The paper introduces Dual-Teacher Distillation with Subnetwork Rectification (DDSR), a framework for Black-Box Domain Adaptation (BBDA) that utilizes both a black-box source model and a Vision-Language Model (CLIP) as dual teachers. It achieves state-of-the-art results on benchmarks like Office-Home (83.2% avg accuracy) and Office-31 (93.1% avg accuracy) without accessing source data or model parameters.
TL;DR
Adapting a model to a new domain without seeing the original training data or even the model's internal weights is a "black-box" challenge. DDSR (Dual-Teacher Distillation with Subnetwork Rectification) solves this by using a smart fusion of the black-box's predictions and CLIP's semantic knowledge, paired with a unique "subnetwork" trick to stop the model from learning "noise" instead of "patterns."
Domain Positioning: This work sits at the cutting edge of Privacy-Preserving Machine Learning and Domain Adaptation, establishing a new SOTA for scenarios where source models are only available via APIs.
The Problem: Training in the Dark
In traditional Unsupervised Domain Adaptation (UDA), you have the source data. In Source-Free adaptation (SFDA), you at least have the model weights. In Black-Box Domain Adaptation (BBDA), you have neither. You can only "query" the source model with target images and look at the output probabilities.
The issues are twofold:
- Noise: The source model's predictions on target data are often wrong (domain shift).
- Heterogeneity: Vision-Language models like CLIP have great general knowledge but lack the "specialized" view of the source model.
Methodology: Dual Teachers & Subnetwork Rectification
The DDSR framework operates in a two-stage process designed to extract and then refine knowledge.
1. Adaptive Dual-Teacher Fusion
Instead of just trusting the source model, DDSR brings in CLIP as a second teacher. The "magic" lies in the Adaptive Prediction Fusion. The model calculates the entropy (uncertainty) of both teachers. If the target domain is large, it leans on CLIP; if the domain is small, it relies more on the source model's task-specific expertise.
2. Subnetwork Rectification
To prevent the student model from overfitting to the noisy pseudo-labels generated by the teachers, the authors use a structural trick. They define a subnetwork (sharing the first $\gamma$ percentage of weights). By enforcing a gradient discrepancy between the full network and the subnetwork, the model is forced to learn more robust, diverse features rather than just memorizing the noise.
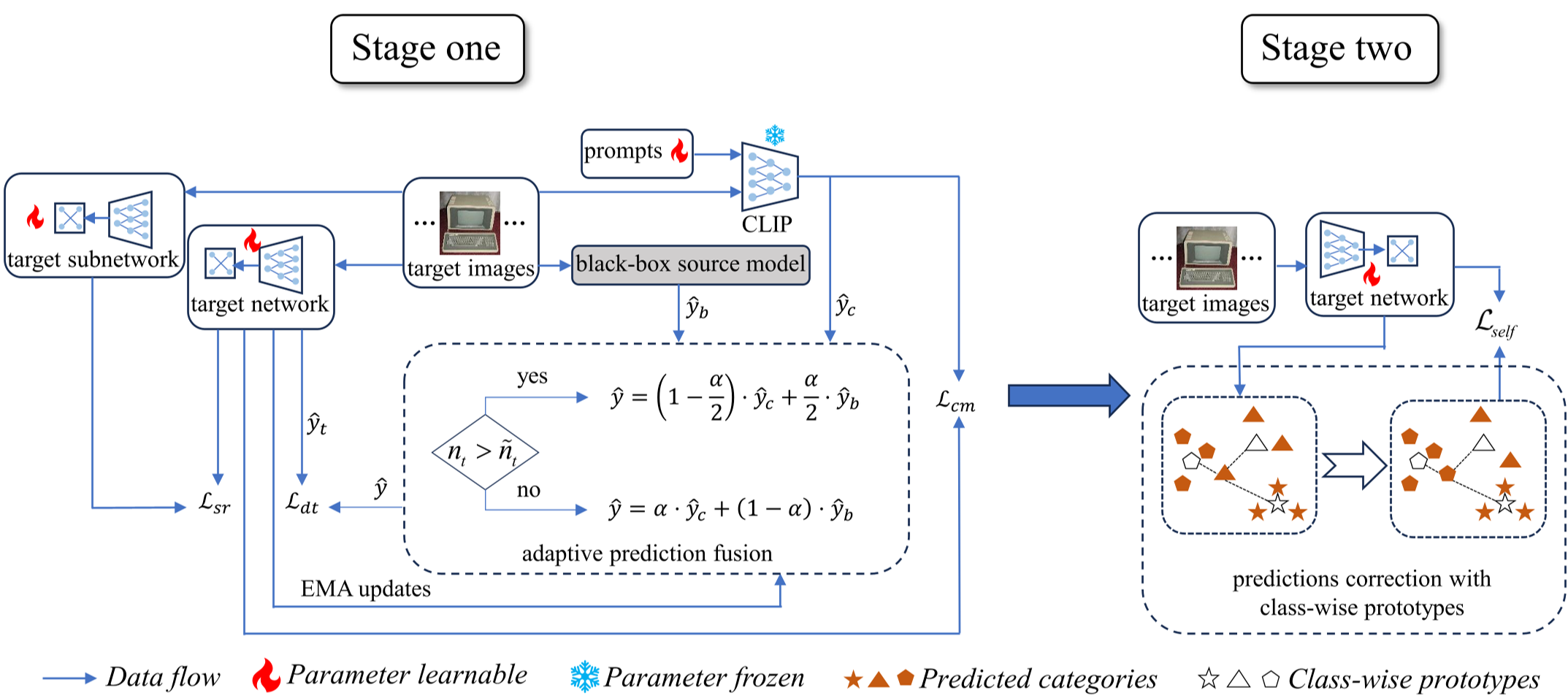 Figure 1: The DDSR framework utilizes a two-teacher setup (Black-box + CLIP) and a subnetwork to regularize the target model training.
