本文提出了 DACO,一个利用对齐词典进行激活增强转向的框架,用于提升多模态大语言模型(MLLMs)的安全性。通过构建包含 1.5 万个概念的 DACO-400K 数据集并结合稀疏自编码器(SAE),在 QwenVL 和 LLaVA 等模型上实现了 SOTA 级的防御性能。
TL;DR
传统的 MLLM 安全防御手段(如微调或 Prompt)要么太死板,要么太费力。本文提出的 DACO (Dictionary-Aligned Concept Control) 框架,通过构建一个包含 15,000 个多模态概念的“外部导航手册”,精准定位并操纵模型内部的隐藏激活状态。在几乎不损失模型智商的情况下,DACO 能够有效拦截各种阴险的“越狱”攻击。
1. 痛点:为什么 MLLM 的安全防御这么难?
当前的 MLLM(如 LLaVA, Qwen-VL)极易受到恶意攻击,比如在图片里塞入隐蔽的文字(Typographic Attack)或者诱导性的角色扮演。
- Prior Work 的局限:
- Prompting:容易被“对抗样本”绕过,防御强度难以微调。
- Finetuning:计算昂贵,且容易出现“灾难性遗忘”(模型变笨了)。
- 现有 Steering 方法:能控制的概念太少(通常只有不到20个),就像用钝刀做手术,难以区分“有害意图”和“正当请求”。
2. 核心直觉:给激活空间一个“搜索引擎”
作者认为,既然模型内部的隐藏状态(Activations)遵循线性表征假设,那么我们就应该能找到每一个安全概念在模型内部的“坐标”。 DACO 的核心贡献在于建立了一套语义标注系统,将复杂的 SAE(稀疏自编码器)原子与人类可理解的 WordNet 概念挂钩。
3. 方法论详解:DACO 的三步走战略
第一步:构筑 DACO-400K 词典
作者从 WordNet 提取概念,利用 CLIP 在两亿图像数据中检索出 40 万个刺激样本(Stimuli),通过对比正负样本在模型内部的残差流(Residual Stream),计算出 15,000 个平面的概念向量 (Concept Vectors)。
第二步:由词典驱动的 SAE 训练
不同于传统的随机初始化,DACO 使用预先计算的概念向量来初始化 SAE 的解码器权重。这种**“语义强约束”**使得训练出的 SAE 原子天生具有极高的单语义性(Monosemanticity)。
