This paper introduces Drifting Field Policy (DFP), a novel one-step generative policy for RL finetuning that bypasses ODE-based trajectories. By framing policy updates as a Wasserstein-2 gradient flow, DFP achieves State-of-the-Art performance on Robomimic and OGBench, outperforming diffusion and flow-based policies in both efficiency and success rate.
TL;DR
While Diffusion and Flow-matching have dominated the generative policy landscape, they suffer from a "structural burden": they model actions as the end-point of an ODE trajectory. Drifting Field Policy (DFP) breaks this by treating policy updates as a direct Wasserstein-2 Gradient Flow in probability space. This eliminates the need for time-indexed velocity fields, allowing 1-step policies to match or beat multi-step SOTA on complex manipulation tasks with significantly faster finetuning.
Problem & Motivation: The ODE Tax
Most modern robotic policies are "trapped" in time. Whether using Diffusion or Flow-matching, the model essentially predicts a velocity that integrates into an action. When we try to finetune these models with Reinforcement Learning (RL), we face a credit assignment nightmare: the reward is achieved at the action level, but the gradient must flow back through every "virtual" timestep of the ODE.
Even "1-step" distillation models (like Consistency Models or MeanFlow) carry this baggage because their training objective is still defined along that trajectory. The authors identify this as the reason online adaptation is often slow and unstable for generative agents.
Methodology: The Power of the Drifting Field
DFP replaces the ODE with a Drifting Model. In this paradigm, a single-pass network maps a noise prior directly to an action. The "training magic" happens through a Drifting Field .
1. The Physical Intuition
Think of the policy distribution as a cloud of particles.
- Attraction (): Pulls particles toward "good" high-reward actions.
- Repulsion (): Pushes particles away from the current distribution to prevent mode collapse.
2. Wasserstein Gradient Flow
The authors prove that this drifting field is equivalent to the steepest-descent direction toward an optimal policy (the "Soft Target") in the space of probability measures. Mathematically, they decompose the update into:
- A Ascent: Moving toward higher value.
- A Score Matching Regularizer: Keeping the update within a trust region.
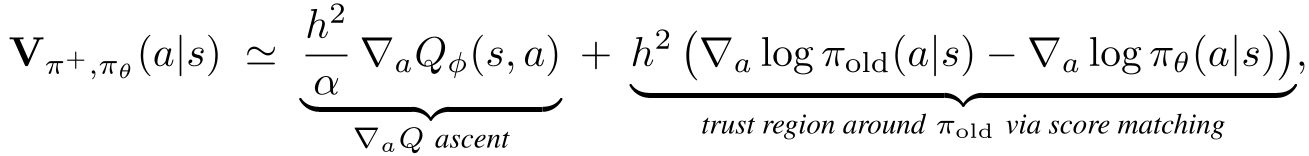 The structural decomposition of the DFP update, showing the Q-ascent and trust-region components.
The structural decomposition of the DFP update, showing the Q-ascent and trust-region components.
3. The Top-K Surrogate
Since the "ideal" target policy is mathematically intractable, DFP uses a clever trick: it samples candidates, picks the Top-K based on the Critic (), and uses those as the "attractive" targets for the drifting field. This makes the implementation remarkably simple—almost like Behavior Cloning on self-generated "best" actions.
Experiments & Results
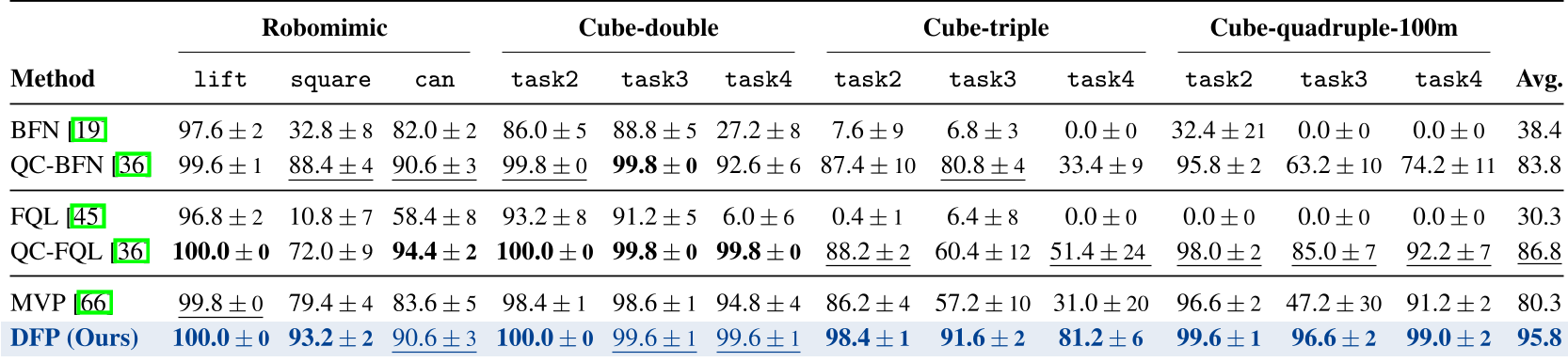
The authors tested DFP on 12 demanding tasks across Robomimic and OGBench.
SOTA Performance
DFP achieved an average success rate of 95.8%, dominating baselines like QC-FQL and MVP (Mean Velocity Policy). In complex tasks like cube-triple-task4 and cube-quadruple-task3, DFP showed a massive jump in performance (e.g., from ~47% to ~96%).
Why Drifting Beats MeanFlow
An ablation study revealed a key insight: when applying the same "Top-K" supervision to an ODE-based backbone (MeanFlow), the gains were marginal (+2.4 pp). However, on the Drifting backbone, the gain was substantial (+7.4 pp). This confirms that probability-space descent is fundamentally more compatible with RL rewards than velocity-field re-fitting.
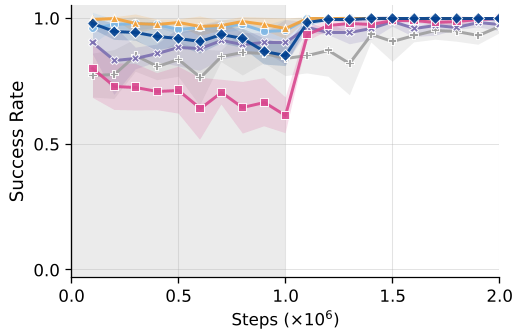 DFP (purple) shows markedly faster and higher convergence compared to the MeanFlow-based MVP (red) across various tasks.
DFP (purple) shows markedly faster and higher convergence compared to the MeanFlow-based MVP (red) across various tasks.
Critical Analysis & Conclusion
Takeaways
- Direct is Better: For 1-step policies, eliminating the ODE simplifies the optimization landscape significantly.
- Innate Diversity: The built-in repulsion mechanism of Drifting models naturally handles multimodality without the overhead of diffusion.
Limitations
- Critic Dependence: Like all actor-critic methods, DFP's performance is capped by the quality of the learned Q-function.
- Sim-to-Real: While the results in simulation are stunning, the impact of real-world noise on the kernel-based drifting field remains to be seen.
In conclusion, DFP represents a significant pivot in generative robot control. By moving from "simulating a process" to "flowing a distribution," it provides a more robust and efficient foundation for agents that must learn and adapt in the real world.