本文提出了 DMax,一种旨在解决扩散语言模型 (dLLM) 并行解码中误差累积问题的新型范式。通过引入 On-Policy Uniform Training 和 Soft Parallel Decoding,DMax 在 LLaDA-2.0-mini 基础上显著提升了解码并行度,不仅将推理速度(TPS)提升至 1338 以上,还在 GSM8K 和 MBPP 等任务上实现了 2-3 倍的 TPF(Tokens Per Forward)增长,且几乎无损生成质量。
1. 核心速览 (Executive Summary)
TL;DR:DMax 是一种针对扩散语言模型 (dLLM) 的高效解码范式。它通过 On-Policy Uniform Training (OPUT) 解决训练与推理不一致的痛点,并利用 Soft Parallel Decoding (SPD) 实现嵌入空间的自纠错,成功克服了长期困扰非自回归模型的“误差累积”问题。
背景定位:在 Autoregressive (AR) 模型统治地位下,dLLM 以并行生成的潜力被寄予厚望。DMax 并非仅仅是微小的 SOTA 刷榜,它针对现有 LLaDA 等模型的根本性设计缺陷(二进制 Mask 转换)提出了变革性的“软修正”方案,使 dLLM 的理论推理优势真正转化为数倍的 TPS 提升。
2. 痛点:为什么强行并行会导致“语义崩溃”?
现有的 Masked Diffusion (MDLM) 在推理时通常遵循一种“开弓没有回头箭”的逻辑:
- 二进制状态:一个位置要么是
