DreamPlan is a novel framework for efficiently fine-tuning Vision-Language Model (VLM) planners for complex robotic tasks like deformable object manipulation. It utilizes an action-conditioned video world model to simulate physical dynamics, allowing for reinforcement learning via Odds Ratio Policy Optimization (ORPO) entirely within a "virtual imagination" rather than costly real-world trials.
TL;DR
Large Vision-Language Models (VLMs) are great at reasoning but terrible at physics. They might know that a cloth needs folding, but they don't know how the fabric will bunch up when pulled. DreamPlan solves this by training a video world model to act as a "mental simulator." By practicing in this virtual imagination using Odds Ratio Policy Optimization (ORPO), a VLM planner can learn complex deformable object manipulation without the risk or cost of real-world failure.
Background: The Gap Between Semantics and Physics
While zero-shot VLMs like GPT-4o or Qwen-VL can generate high-level plans, they often suffer from a lack of physical grounding. In tasks involving deformable objects (rope, cloth, soft toys), the dynamics are highly non-linear. A millimeter of difference in a "grasp-and-pull" action can result in a completely different topological state.
Current solutions usually rely on simulators (like SoftGym), but these often fail the "sim-to-real" test. DreamPlan takes a different route: Learning the simulator itself from real-world video data.
Methodology: Dreaming of Success
The DreamPlan pipeline consists of three distinct stages:
1. Exploratory Data Collection
The system uses a zero-shot VLM to perform random or sub-optimal interactions in the real world. Even if the robot fails to fold the cloth, the resulting video data is a goldmine for learning causality—it shows the world model exactly how the object reacts to specific forces.
2. The Action-Conditioned World Model
To make the world model "controllable," the authors rendered the kinematic configuration of robot arms as visual cues. Using a ControlNet architecture integrated with the CogVideoX-5B diffusion backbone, the model learns to predict object deformation based on these rendered trajectories.
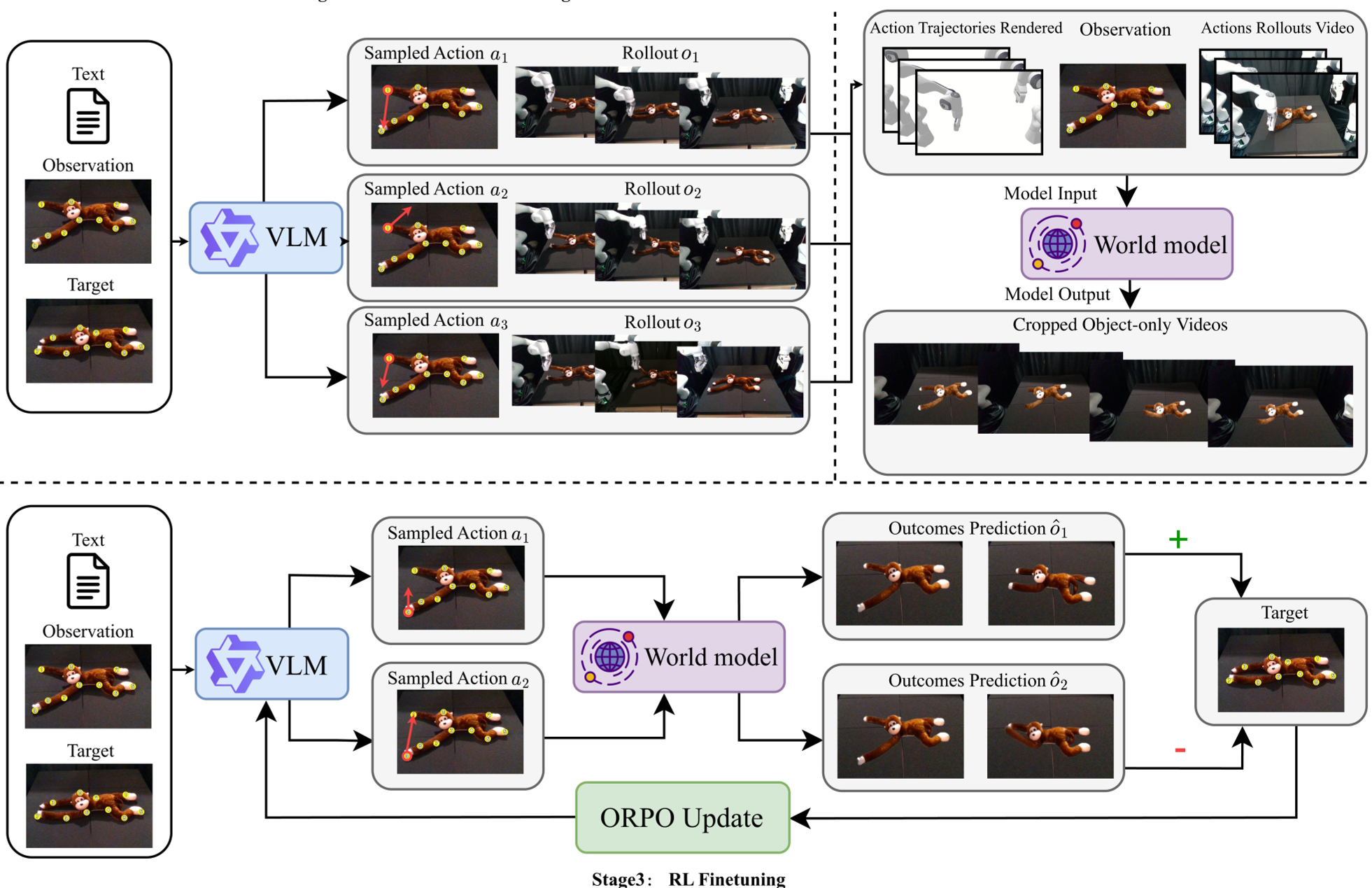 Fig 1: The DreamPlan framework—from zero-shot proposals to world model training and preference-based alignment.
