DialogueSidon is a joint speech restoration and separation model designed to recover individual clean tracks from degraded monaural two-speaker dialogue audio. It combines an SSL-VAE latent space with a diffusion-based latent predictor, achieving superior content preservation and 60x faster inference compared to current SOTA unified models.
TL;DR
Researchers from the University of Tokyo and AIST have unveiled DialogueSidon, a specialized model that performs one of the most challenging tasks in speech processing: simultaneously restoring and separating messy, monaural two-party conversations into clean, individual speaker tracks. By moving the heavy lifting into a compressed SSL latent space, DialogueSidon outperforms previous unified models in intelligibility while being 60 times faster.
The Data Scarcity Bottleneck in Conversational AI
The next frontier of AI—natural, full-duplex dialogue—requires models to understand when to interrupt, how to provide backchannels ("uh-huh"), and how to manage overlaps. However, training such models requires "full-duplex" data: separate, clean recordings for each person.
While the internet is full of dialogue (podcasts, YouTube, interviews), most of it is:
- Monaural mixtures: Both speakers are baked into one track.
- Heavily degraded: Riddled with background noise, reverb, and bad compression.
Previous attempts to fix this usually cascaded a "restoration" model and a "separation" model. The problem? Restoration models often think the second speaker is "noise" and erase them, while separation models struggle with real-world acoustic garbage.
Methodology: The SSL-Diffusion Synergy
DialogueSidon solves this by working in a compact latent space derived from Self-Supervised Learning (SSL) features.
1. SSL-VAE (The Compact Blueprint)
Directly applying a diffusion model to raw audio or raw SSL features (like w2v-BERT 2.0) is computationally brutal. DialogueSidon uses a VAE (Variational Autoencoder) to compress these features into a small, 32-dimensional latent space. This space preserves the "essence" of human speech while discarding the bits that don't matter for content and speaker identity.
2. Latent Predictor (The "Remixer")
The core innovation is a Diffusion Transformer (DiT) that takes a degraded mixture and predicts the clean latent tracks for both speakers. To solve the "who is who" problem (Permutation Ambiguity), the authors added Auxiliary Heads. These heads provide a "rough draft" of the speaker separation, which helps align the diffusion process so the model doesn't swap voices mid-conversation.
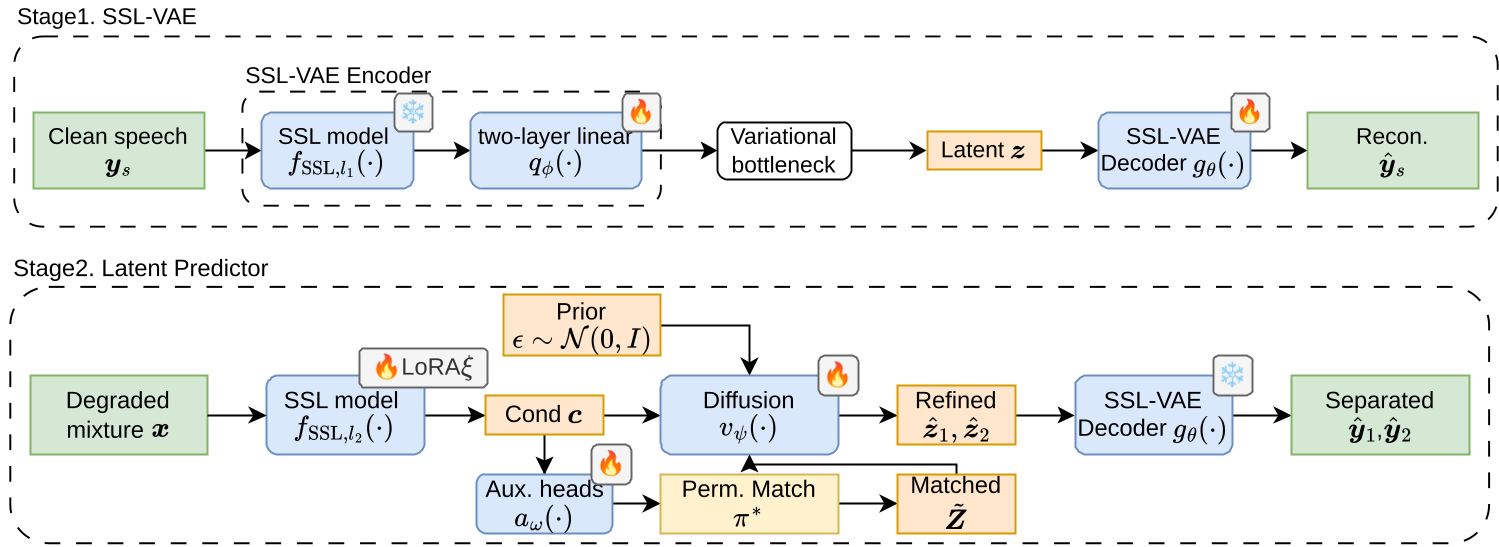 Figure 1: Training workflow showing the transition from SSL-VAE compression to Diffusion-based latent prediction.
