DiReCT is a lightweight post-training framework designed to improve physical plausibility in flow-matching video generators like Wan 2.1. By employing entanglement-aware multi-scale contrastive learning, it achieves a 16.7% improvement in Physical Commonsense on VideoPhy and reaches a SOTA score of 5.68 on WorldModelBench, surpassing models 7.7x its size.
TL;DR
Even the most advanced video generators often feel like "dream logic"—balls bounce before hitting the ground, and steel spoons melt into yogurt. DiReCT (Disentangled Regularization of Contrastive Trajectories) is a new post-training framework that fixes this by teaching models not just what a scene looks like, but how it must move. By refining the velocity fields of flow-matching models (like Wan 2.1), DiReCT achieves state-of-the-art physical commonsense scores, outperforming models nearly 8 times its size.
The "Glitch in the Matrix": Why Video AI Fails at Physics
Most video models use a reconstruction objective. They try to minimize the difference between the pixels they generate and the pixels in a training video. To the model, a pixel that is slightly the wrong shade of blue is just as "wrong" as a ball passing through a solid wall.
The authors identify a deeper issue: Semantic-Physics Entanglement. In text-to-video, the prompt "A heavy bowling ball falling" couples the appearance (bowling ball) with the physics (falling). If you try to use standard contrastive learning—pushing an "anchor" away from a "negative"—you often end up pushing the model away from the correct visual look of the ball just to try and fix the motion. This creates a gradient conflict where the model gets confused, causing the physics to plateau or even degrade.
The Core Insight: DiReCT's Multi-Scale Strategy
To solve the gradient conflict, DiReCT decomposes the learning signal into two distinct scales, ensuring that the "push" and "pull" of the training process never work against each other.
1. Macro-Contrastive (MaNS): Global Separation
The model partitions the entire world of prompts into semantic clusters (e.g., "cooking," "sports," "weather"). By only contrasting a video against a negative from a different cluster, the model avoids semantic overlap. This builds a clean global map of how different types of motion should look.
2. Micro-Contrastive (MiNS): The "Hard" Physics Teacher
This is the most innovative part. The researchers used Qwen2.5-7B to create "hard negatives"—prompts that are identical to the original except for one physical law.
- Original: "A glass shattering on the floor."
- Perturbed (Material): "A glass stretching like rubber on the floor."
By training the model to push its velocity field away from these subtly "wrong" physics while keeping the scene the same, the model learns the fine-grained nuances of physical interaction.
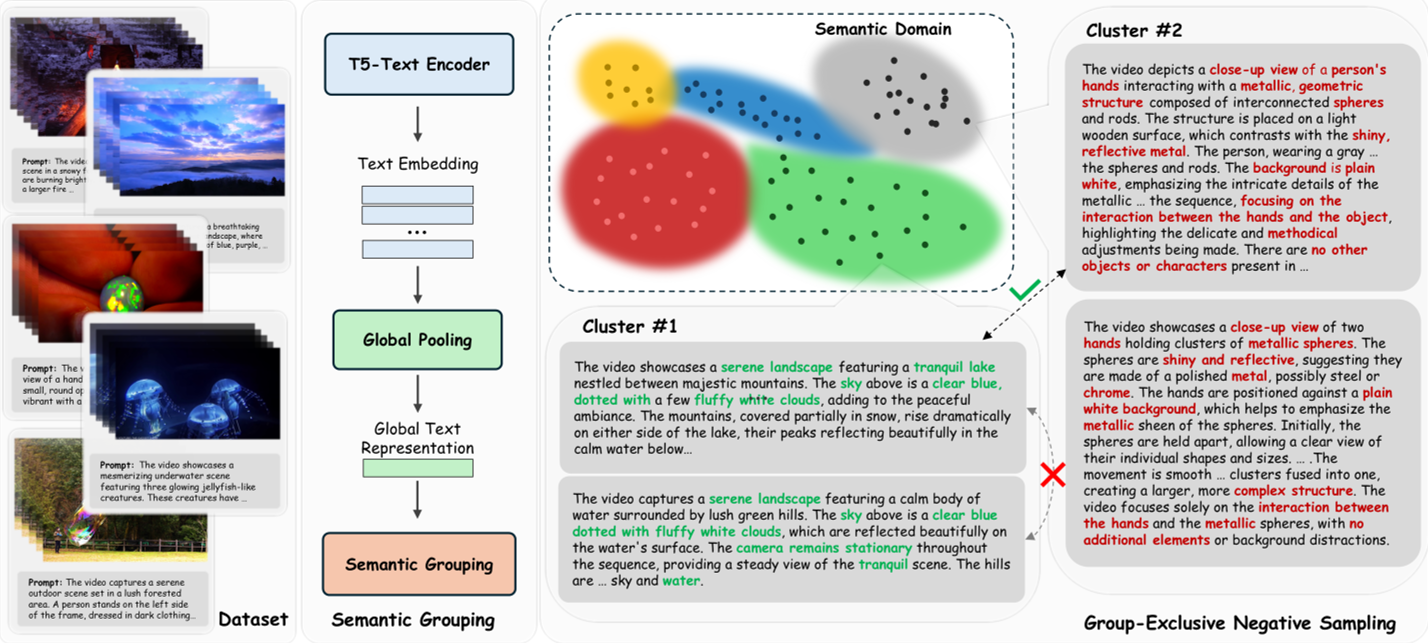 Figure 1: The DiReCT Pipeline. Note the dual-scale negative sampling (Macro vs. Micro) and the distributional anchoring to maintain visual quality.