Fig 1: The DreamPlan framework—from zero-shot proposals to world model training and preference-based alignment.
3. Policy Alignment via Imagination
Instead of slow, online RL, DreamPlan uses a Best-of-K strategy:
- The VLM proposes possible actions.
- The World Model "dreams" the outcome for each.
- A high-level evaluator (like GPT-4o) picks the best visual outcome.
- The VLM is fine-tuned using ORPO to prefer the successful action over the failures.
Experimental Results: Small Models, Big Performance
The most striking result is the efficiency gain. By "internalizing" the physics during fine-tuning, the VLM no longer needs to query the world model at inference time.
- Performance Boost: DreamPlan improved success rates by up to 40% over zero-shot baselines.
- Model Scaling: A fine-tuned 8B model (Qwen3-VL-8B) consistently beat the 32B version of the same model that hadn't undergone "imagination training."
- Speed: Inference time dropped from ~900 seconds (using explicit verification) to 1.12 seconds.
 Fig 2: Qualitative comparisons show that DreamPlan's world model (top) generates much more physically plausible deformations than standard video generation baselines.
Fig 2: Qualitative comparisons show that DreamPlan's world model (top) generates much more physically plausible deformations than standard video generation baselines.
Critical Analysis: Why This Matters
The core insight of DreamPlan is that sub-optimal data is sufficient for world modeling. You don't need expert demonstrations to learn how physics works; you just need to see enough examples of "if I do X, Y happens."
Limitations:
- The current framework still requires a few hundred real-world trajectories (approx. 4 hours) to train the initial world model.
- As a "discrete" keypoint-based planner, it may struggle with tasks requiring continuous, high-frequency reactive control (like catching a falling object).
Conclusion
DreamPlan provides a blueprint for the next generation of "Physically Intelligent" agents. By decoupling the learning of physics (via video models) from the learning of policy (via ORPO), it achieves a level of sample efficiency and grounded reasoning that zero-shot foundation models currently lack.
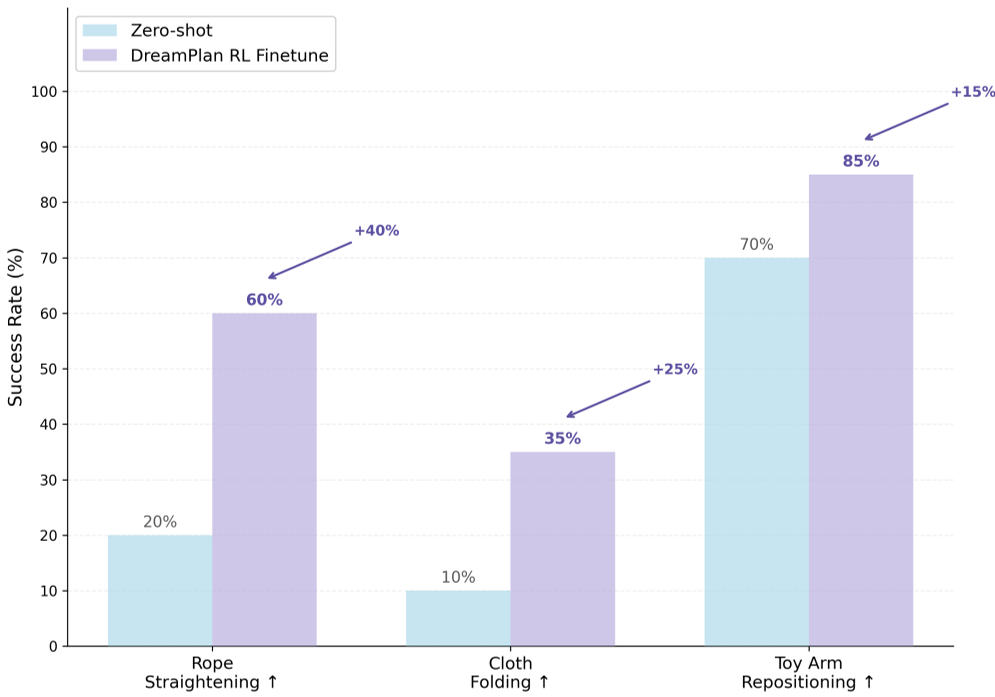 Fig 3: Success rate improvements across various deformable manipulation tasks.
Fig 3: Success rate improvements across various deformable manipulation tasks.