本文提出了 DialogueSidon,这是一个专注于从野外(in-the-wild)单声道混合音频中恢复全双工(Full-Duplex)分轨对话的模型。该方法结合了基于自监督学习(SSL)特征的 VAE 潜空间与扩散模型预测器,实现了 SOTA 级别的语音修复与人声分离性能。
TL;DR
构建类人对话系统的核心瓶颈在于缺乏高质量的**全双工(Full-Duplex)**数据——即每个发言者都有独立、干净音轨的录音。东京大学与 AIST 的研究者推出了 DialogueSidon,它能直接将带有噪音、回声、重叠的互联网单声道音频,“炼金术”般地还原为两个清晰的独立音轨。相比前人工作,其字错率(WER)大幅下降,且推理速度提升了惊人的 60 倍。
1. 痛点:为什么“先修复再分离”行不通?
在语音研究领域,直接从互联网(In-the-wild)抓取的音频通常是一团糟:背景音乐、严重的 codec 压缩、环境噪音,以及最头疼的——两个人的声音混在一起。
目前主流的级联方案存在致命缺陷:
- 先修复方案:语音修复模型(如传统增强算法)会将两个人的声音重叠部分误认为是“噪音”,从而破坏掉其中一个人的语义。
- 先分离方案:当音频质量极差(低采样率、高底噪)时,现有的分离模型(如 Conv-TasNet)根本无法在杂讯中分辨出人声特征。
因此,**联合修复与分离(Joint Restoration and Separation)**成为了必然选择。
2. 核心架构:SSL 潜空间下的扩散之美
DialogueSidon 的核心设计逻辑是:不要在原始波形上纠缠,去潜空间(Latent Space)解决问题。
2.1 SSL-VAE 压缩
模型首先利用预训练的 w2v-BERT 2.0 提取特征。由于 SSL 特征维度极高(通常 1000+ 维),直接跑扩散模型(Diffusion)计算量巨大。作者设计了一个 VAE,将特征压缩到一个极小(如 32 维)的潜空间中。
2.2 解决排列歧义(Permutation Ambiguity)
对话分离的一个经典难题是:模型输出的两个轨道,谁是谁?DialogueSidon 引入了辅助预测头(Auxiliary Heads)。它先粗略地预测一个发言者分配,利用 PIT(Permutation Invariant Training)对齐标签,从而降低了后续扩散模型精修的难度。