[MASK],要么是确定的Token。 - 误差放大:在并行度极高的情况下,模型不可避免会产生错误。由于传统方法将这些初级预测视为固定上下文,错误会像滚雪球一样扩散,最终导致模型生成的文本逻辑混乱。
- 缺乏机制:目前的 dLLM 缺乏类似人类“写了发现不对再改”的回退纠错能力。
3. 核心方案:DMax 的两大法宝
3.1 On-Policy Uniform Training (OPUT):拒绝生搬硬套
传统的 Uniform Training 使用随机采样的 Token 作为噪声,但这与模型实际推理时的错误分布天差地别。
- 直觉:让模型在训练阶段就接触到“自己产生的错误”。
- 实现:采样 corruption level ,生成 Mask 序列进行 Parallel Forward,提取模型生成的 Predicted Noise,再以此作为输入进行第二次 Forward。这种 On-Policy(同策略) 的方式能让模型学会从真实的错误上下文捕捉修正信号。
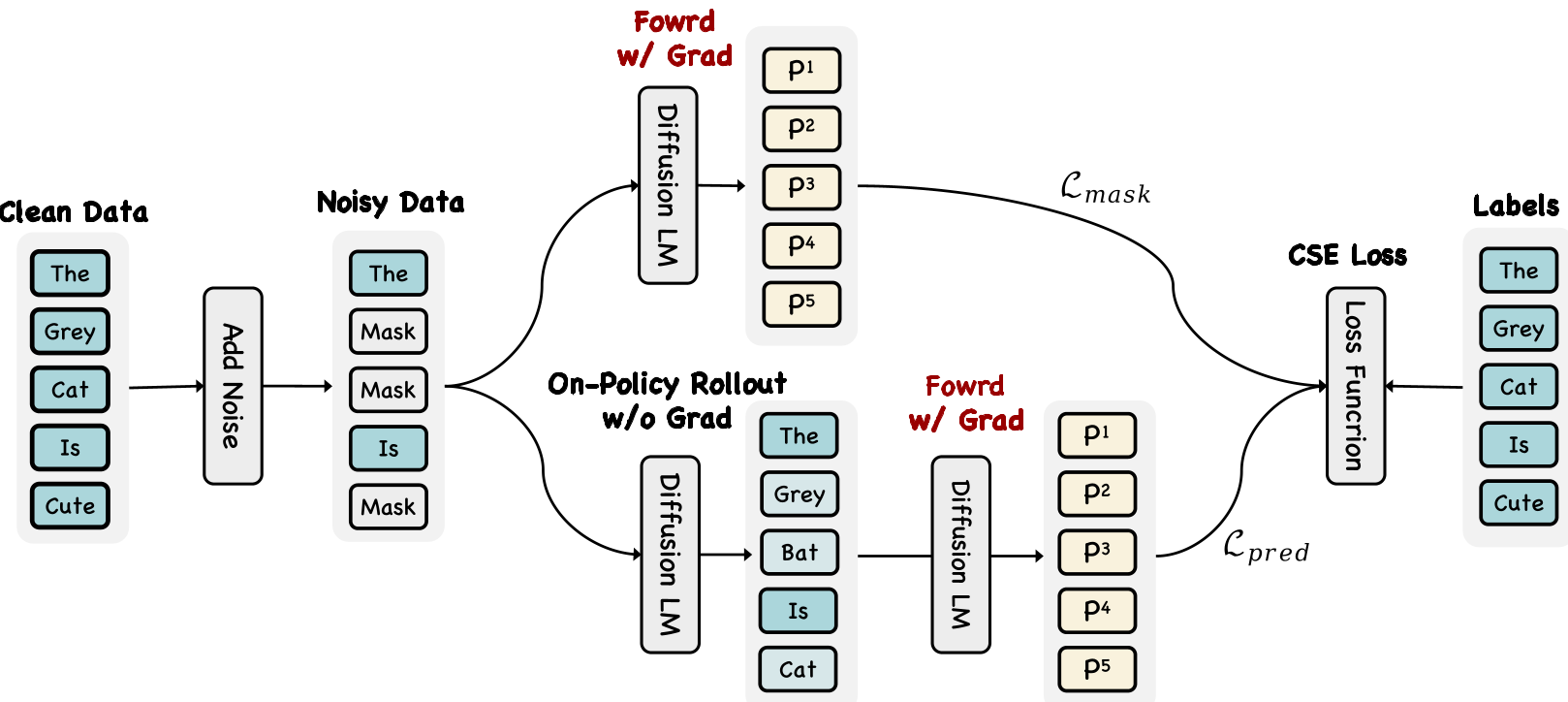
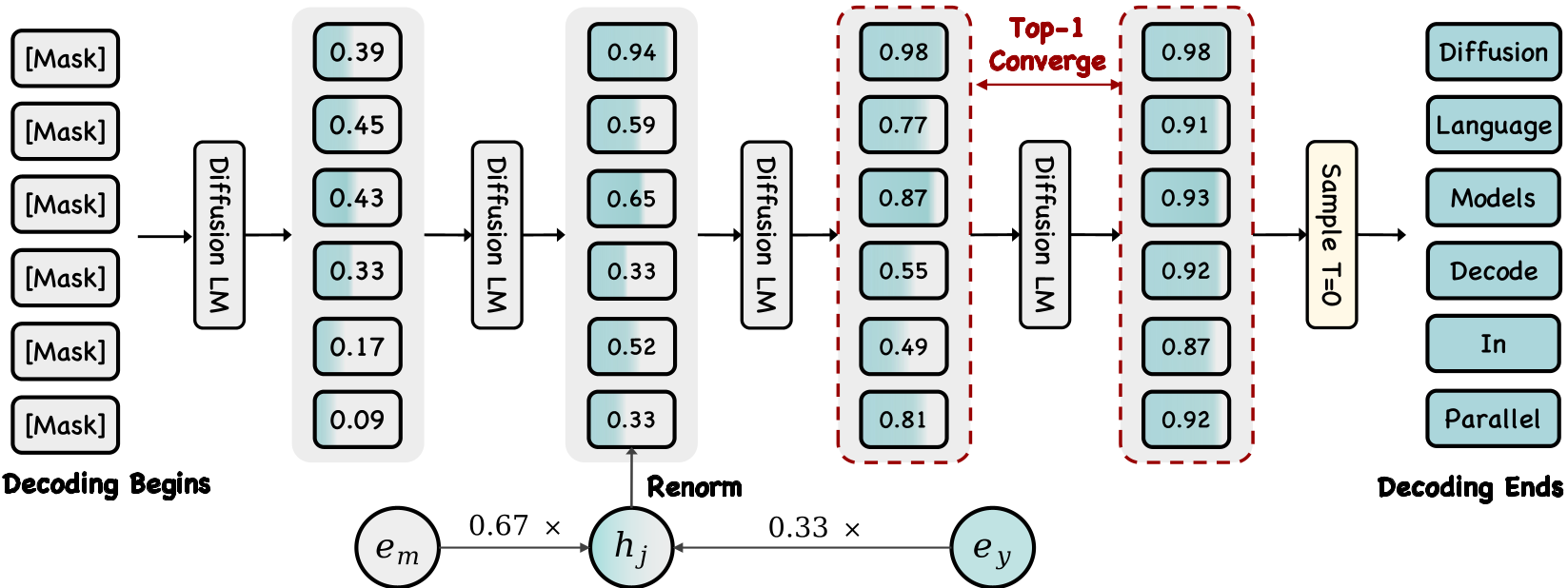
3.2 Soft Parallel Decoding (SPD):给预测留点余地
这是 DMax 最具学术美感的创新。它不再强求模型立即做出“是或否”的判定,而是:
- 混合嵌入 (Hybrid Embedding):将中间状态定义为预测 Token 与 Mask 的线性加权插值,权重由预测置信度 决定。
