DriveTok is a novel 3D driving scene tokenizer designed to unify multi-view image reconstruction and scene understanding into a compact, fixed-budget set of tokens. By lifting 2D features into a 3D-aware representation using deformable cross-attention and visibility-guided transformers, it achieves SOTA performance in 3D occupancy prediction and metric depth estimation on the nuScenes dataset.
TL;DR
DriveTok is a 3D driving scene tokenizer that compresses high-resolution, multi-view camera inputs into a unified, fixed-size set of tokens. Unlike traditional 2D per-image tokenizers, DriveTok uses 3D deformable attention and visibility-guided transformers to ensure geometric consistency. The result is a single representation that excels at both visual reconstruction and 3D semantic understanding, achieving a 33.32 IoU in 3D occupancy and a remarkably low 0.08 AbsRel in depth prediction.
Motivation: The Fragmentation of Driving Representations
Current autonomous driving stacks often face a "modality gap." Perception modules produce sparse object lists or voxels, while newer World Models and Vision-Language-Action (VLA) Models require dense visual tokens. However, tokenizing six high-resolution 2D images independently is:
- Inconsistent: Objects at camera overlaps are "cut" and represented by unrelated tokens.
- Inefficient: Redundant tokens are created for the same spatial region seen from different angles.
- Geometry-Blind: Standard tokens don't "know" their position in 3D space, which is critical for safe driving.
DriveTok solves this by moving the tokenization process from the 2D image plane to an ego-centric 3D scene grid.
Methodology: Lifting Semantics into 3D Space
The DriveTok architecture consists of three sophisticated phases:
1. Semantic-Rich 3D Encoding
The system uses a DINOv3 vision foundation model to extract deep semantic features. These are not merely 2D patches; they are "lifted" into a global scene grid using 3D Deformable Cross-Attention. This allows the model to sample relevant image regions based on the camera's intrinsic and extrinsic parameters, creating tokens that are independent of the specific camera layout.
2. Spatial-Aware Multi-View Decoder
This is the "secret sauce" of DriveTok. To reconstruct images from 3D tokens, the model must map 3D information back to 2D viewports. The authors introduce Visibility-Guided Attention. By pre-computing which 3D cells are actually visible from which camera, they apply a hard binary mask to the Transformer's attention mechanism.
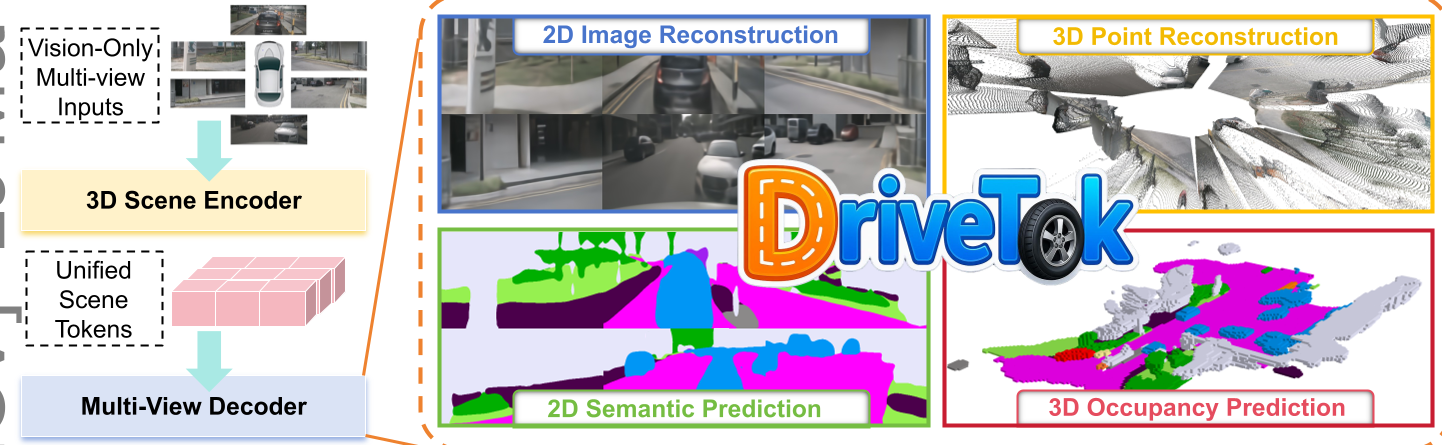 Fig 1: The unified pipeline showing the flow from multi-view inputs to localized 3D scene tokens and back to various task outputs.
Fig 1: The unified pipeline showing the flow from multi-view inputs to localized 3D scene tokens and back to various task outputs.
3. Joint Multi-Task Training
To ensure the tokens are "all-rounders," the paper employs five distinct loss functions:
- RGB Reconstruction: Using GAN and LPIPS losses for textural fidelity.
- Metric Depth: Anchored by sparse LiDAR but densified via MoGe-2 pseudo-labels.
- 3D Occupancy: Predicting semantic labels in 3D voxels.
- Semantic Prediction: Sparse LiDARSeg supervision.
- Semantic Regularization: Aligning the latent token space with explicit semantic structures to prevent "structure corruption."
Experiments: Breaking the SOTA
The researchers evaluated DriveTok on the nuScenes dataset. The results demonstrate a significant leap in holistic scene understanding.
Performance Highlights:
- 3D Occupancy: Reached 33.32 IoU, outperforming specialized models like TPVFormer and QuadricFormer.
- Depth Prediction: Achieved an AbsRel of 0.08. For context, most contemporary monocular foundation models sit between 0.20 and 0.40 on the same task.
- Efficiency: Despite processing 6 cameras, the tokenization process takes only ~88ms on an A800 GPU.
 Table 1: Occupancy prediction performance. DriveTok achieves superior mIoU and IoU compared to leading geometric models.
Table 1: Occupancy prediction performance. DriveTok achieves superior mIoU and IoU compared to leading geometric models.
Ablation Insight: Why Visibility Matters
The ablation study on "Visibility-Guided Attention" (Table 5 in the paper) reveals its critical role. Without the visibility mask, scene tokens overfit to 2D image textures, causing a catastrophic drop in 3D occupancy IoU (from 12.81 down to 5.32). The mask forces the model to learn inductive geometric biases rather than just memorizing pixel colors.
Critical Insight & Conclusion
DriveTok represents a shift toward unified visual interfaces. By decoupling the representation from the "sensor rig" (resolution and camera count) and anchoring it in 3D space, it provides the perfect data format for the next generation of LLM-based drivers.
Takeaway: If you want a model to reason about "the car behind the pillar," its tokens must inherently understand that the pillar and the car coexist in a shared 3D volume, not just as adjacent pixels in a flattened 2D array. DriveTok provides the blueprint for this shared spatial memory.
Future Outlook: Integrating temporal modeling (4D) to allow the tokens to represent motion and scene evolution will be the next frontier for this architecture.