本文提出了 VAG,这是一个基于 Flow-Matching 的统一双流生成框架,旨在同步生成具身智能所需的视频及其对应的动作序列。VAG 通过在 denoising 过程中利用自适应 3D 池化(3D Pooling)机制,实现了视频与动作之间的高强度对齐,在多个机器人操作基准上达到了 SOTA 水平。
TL;DR
在机器人学中,高质量的遥操作(Teleoperation)数据既贵又难得。物理智能公司(Physical Intelligence)等领头羊都在探索如何通过“合成数据”来喂饱大模型。今天介绍的 VAG (Video-Action Generation) 框架,通过一个基于 Flow-Matching 的双流架构,实现了视频画面与物理动作的“帧级对齐”,直接生成长达 10 秒的机器人操作序列,成功率提升 20%。
背景定位
目前机器人的世界模型(World Models)正处于从“单纯看视频”向“边看边动”转化的关键期。VAG 不仅仅是一个视频生成器,它是一个数据引擎。它在学术坐标系中处于 World-Action (WA) Model 的前沿,解决了视频生成与策略学习(Policy Learning)之间的脱节问题。
核心痛点:为什么两阶段模型会失败?
传统的方案(如 DreamGen)通常先生成一段视频,再用一个逆动力学模型(IDM)去“猜”刚才那段视频里机器人做了什么动作。
- 逻辑割裂:视频和动作是异步的,往往画面的手抬起来了,生成的动作指令还是静止的。
- 误差爆炸:视频生成的微小伪影会误导动作回归模型,导致轨迹漂移。
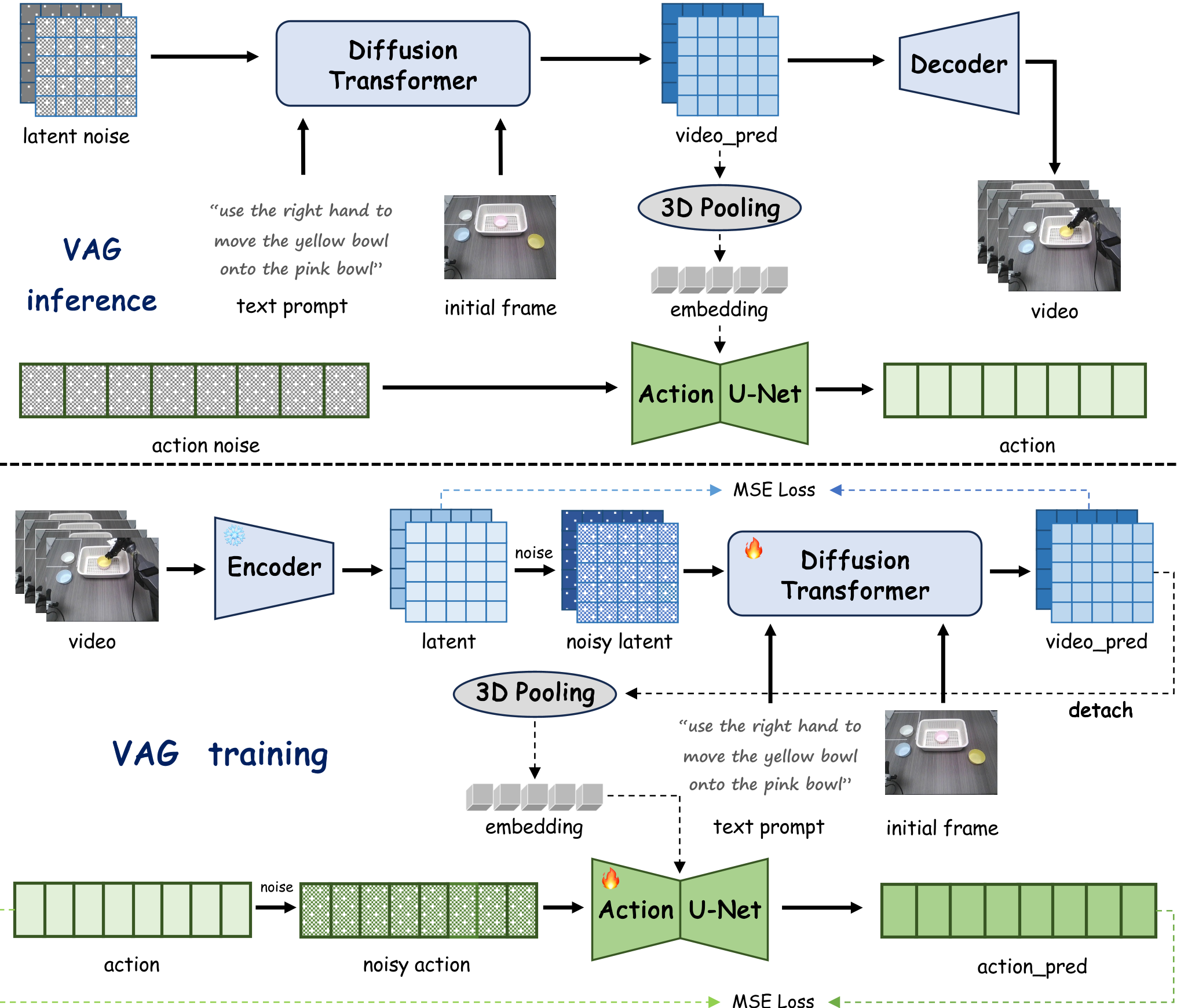
VAG 方法论:双流同步去噪
VAG 的直觉非常优雅:既然视频和动作是物理上耦合的,那就在去噪过程中让它们“对话”。
1. 架构解析
VAG 包含两个并行分支:
- 视频分支:基于 Cosmos-Predict2,负责从一张初始图和一段文字指令中扩散出未来的画面。
- 动作分支:修改自 Diffusion Policy 的 1D U-Net。