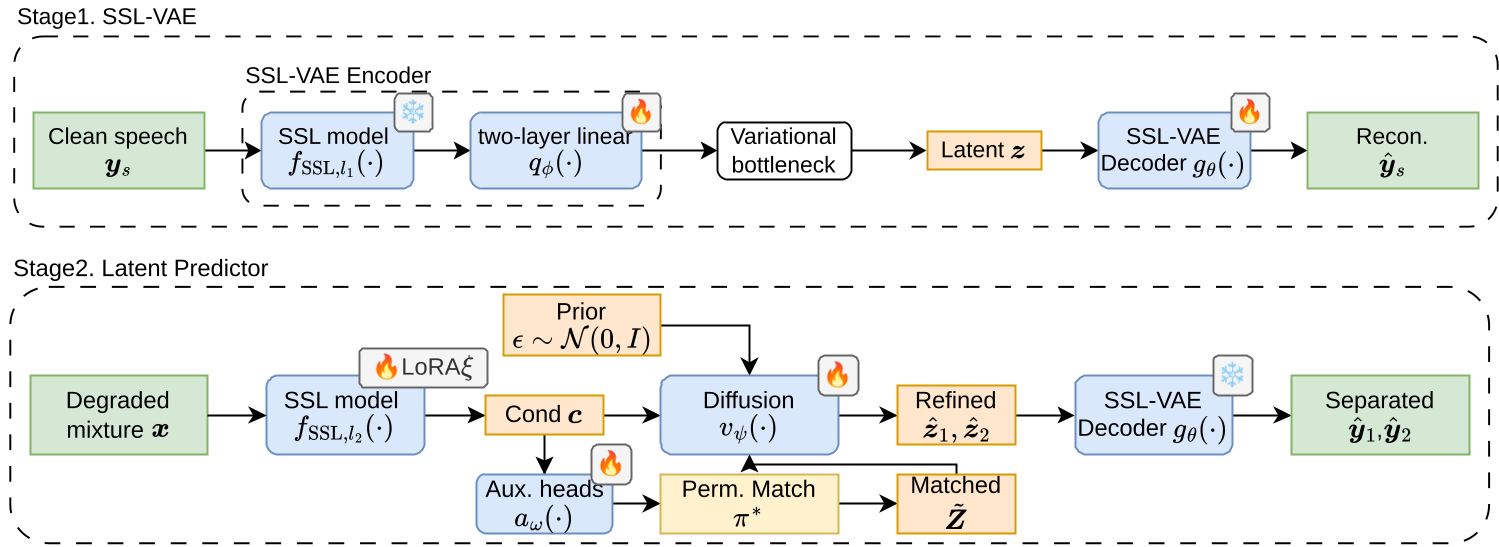 图 1:DialogueSidon 训练流程,展示了从退化音频到预测潜变量再到波形重建的过程。
图 1:DialogueSidon 训练流程,展示了从退化音频到预测潜变量再到波形重建的过程。
3. 实验战绩:全方位的跨越
研究团队在 Switchboard (英语)、CallFriend (多语言) 以及最难的 OpenDialog (互联网) 数据集上进行了严密测试。
3.1 性能 vs 质量
- 语义保持:在外部 ASR 模型下,DialogueSidon 恢复出的音频 WER 仅为 13.86%,而基线模型 GENESES 高达 43.79%。这证明了该模型极好地保留了对话中的语言信息。
- 主观听感 (MOS):人类评分显著高于所有基线。有趣的是,虽然某些回归模型(如 GENESES)在自动指标(NISQA)上可能略高,但人类一致认为 DialogueSidon 的分离更干净、发言者一致性更强。
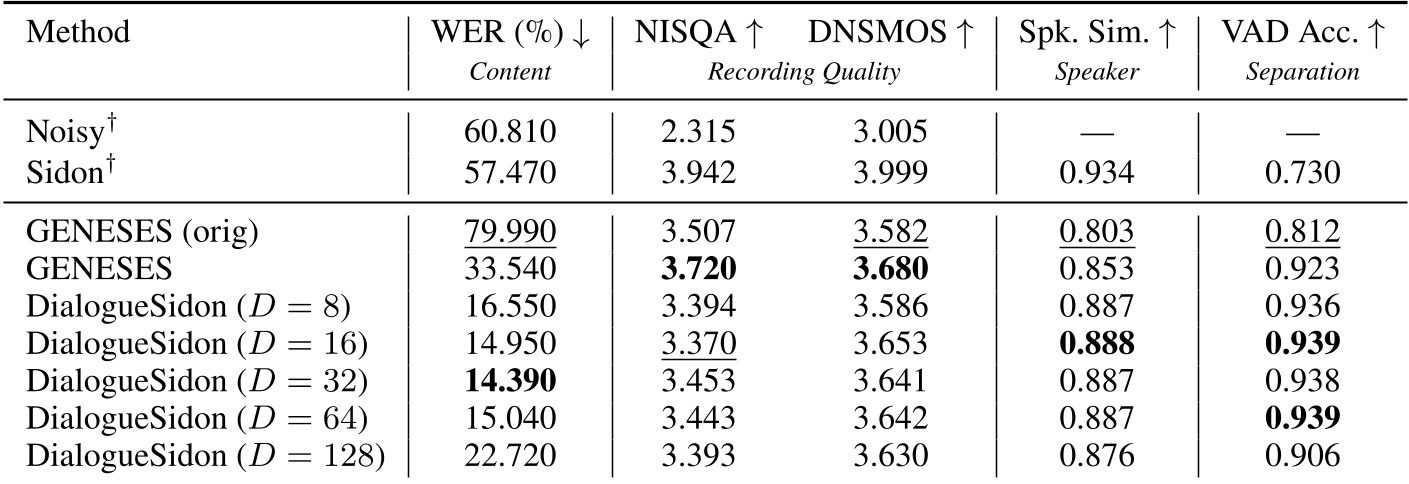 表 1:在 Switchboard 数据集上,不同潜变量维度(D)对性能的影响分析。
表 1:在 Switchboard 数据集上,不同潜变量维度(D)对性能的影响分析。
3.2 速度:工程化的胜利
对于需要处理百万小时级别数据的任务,速度就是生命。DialogueSidon 的 RTF 为 0.010。这意味着处理一小时音频仅需 36 秒。
- 原因分析:得益于在压缩潜空间操作,DialogueSidon 的 DiT(Diffusion Transformer)参数量仅为 88M,而基线高达 393M。
4. 深度洞察与总结
DialogueSidon 的成功提供了几个核心启示:
- SSL 特征的鲁棒性:w2v-BERT 2.0 在数百万小时语音上练就的“火眼金睛”,能有效抵御背景噪音的干扰。
- 潜空间扩散的效率:相比直接生成波形,生成潜变量极大地减小了搜索空间,降低了推理成本。
- 对话数据的价值:作者强调,即使模型架构再好,如果不使用对话数据进行针对性微调(Fine-tuning),直接用单人语音训练的模型在处理重叠(Overlap)和插嘴(Backchannel)时表现极差。
局限性:目前模型仅支持双人对话。在诸如聚会、会议等多人场景(3人以上)下,其性能和架构尚待扩展。
结论:随着 DialogueSidon 的开源,我们离大规模获取高质量、真实现场的全双工对话数据又近了一大步。