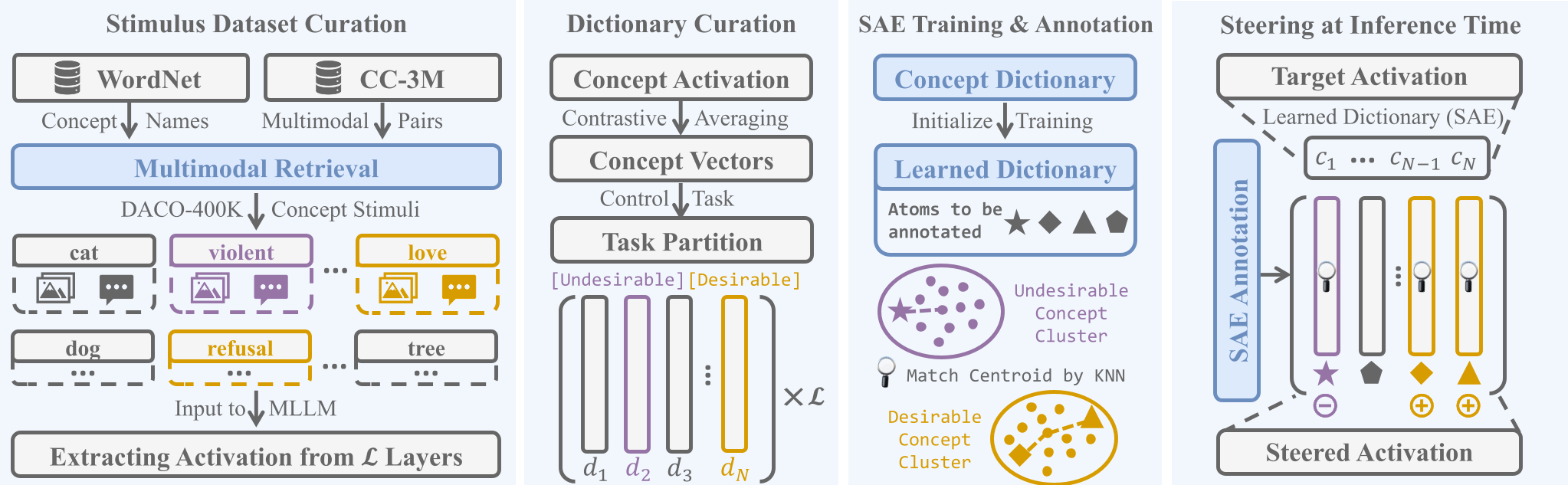 图 1:DACO 转向流水线,展示了从概念词典到推理干预的全过程
图 1:DACO 转向流水线,展示了从概念词典到推理干预的全过程
第三步:推理时的动态干预
在模型生成每一个 token 时,DACO 会进行如下操作:
- 分拆(Encoding):将当前激活向量分解为一系列 SAE 原子。
- 手术(Steering):将识别出的“有害原子”系数归零,同时通过增益系数 强化“有益原子”。
- 重组(Decoding):将优化后的向量塞回模型,从而改变随后的生成内容。
4. 实验战绩:高防且高保真
在针对 Qwen2.5-VL 等最强开源模型的测试中,DACO 展现了恐怖的防御力:
- 安全性 (Safety):在越狱评测中远超 ActAdd 和 MOP 方案。
- 通用能力 (Utility):在 MMMU 全能理解测试中,分数的下降几乎可以忽略不计。
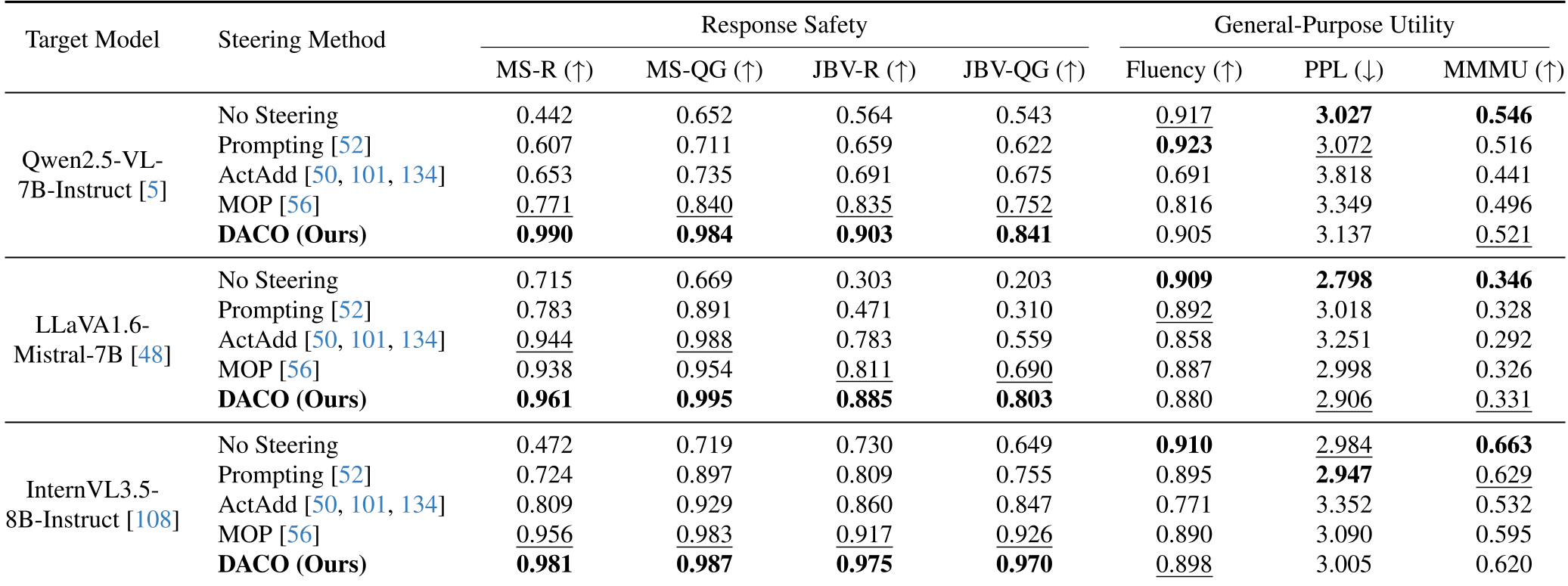 表 1:DACO 在不同 Backbones 上的表现,可见其在防御成功率与通用能力之间的绝佳平衡
表 1:DACO 在不同 Backbones 上的表现,可见其在防御成功率与通用能力之间的绝佳平衡
5. 深度洞察:为什么这种做法是未来的趋势?
- 极低的 Overhead:相比于多轮对话校验,DACO 只增加了约 14.6% 的每 token 推理时间,这在生产环境中是完全可接受的。
- 避免过度防御(False Refusal):实验证明 DACO 不像某些硬过滤机制那样“一刀切”,它能够识别出 benign 但带有敏感词的情境(如讨论吸毒的危害),从而给出更合理的回复。
- 概念的可解释性:我们可以清晰地看到在处理恶意请求时,哪些原子(如 #13331 表示攻击性)被激活并随后被抑制了。
结论
DACO 的成功标志着 MLLM 安全防御从“黑盒调优”转向了“白盒干预”。通过给模型内部复杂的激活空间配备一把带有“语义刻度”的尺子,研究者们终于可以更加从容地驯服这些日益强大的多模态野兽。
Author Perspective: 笔者认为,DACO-400K 词典的开源价值可能不亚于其算法本身。它为未来的透明 AI 研究奠定了坚实的物质基础。