本文提出了 DriveTok,一种专为自动驾驶设计的 3D 场景分词器(Tokenizer)。该方法通过 3D 可变形交叉注意力机制将多视图图像转换为统一且紧凑的 Scene Tokens,在重建质量与 3D 语义占据预测(Occupancy Prediction)上均达到了 SOTA 水平。
TL;DR
随着自动驾驶从“感知中心”转向“推理中心”,现有的 2D 图像 Tokenizer 已经无法满足 VLM/VLA 模型对空间几何一致性的严苛要求。清华大学等机构的研究者提出了 DriveTok,一种革命性的 3D 场景分词器。它将多目相机流压缩为一组固定的、具备 3D 几何意识的 Scene Tokens,不仅实现了高保真的多视图重建,更在 3D 语义占据预测和深度预测上刷新了记录。
1. 为什么我们需要 3D 形式的驱动分词器?
在 VLA(视觉-语言-动作)模型视角下,传感器数据是对话的“背景”。如果每个摄像头的画面被独立 Tokenize:
- 数据冗余:重叠区域被多次编码,计算成本随分辨率暴增。
- 空间断裂:多视图之间缺乏几何约束,模型难以理解“左前方摄像头里的车”与“前方摄像头里的车”是同一个物理实体。
- 几何缺失:传统的语义 Token 往往丢失了对距离和三维结构的精确表达。
DriveTok 的核心直觉是:分词过程应在 3D 空间中完成。 无论你有 6 个还是 10 个摄像头,生成的 Token 数量应该是固定的,且每个 Token 对应物理世界中的一个特定空间位置。
2. 核心架构:从视觉到几何的飞跃
DriveTok 的流水线包含三个关键步骤:
2.1 3D Scene Encoder ( lifting 项)
利用预训练的 DINOv3 获取语义特征,通过 3D Deformable Cross-Attention(可变形交叉注意力)将 2D 像素映射到 3D 空间的 Grid 序列上。
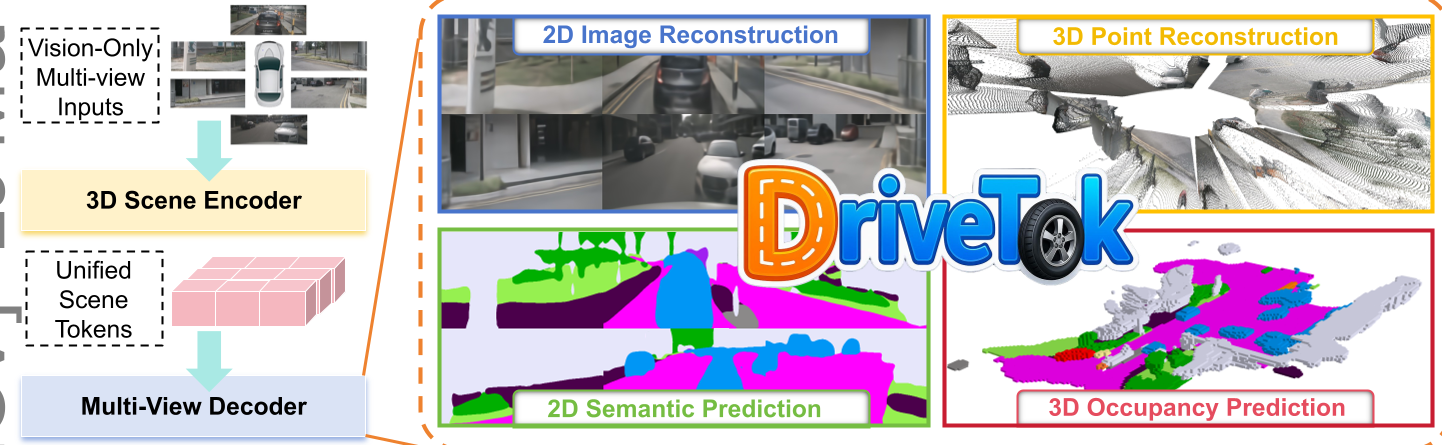 图 1:DriveTok 总体框架,展示了从多视角图像到统一 Scene Tokens 的转换及下游任务分支。
图 1:DriveTok 总体框架,展示了从多视角图像到统一 Scene Tokens 的转换及下游任务分支。
2.2 Visibility-Guided Decoder (空间意识的核心)
这是本文最具启发性的设计。在 Transformer 解码过程中,作者引入了 可见性限制(Visibility Constraint)。通过物理映射预计算掩码(Mask),确保 Scene Token 只能看到其实际被投影到的像素区域。
- 物理直觉:如果不加限制,模型会尝试学习全局纹理,导致 Token 过拟合而丢失几何含义。
- Plücker Ray Embedding:在 View Tokens 中注入光线特征,帮助模型在 3D 空间中消除歧义。
2.3 联合任务训练
为了让生成的 Token “全知全能”,DriveTok 引入了五元损失函数:
- 重建 (RGB):确保纹理细腻。
- 深度 (Depth):利用生成的伪标签建立度量尺度感(Metric Scale)。
- 语义 (Semantic):注入类别认知。
- 占据 (Occupancy):强化 3D 空间结构理解。
- 语义正则化 (Latent Reg):防止 Latent 空间发生结构崩塌。
3. 实验战绩:全方位的 SOTA
DriveTok 在 nuScenes 数据集上展示了极强的通用性。
3.1 3D 占据预测与深度表现
相比于专注于特定任务的模型(如 BEVFormer, GaussianFormer),DriveTok 作为一个通用的 Tokenizer,其 IoU 到达了 33.32,甚至超过了许多专用感知模型。在深度预测任务中,其 AbsRel(绝对相对误差)低至 0.08,远优于 Metric3D-V2 等强基线。
 表 1:在 3D 语义占据预测任务上的性能对比,DriveTok 展现了显著的 IoU 优势。
表 1:在 3D 语义占据预测任务上的性能对比,DriveTok 展现了显著的 IoU 优势。
3.2 消融实验:可见性的关键作用
消融研究(Table 5)表明,如果没有 Visibility-Guided Attention,模型在占据预测上的 IoU 会从 12.81 跌至 5.32。这再次验证了:在 3D 重建中,引入正确的物理几何偏置(Inductive Bias)比单纯增加参数量更重要。
4. 深度洞察:自动驾驶的“新坐标系”
DriveTok 的意义不仅在于刷榜,它为自动驾驶大模型提供了一个解耦的坐标系:
- 分辨率无关性:随着传感器升级到 8MP,后端推理模型无需重新训练,只需更新 Encoder。
- 语义结构化:通过 PCA 可视化可以看到,DriveTok 的潜在空间展现了极佳的语义聚集性,这对于后续接入 LLM 进行常识推理至关重要。
5. 局限性与展望
尽管表现强劲,DriveTok 的计算开销主要集中在 Transformer Decoder 阶段(约 225ms)。对于实时性要求极高的端到端闭环控制,如何进一步轻量化 Decoder 是一大挑战。 未来,该框架可以轻松扩展到 LiDAR 等多模态融合,并作为 世界模型(World Model) 的生成接口,用于预测复杂交通流中的“反事实”场景。
结论:DriveTok 成功地将“渲染”与“理解”统一在了一组 3D Tokens 中。它不仅是视觉的压缩,更是物理世界的某种程度上的“数字化孪生”,为自动驾驶迈向高阶认知能力铺平了道路。