Figure 1: Training workflow showing the transition from SSL-VAE compression to Diffusion-based latent prediction.
Experimental Results: Faster and More Intelligible
The authors tested DialogueSidon against GENESES, a current state-of-the-art flow-matching baseline.
- Intelligibility (WER): In "in-the-wild" Internet audio (OpenDialog), DialogueSidon achieved a Word Error Rate of 13.86%, crushing the baseline's 43.79%. This suggests the model is far better at preserving what people actually said.
- Human Preference (MOS): Human listeners rated DialogueSidon significantly higher (3.895) than either the baseline or the raw recordings, noting better separation and clarity.
- Inference Speed: Perhaps most importantly for industrial scaling, DialogueSidon has a Real-Time Factor (RTF) of 0.010. For context, it can process 20 seconds of audio in 0.2 seconds—60 times faster than the baseline.
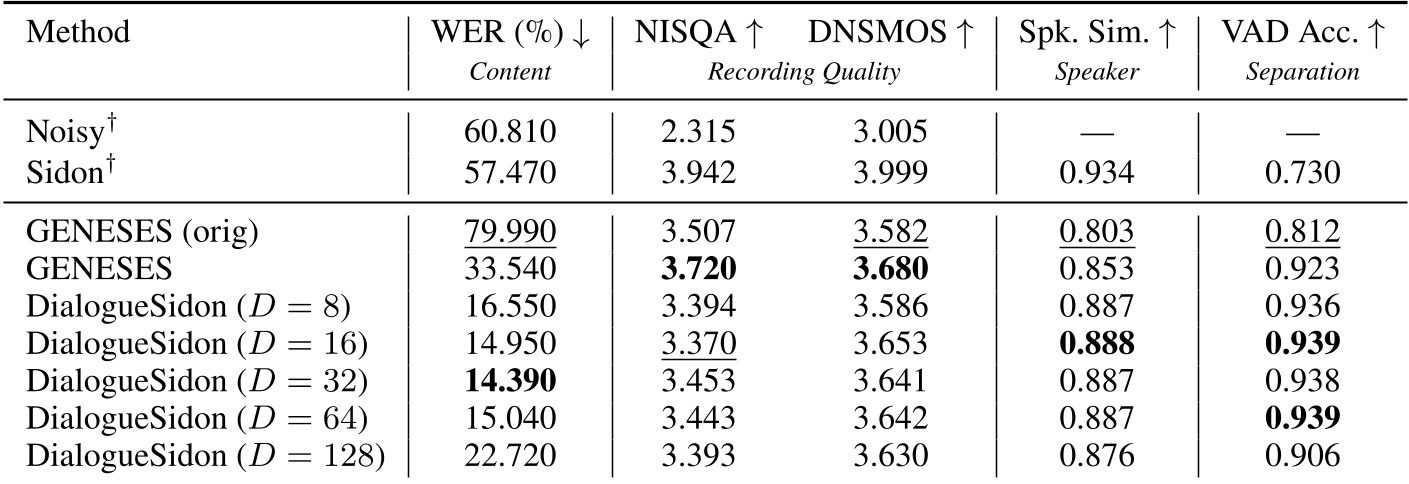 Table 1: Quantitative results on the Switchboard (SWB) corpus, highlighting the dramatic improvement in WER (Word Error Rate).
Table 1: Quantitative results on the Switchboard (SWB) corpus, highlighting the dramatic improvement in WER (Word Error Rate).
Critical Insights & Future Outlook
The success of DialogueSidon points to a shift in the field: moving away from raw waveform manipulation toward latent space manipulation. By operating in a space already "understood" by powerful SSL models (w2v-BERT), the diffusion model doesn't have to learn what speech sounds like from scratch; it only has to learn how to "un-mix" and "un-distort" it.
Limitations: Currently, the model is optimized for two speakers. As anyone who has heard a heated debate knows, dialogues often involve three or more participants. Extending this "latent refinement" approach to N-speakers while maintaining efficiency will be the next major hurdle.
Potential Impact: This tool allows researchers to tap into millions of hours of YouTube and podcast data that were previously "too noisy" for high-fidelity dialogue research, potentially accelerating the development of truly human-like conversational agents.