- 软自修复:在高维空间中,这种插值保留了不确定性,允许模型在后续迭代中平滑地修正之前的低置信度预测。
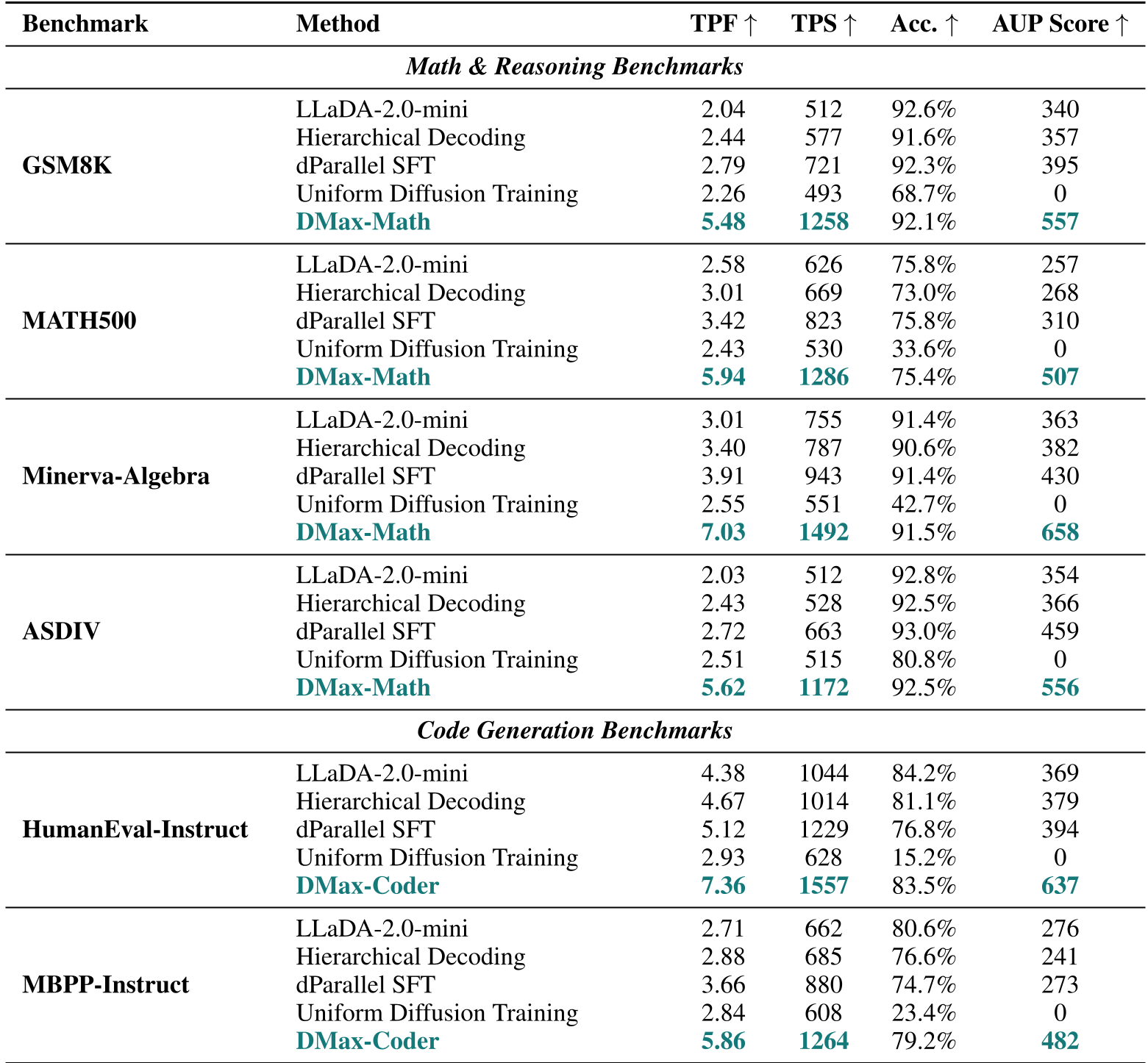
4. 实验与结果:速度与质量的兼得
DMax 在 LLaDA-2.0-mini 基座上展现出了惊人的效率:
- 速度飙升:在 GSM8K 数学推理任务上,TPF (Tokens Per Forward) 从 2.04 飙升至 5.48,在代码生成 MBPP 任务中从 2.71 提升至 5.86。
- 精度稳健:与基准模型相比,DMax 即使加大了并行力度,其准确率几乎没有下降(甚至在低并行模式下利用纠错机制提升了 0.8%-3.0% 的 Accuracy)。
5. 深度洞察与总结 (Critical Analysis)
核心洞察:DMax 的成功意味着扩散模型的并行效率瓶颈并不在 Transformer 架构本身,而在 输入表征的离散性。通过将 [MASK] 视为“最大不确定性”并以此构建连续的修正路径,DMax 真正释放了非自回归模型的理论潜能。
局限性:
- 该方法对训练数据的质量(Self-distillation Data)有一定依赖。
- 在处理极其复杂的逻辑长链时,多次迭代自修复的计算开销仍需进一步优化以达到最优性价比。
未来展望: DMax 确立了 dLLM 并行解码的新基准。这种“软状态演化”的思想极有可能在未来扩展到多模态(Vision-Language-Action)任务中,为实时交互式的 AI 智能体提供极低延迟的生成能力。