Figure 1: The DiReCT Pipeline. Note the dual-scale negative sampling (Macro vs. Micro) and the distributional anchoring to maintain visual quality.
Experiments: David vs. Goliath
The researchers tested DiReCT on Wan 2.1-1.3B. Despite its small size, the results were striking:
- Physical Commonsense: +16.7% improvement.
- WorldModelBench: Achieved a score of 5.68, beating CogVideoX-5B (5.33) and Mochi-10B (4.91).
- Efficiency: The training adds zero cost to inference and only a tiny 31% memory overhead during the one-time post-training phase.
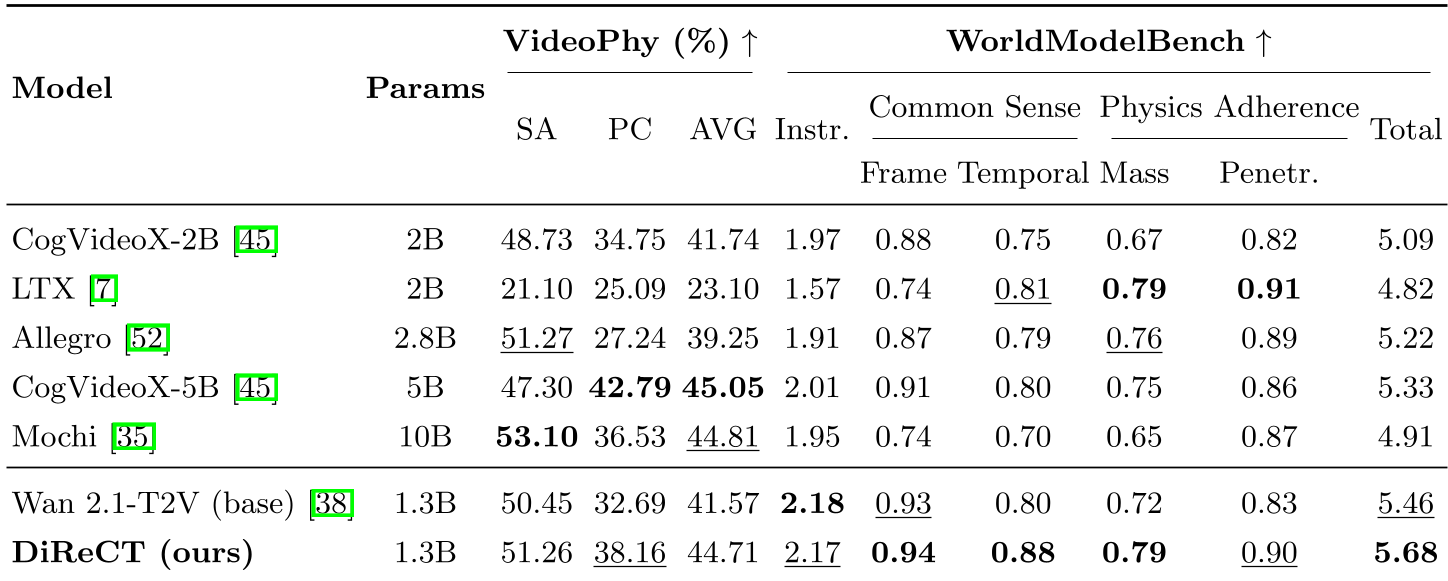 Table 1: DiReCT consistently outperforms larger models across physical adherence metrics like Mass Conservation and Penetration.
Table 1: DiReCT consistently outperforms larger models across physical adherence metrics like Mass Conservation and Penetration.
Why it Works: The Math of Alignment
The paper provides a rigorous mathematical proof (Proposition 1) showing that when a positive and negative sample are too semantically similar, the gradients point in opposite directions, effectively canceling out the learning. DiReCT fixes this "self-interference" by ensuring that the velocity gap (δ) is concentrated specifically on the physics-relevant subspace.
 Figure 2: Qualitative results. In the bottom row, notice how DiReCT maintains the integrity of the yogurt and the spoon, whereas baseline models cause the objects to merge or behave like rigid blocks.
Figure 2: Qualitative results. In the bottom row, notice how DiReCT maintains the integrity of the yogurt and the spoon, whereas baseline models cause the objects to merge or behave like rigid blocks.
Summary & Future Outlook
DiReCT proves that we don't always need more data or more parameters to make AI "smarter" about the real world. By intelligently structuring how we contrast "right" vs. "wrong" motion, we can refine existing models into capable world simulators.
Limitations: The framework currently relies on LLMs to generate high-quality text perturbations. If the LLM fails to understand the physics itself, the negative samples might be weak. Future work may explore automated ways to detect physical violations directly from pixels to further close this loop.