2. 桥梁:自适应 3D 池化 (Adaptive 3D Pooling)
为了让动作知道视频在画什么,作者在每一个去噪步(Denoising Step)中,提取视频分支的中间特征 z0,通过 3D Pooling 压缩时空通道,生成一个全局嵌入向量。这个向量充当了“视觉指挥官”,告诉动作分支:“当前画面正在抓取,请同步生成向下施压的力反馈”。
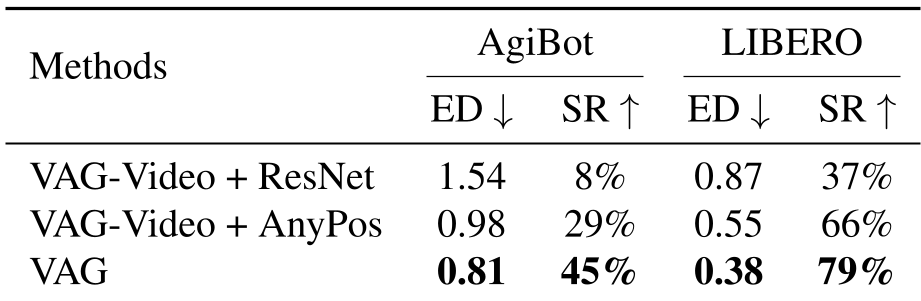
实验战绩
VAG 在真实世界数据集(AgiBot)和仿真环境(LIBERO)中展示了强大的对齐能力:
- 视频质量:在 FVD(Fréchet Video Distance)指标上表现优异,远超 Stable Video Diffusion (SVD)。
- 动作轨迹准确度:通过 Euclidean Distance 测量,VAG 生成的动作比“视频+AnyPos回归”方案更接近真实 Ground-Truth。
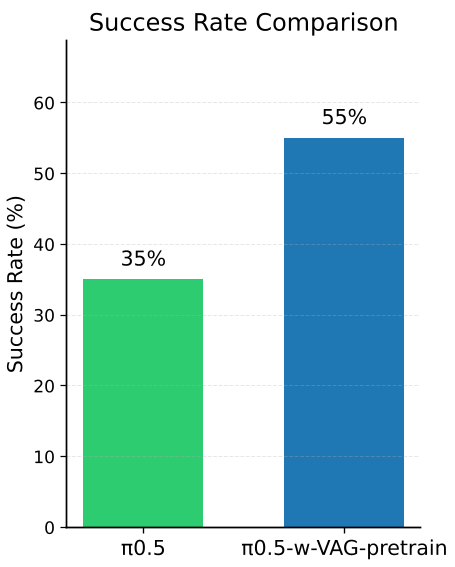
解锁跨域泛化
最令人振奋的是第 4.4 节的实验。作者在只有 131 条真实数据的基础上,用 VAG 合成了大量数据来预训练 π0.5 模型。在面对从未见过的物体颜色和位置改动时,预训练后的模型表现出了极强的鲁棒性,成功率从 35% 跃升至 55%。
深度洞察与总结
VAG 的成功标志着具身智能训练正在从“数据采集”转向“数据蒸馏与合成”。
- 优势:消除了多阶段模型的延迟与对齐不准。
- 局限性:目前视频分支还没有接收来自动作分支的反向反馈(即“动作引导视频”),这在处理极为精细的力控任务时可能存在瓶颈。
- 未来展望:随着 DiT (Diffusion Transformer) 在动作分支的引入,VAG 有望支持更长时程、更高维度的全身协调控制合成。
Takeaway:如果你在做具身智能,不要再苦恼于数据不够,学会用 VAG 这样的双流模型去“造”数据,才是 Scaling Law 在机器人领域的真实解法。