本文提出了 dTRPO (Trajectory Reduction Policy Optimization),一种针对扩散大语言模型 (dLLMs) 的高效离线策略优化方法。该方法通过状态缩减和比例缩减技术,仅需单次前向传播即可估算轨迹概率,显著提升了 dLLMs 的对齐效率。
TL;DR
扩散大语言模型 (dLLMs) 虽然在并行解码和双向上下文理解上展现了潜力,但其“后训练 (Post-training)”对齐过程一直因轨迹概率计算过于昂贵而进展缓慢。本文提出的 dTRPO (Trajectory Reduction Policy Optimization) 通过数学证明实现了轨迹的“缩减”,将原本需要数百次的前向传播简化为单次前向计算,在保持离线训练高效性的同时,显著提升了模型在推理、数学和代码任务上的表现。
1. 痛点深挖:为什么扩散模型对齐这么难?
在自回归模型 (ARMs) 中,Token 是一步步生成的,概率计算可以自然地分解为条件概率的乘积:。通过一次前向传播,我们就能拿到所有 Token 的概率。
然而,扩散模型 (dLLMs) 是通过多步由乱码到清晰的去噪过程生成的。要计算一个完整轨迹的概率,理论上需要追踪中间每一个去噪步骤。
- 计算代价高:传统的对齐方法(如在线 RL)需要对每个样本进行数百次推演。
- 数值不稳定:掩码调度 (Masking Schedule) 带来的系数差异巨大,容易导致训练回传梯度爆炸或消失。
2. 核心直觉:从“轨迹”到“新 Token”的缩减
作者发现,虽然单个状态的概率很难求,但在 DPO (直接偏好优化) 框架下,我们需要的是“当前策略”与“参考策略”的概率比 (Probability Ratio)。
关键证明 (Theorem 3.2: Ratio Reduction)
作者证明,在计算两个策略的比例时,所有与掩码调度相关的物理系数会互相抵消。最终,轨迹的概率比竟然可以直接简化为:在每一步中被重新预测出来的(新 Token)的分类概率之比。
这意味着,我们不需要关心复杂的扩散物理过程,只需要关注那些从 [MASK] 变成具体文字的 Token。
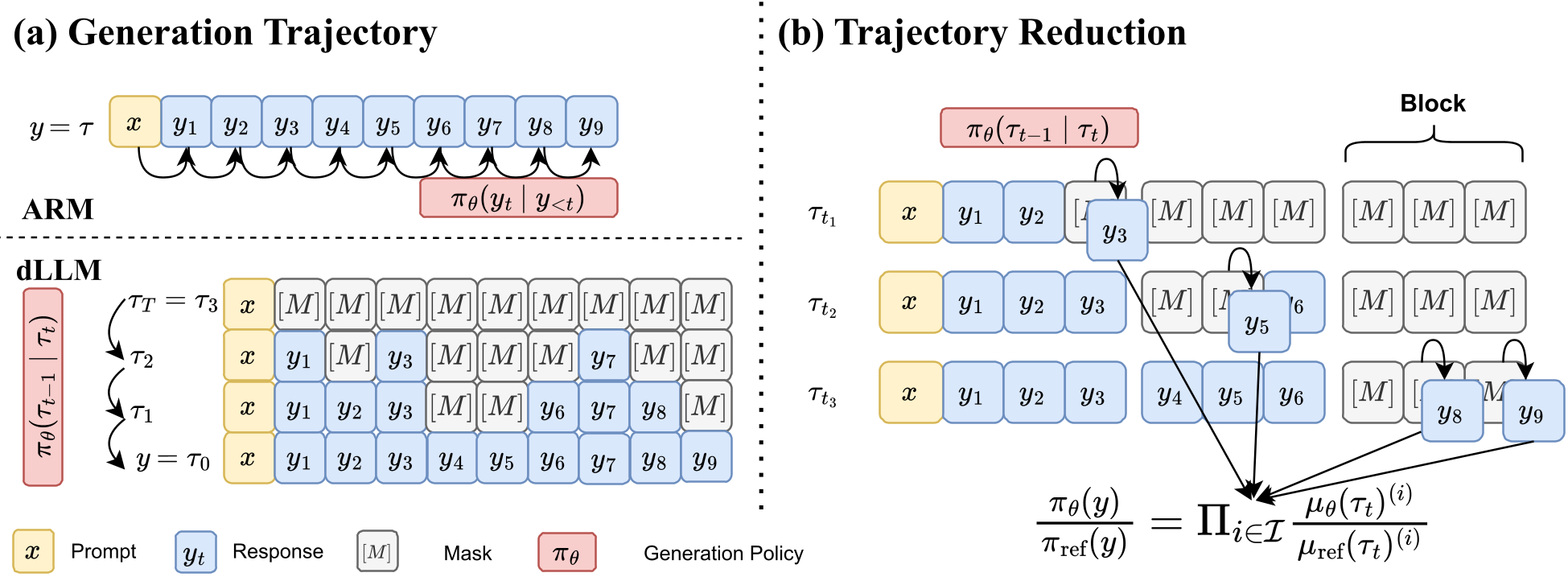 图注:(a) 展示了 ARM 和 dLLM 生成逻辑的区别;(b) 揭示了 dTRPO 如何采样掩码 Token 并进行比例缩减。
图注:(a) 展示了 ARM 和 dLLM 生成逻辑的区别;(b) 揭示了 dTRPO 如何采样掩码 Token 并进行比例缩减。
