This paper introduces the Dream Diffusion Policy (DDP), a visuomotor control framework that integrates a diffusion-based world model with a diffusion policy via a shared 3D visual encoder. DDP achieves state-of-the-art robustness by detecting out-of-distribution (OOD) states and switching to an "imagination" mode for trajectory generation, reaching a 73.8% success rate on MetaWorld OOD tasks.
TL;DR
Even the most advanced AI-controlled robots often "panic" when something unexpected happens—like a camera being blocked or an object being moved suddenly. Dream Diffusion Policy (DDP) solves this by giving robots an internal "imagination." By training a World Model alongside the control policy, DDP allows a robot to detect when its eyes are deceiving it and switch to internal simulations to complete its task safely.
Academic Positioning: This work upgrades the popular Diffusion Policy (DP3) from a reactive controller to a predictive agent capable of handling catastrophic Out-of-Distribution (OOD) shifts.
The Fragility of Sight: Why Current Robots Fail
Current state-of-the-art visuomotor policies are deeply "tethered" to their visual feed. If an object is moved mid-task or a camera is occluded, the input features shift out of the distribution the model saw during training. Without a sense of object permanence or physical intuition, the robot's policy collapses, leading to "compounding errors" where one small slip leads to a total failure.
Previous attempts like domain randomization or test-time adaptation often overwrite the expert's original skills or require heavy computation that isn't feasible for real-time control.
Methodology: The Power of Predictive Regularization
The core innovation of DDP is the tight coupling of a Diffusion Policy and a Diffusion World Model through a shared 3D visual encoder (PointNet + MLP).
1. Co-Optimization Training
Instead of training the world model as a separate auxiliary task, DDP uses it as a regularizer. The World Model is forced to predict future latent states ($O_{M...M+N-1}$) based on current history and planned actions. This forces the shared encoder to learn robust geometric and physical priors that are useful for both seeing and dreaming.
2. The OOD Detector: Real vs. Imagination
DDP monitors a metric called Real-Imagination Discrepancy ($D_{R-I}$). $$ \mathcal{D}{R-I}(t) = | \mathbf{O}{real}^{t} - \mathbf{O}_{pred}^{t} |_2^2 $$ When the real observation deviates significantly from what the internal world model predicted, the robot flags an OOD state.
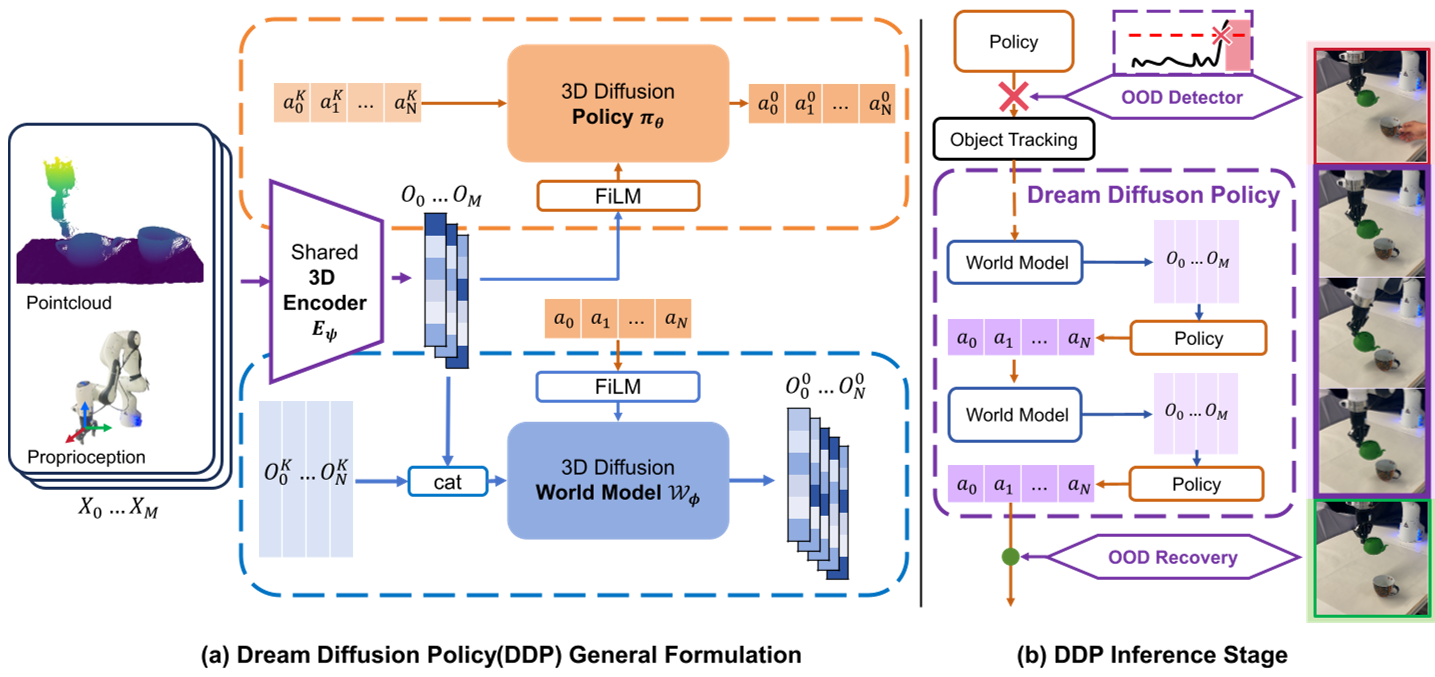 Figure 1: The DDP framework showing the shared encoder and the dual-stream policy/world model architecture.