Figure 1: The DDSR framework utilizes a two-teacher setup (Black-box + CLIP) and a subnetwork to regularize the target model training.
Experiments: Breaking the SOTA
The authors tested DDSR against three categories of methods across Office-31, Office-Home, and VisDA-17.
- Performance: On Office-Home, DDSR achieved 83.2%, beating the previous best BBDA method (AEM) by a significant margin.
- Visualization: t-SNE plots show that while the original source model sees a "mess" of overlapping clusters, DDSR-trained features are tightly grouped and well-separated.
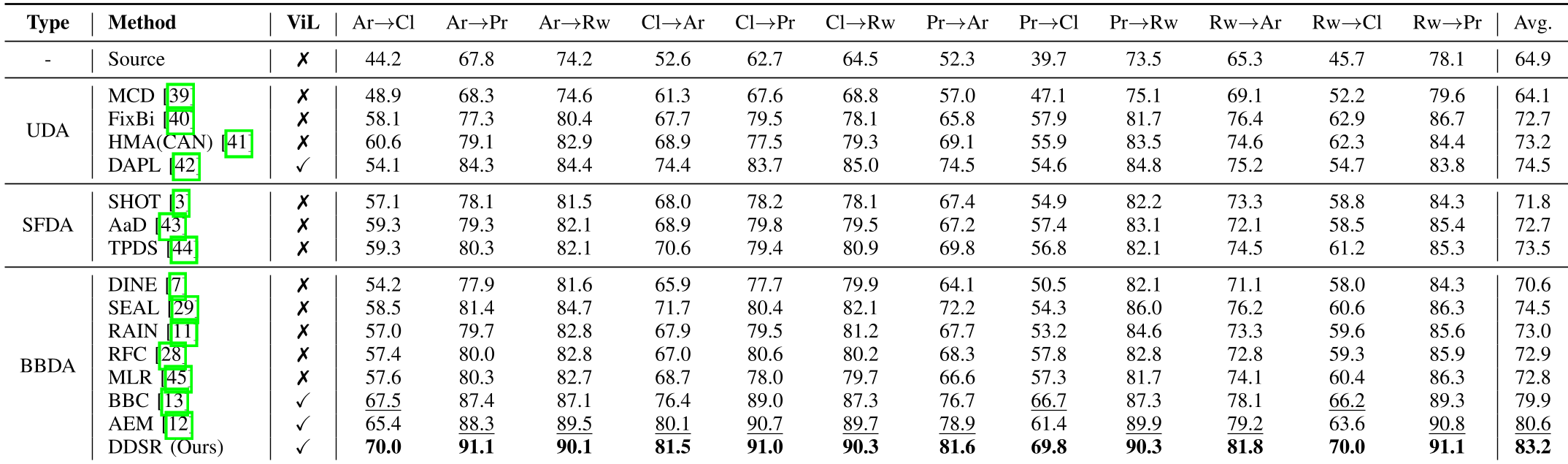 Table 1: Competitive results show DDSR outperforming even some methods that have access to source model parameters (SFDA).
Table 1: Competitive results show DDSR outperforming even some methods that have access to source model parameters (SFDA).
Why does it work? (Ablation Insights)
The ablation study revealed that Information Maximization ($L_{im}$) and Subnetwork Rectification ($L_{sr}$) are critical. Without the subnetwork rectification, the model's ability to handle domain shift drops, confirming that just "distilling" isn't enough—you need to supervise the way the network learns.
 Figure 2: Feature clusters before and after DDSR. Note the improved class separation in (b) and (d).
Figure 2: Feature clusters before and after DDSR. Note the improved class separation in (b) and (d).
Critical Analysis & Conclusion
Takeaway: BBDA is no longer a "second-class" adaptation setting. By intelligently fusing generic semantic models (CLIP) with specific black-box outputs, we can achieve performance that rivals "white-box" methods.
Limitations: The paper notes that it does not yet handle Category Shift (where source and target domains have different sets of classes). This remains the "final frontier" for black-box adaptation.
Future Outlook: As more AI is served via restricted APIs (like GPT-4-vision or specialized medical APIs), methods like DDSR will become the standard for local adaptation without compromising proprietary source intelligence.