外,为了解决迭代带来的计算开销,作者引入了 Adaptive KV Caching。通过检测动作令牌特征的变化幅度,模型可以跳过那些不需要更新的 KV 缓存,最终在 H100 GPU 上实现了 121.0 tokens/s 的高推理速度,比传统 AR 模型快 2.4 倍。
4. 实验战绩:SOTA 与真实世界泛化
在仿真环境 CALVIN 中,DFM-VLA 展现了极强的长程任务一致性。
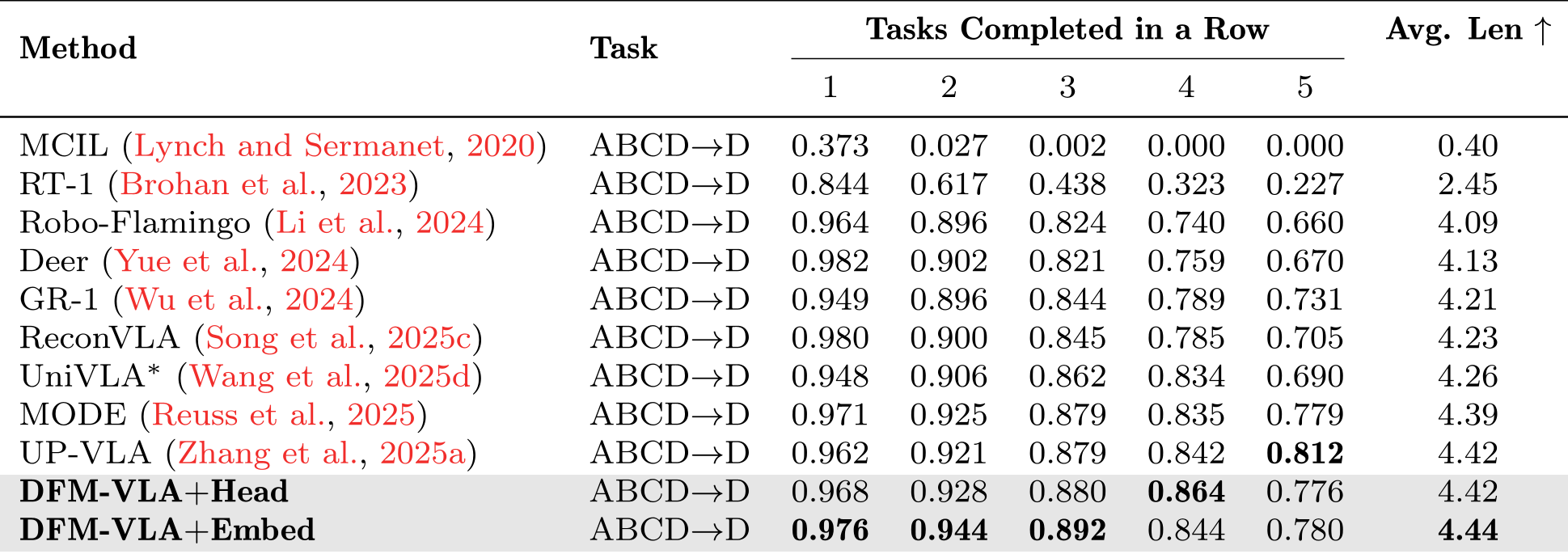 表 1:在 CALVIN ABCD→D 任务中,DFM-VLA 以 4.44 的平均长度位居第一。
表 1:在 CALVIN ABCD→D 任务中,DFM-VLA 以 4.44 的平均长度位居第一。
在更为复杂的 LIBERO 任务中,DFM-VLA 在 Object(物体泛化)和 Long(长程组合)子项上表现尤为出色,平均成功率达到 95.7%。这证明了其在面对未见物体和复杂逻辑时的稳健性。
真实世界表现
在真实的 AgileX 双臂机器人平台上,DFM-VLA 完成了协同抬锅、置物等复杂任务,平均成功率(70.8%)大幅领先于基于扩散模型的 baseline (60.0%) 和 π0-FAST 等方法。
5. 深度洞察
为什么 DFM-VLA 这么强?
- 低数据制度下的韧性:消融实验显示,在仅使用 10% 数据时,DFM-VLA 的领先优势最大。这说明迭代修正机制能显著降低模型对海量专家数据的依赖。
- 语义感知:Embedding 引导的流匹配利用了动作空间的流形结构,使得错误修正变得“有迹可循”。
6. 总结与展望
DFM-VLA 成功地将生成式 AI 的前沿理论(DFM)应用于机器人操控。它告诉我们,赋予机器人“思考并更正”的能力,比让它“过目不忘”更加重要。未来的挑战可能在于如何将此架构扩展到更高维度(如全身控制)以及如何进一步压缩迭代步数以适应极致的实时性要求。
参考资料: