[TR-C 2025] DriveVLM-RL: Neuroscience-Inspired Dual-Pathway RL for Safe Autonomous Driving
DriveVLM-RL is an end-to-end autonomous driving framework that integrates Vision-Language Models (VLMs) as semantic reward providers for Reinforcement Learning (RL). By employing a neuroscience-inspired dual-pathway architecture, it achieves superior safety and task completion in the CARLA simulator, significantly reducing collision rates compared to traditional and LLM-based baselines.
TL;DR
DriveVLM-RL is a breakthrough reinforcement learning framework that solves the "safety vs. latency" trade-off in autonomous driving. By mimicking the human brain's habitual and deliberative visual pathways, it uses Vision-Language Models (VLMs) to teach a policy how to drive safely during training, but discards the slow VLMs during deployment for real-time performance.
Problem & Motivation: The "Collision" Paradox
Reinforcement Learning (RL) typically learns through trial and error. In driving, "error" means a collision. Requiring an agent to crash thousands of times to understand "crashing is bad" is unacceptable for real-world deployment. Existing "VLM-as-Control" methods (using models like GPT-4 to drive) are too slow, with latencies often exceeding 1 second—far too slow for a vehicle moving at highway speeds.
The authors' key insight: Humans don't think deeply about every frame. We use a fast, habitual system for lane keeping but switch to a slow, deliberative system (Prefrontal Cortex) only when we see a pedestrian stepping onto the road.
Methodology: The Dual-Pathway Architecture
DriveVLM-RL implements this biological intuition through three core components:
1. The Dual-Pathway Reward Logic
- Static Pathway (The Habitual System): Uses CLIP to compare Bird's-Eye-View (BEV) images with fixed "Contrasting Language Goals" (e.g., "clear road" vs. "accident"). This provides a continuous stream of spatial safety signals.
- Dynamic Pathway (The Deliberative System): Uses a YOLOv8 "Attention Gate." If a safety-critical object (pedestrian, cyclist) is detected, it triggers a Large VLM (Qwen3-VL) to perform multi-frame reasoning about intent and risk.
2. Hierarchical Reward Synthesis
The framework doesn't just add rewards; it uses a multiplicative "Shaping Reward." If the semantic safety score is low, the "desired speed" is automatically throttled down. This ensures the agent cannot ignore a pedestrian even if it is maintaining its lane perfectly.
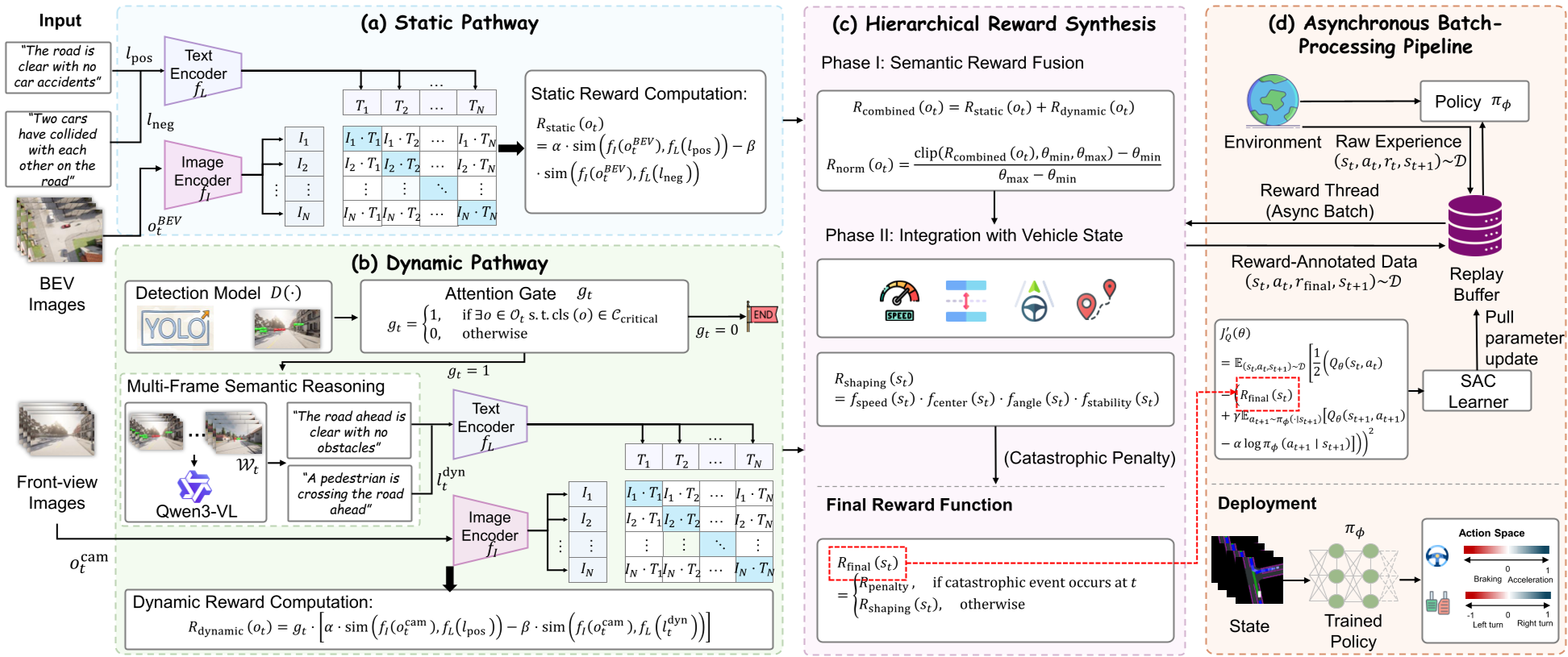
3. Asynchronous Training Pipeline
To prevent the slow LVLM from bottlenecking the RL training, the authors decoupled the environment interaction from the reward annotation. The agent collects data at high speed, while a separate "Reward Thread" grazes the data and annotates it with VLM scores in the background.
Experiments & Results: Learning Safety without Penalties
The authors tested the model in the CARLA simulator against 13 baselines.
- Unprecedented Safety: DriveVLM-RL achieved a collision rate of 0.126, whereas the previous SOTA (VLM-RL) was at 0.407.
- Zero-Penalty Learning: Perhaps the most shocking result was the "No-Reward-After-Collision" experiment. Even when the mathematical penalty for crashing was set to zero, DriveVLM-RL learned to avoid accidents. This proves the agent actually understood the concept of risk rather than just fearing a negative number.

Deep Insight: Why This Matters
The fundamental contribution of DriveVLM-RL is the removal of foundation models at test time. By distillation via reward signals, the final policy is a lightweight neural network capable of running at standard control frequencies (e.g., 20Hz) while possessing the "wisdom" of a multi-billion parameter VLM.
Limitations & Future Work
While successful in urban settings, the model still struggles with highway-style "long-tail" hazards where pedestrian-centric logic doesn't apply. Future work aims to bridge the Sim-to-Real gap and expand the semantic vocabulary to cover more complex highway interactions.
Conclusion
DriveVLM-RL demonstrates that we don't need a "brain-sized" model in the car to drive like a human; we just need a brain-sized model to teach the car how to drive during its "dreams" (simulation training).