Figure 1: The DDP framework showing the shared encoder and the dual-stream policy/world model architecture.
The "Dream" Loop: Recursive Imagination
Once OOD is detected, DDP enters a "Dreaming" state. It stops trusting the camera and starts an autoregressive loop:
- The World Model predicts the next latent state.
- The Diffusion Policy uses that predicted (imagined) state to generate the next action.
- The cycle repeats.
This allows the robot to "close its eyes" and finish a subtask (like reaching for a handle) based on where it thinks the handle is, even if the camera is currently blocked or the handle has been moved to a new static position.
Experimental Battleground
The researchers tested DDP against SOTA baselines (DP3 and FlowPolicy) across MetaWorld and real-robot tasks (Stacking, Pouring, Pressing).
SOTA Comparison
In MetaWorld OOD tests, standard policies virtually dropped to 0% success. Even when baselines were augmented with tracking, they only hit ~23.9% success. DDP reached 73.8%, proving that "imagination" is vastly superior to simple tracking when it comes to maintaining task coherence.
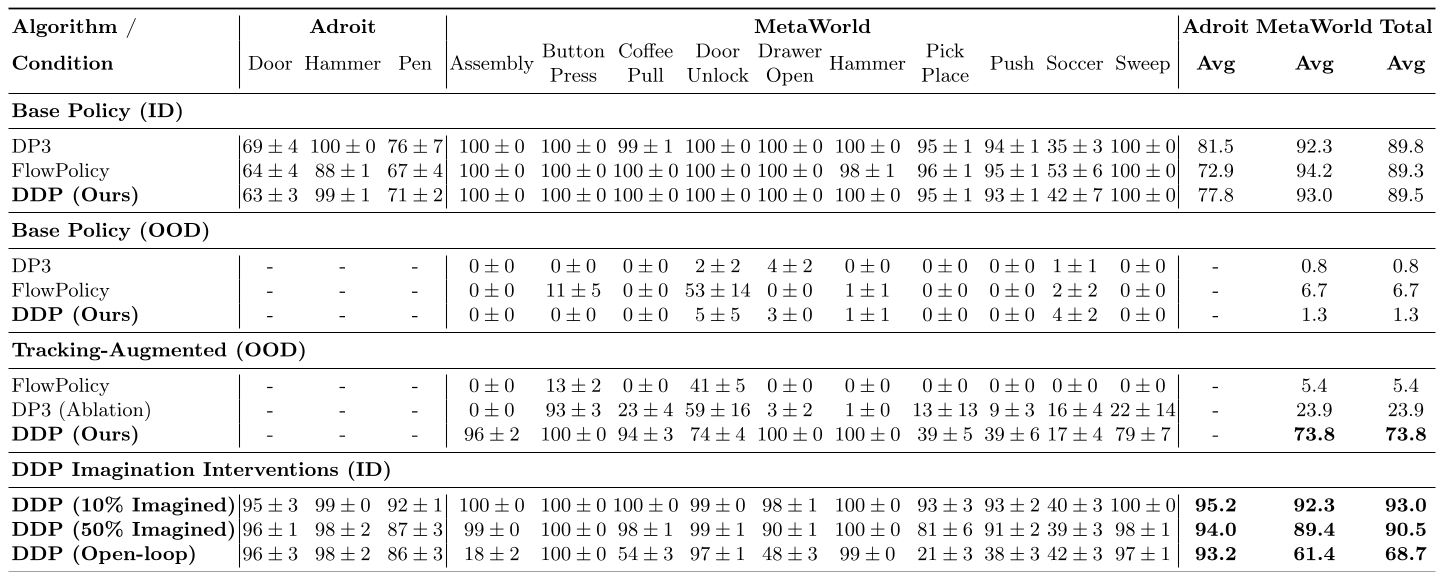 Table 1: Performance comparison showing DDP's dominance in OOD scenarios.
Table 1: Performance comparison showing DDP's dominance in OOD scenarios.
The Blind Test (Open-loop)
In a remarkable "stress test," the robot was made to operate 100% blindly after the first observation. In the real world, DDP maintained a 76.7% success rate, demonstrating that its internal physical "hallucinations" are stable enough for high-precision tasks like pouring tea or stacking blocks.
 Figure 2: DDP successfully completing tasks under severe occlusion and displacement where baselines fail.
Figure 2: DDP successfully completing tasks under severe occlusion and displacement where baselines fail.
Critical Insight & Future Outlook
DDP shifts the paradigm from "better vision" to "better intuition." By building a model that can predict its own future sensory inputs, we create a layer of resilience that mirrors biological motor control.
Current Limitations:
- Initial State Anchor: The task must start In-Distribution to "anchor" the world model.
- Tracking Drift: Over very long horizons, the "dream" might drift from physical reality.
- Low-level Disruptions: It still struggles with tactile-based errors like a gripper slipping.
The Takeaway: For robotics to move into unstructured homes and factories, they cannot just be reactive mimics; they must be dreamers that can anticipate the world even when it disappears from view.