3. 方法论:Block Attention 助力单次前向训练
为了进一步压榨效率,作者引入了 Block Attention。在训练时,通过巧妙设计 Attention Mask,让同一个 Batch 里的不同位置能够观测到不同的上下文中掩码状态。
- 状态缩减 (State Reduction):原本需要遍历 T 个时间步,现在每块 (Block) 只采样一个时间步进行估算。
- 等效性:这种方法在数学上被证明是全局无偏的,大大降低了显存占用和计算时间。
4. 实验战绩:全线飘红
在 7B 参数规模的实验中,dTRPO 展现了极强的统治力:
- 数学推理 (MATH):相比原始 Fast-dLLM-v2 提升了 4.04%。
- 科学常识 (GPQA):提升幅度高达 9.59%。
- 指令遵循 (IFEval):提升 2.95%,极大缩小了与顶尖自回归模型(如 Qwen2.5-7B-Instruct)的差距。
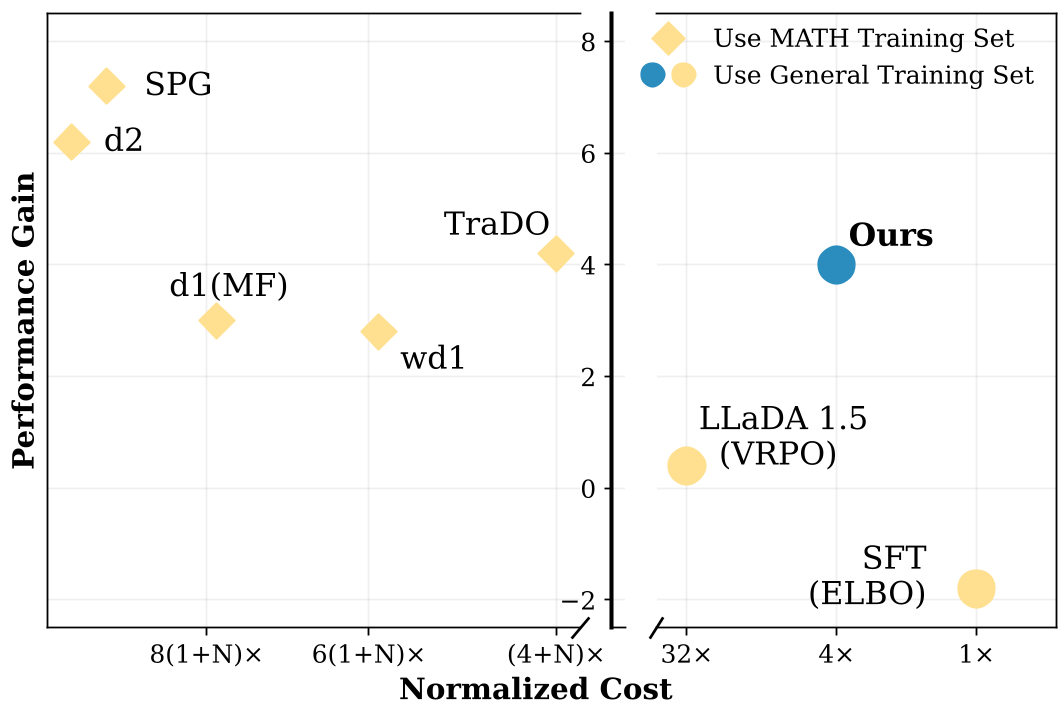 图注:性能提升与训练成本对比。dTRPO 以极低的离线成本实现了与复杂在线方法相当甚至更好的性能。
图注:性能提升与训练成本对比。dTRPO 以极低的离线成本实现了与复杂在线方法相当甚至更好的性能。
此外,dTRPO 在推理速度上的优势依然明显。如表3所示,在 Arena-Hard 测试中,dTRPO 的吞吐量 (TPS) 达到了 29.87,远高于 Qwen2.5 基线的 16.20,实现了近 1.9 倍的推理加速。
5. 深度洞察与总结
dTRPO 的意义不仅在于刷新了几个 Benchmark,而在于它为 dLLM 设计了一套标准的后训练 pipeline。
价值总结 (Takeaways)
- 数学重构的力量:通过 Ratio Reduction,将复杂的扩散路径优化简化为简单的 Token 级别概率比对,这种降维打击是效率提升的关键。
- 训练推理一体化:通过引入推断时一致的调度策略(Confidence-based scheduling),训练过程能更好地模拟真实推理分布。
局限性与展望
尽管 dTRPO 极大缩小了与 ARMs 的差距,但在极高难度的推理任务上(如复杂的 Coding),dLLMs 仍有微小落后。未来的研究方向可能在于如何在大规模在线强化学习(如类似 DeepSeek-R1 的思路)中进一步应用这种轨迹缩减技术。
主编点评:扩散模型正在告别“训练贵、对齐难”的历史。dTRPO 证明了只要数学功底够深,看似复杂的非自回归生成同样可以像 GPT 一样优雅地进行偏好对齐。