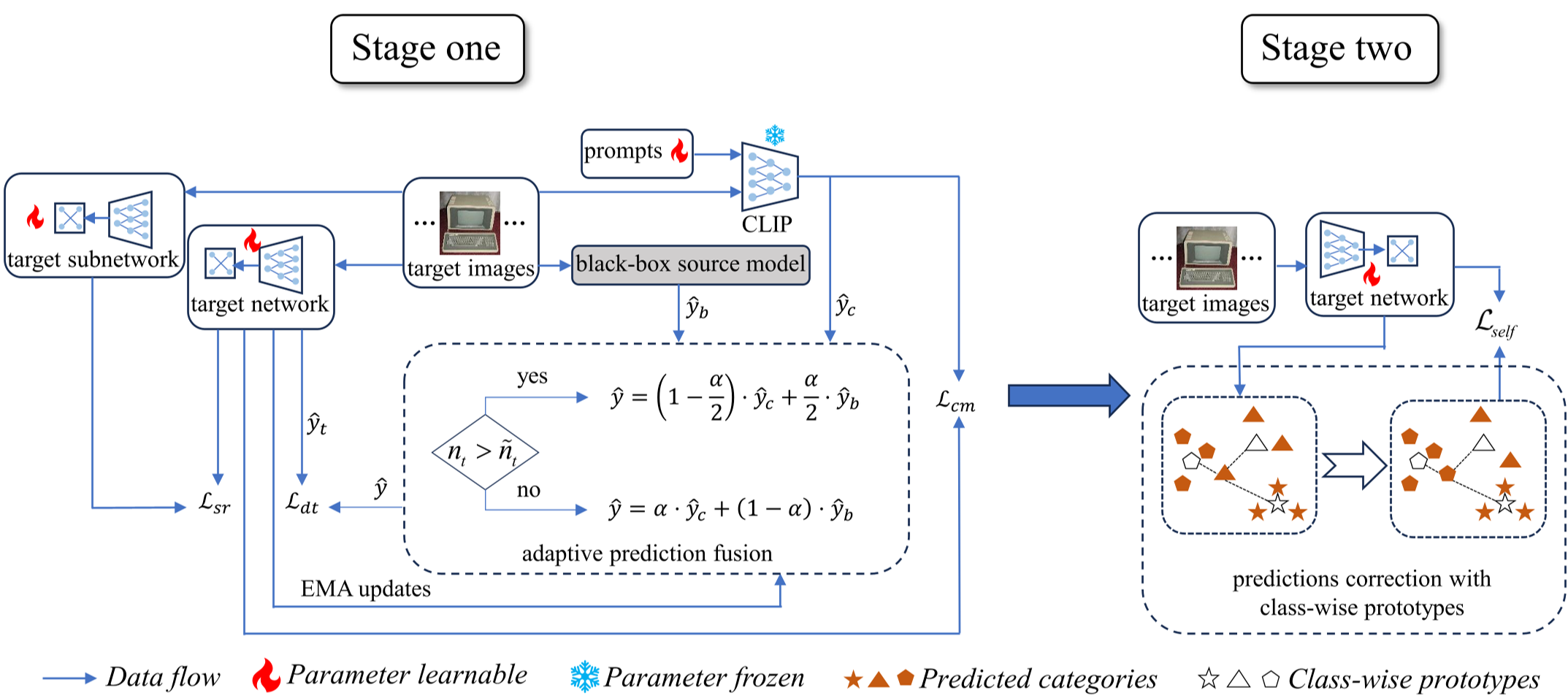
本文提出了 DDSR(Dual-teacher Distillation with Subnetwork Rectification),一种针对黑盒域自适应(Black-box Domain Adaptation, BBDA)的新型框架。该方法通过自适应融合黑盒源模型与视觉语言模型 CLIP 的预测生成伪标签,并利用子网络纠偏机制,在无法获取源数据和源模型参数的严苛条件下,实现了显著的 SOTA 性能提升。
TL;DR
在隐私保护和 API 服务日益普及的今天,黑盒域自适应 (Black-Box Domain Adaptation, BBDA) 成为研究热点。本文介绍的 DDSR 框架突破了“看不见模型、拿不到数据”的限制,通过引入 CLIP 作为第二老师,并配合精妙的“子网络纠偏”策略,在 Office-Home 等主流榜单上刷新了性能纪录。
1. 痛点:API 背后的“盲区”
在现实场景中,我们往往只能通过云端 API 调用预测模型,无法获取其权重(隐私保护)或训练数据。这种黑盒环境给领域迁移带来了三大挑战:
- 预测漂移:源模型在目标域上的输出充满了噪声。
- 信息匮乏:除了预测概率,没有梯度或中间特征可利用。
- 过拟合风险:由于伪标签质量不高,模型极易学到错误的分布。
2. 核心方案:双教师 + 子网络纠偏
DDSR 的核心逻辑在于“兼听则明”。它不仅听取黑盒源模型的建议,还引入了预训练的 CLIP (Vision-Language Model) 作为辅助。
2.1 熵权驱动的自适应融合
作者发现,简单平均两个模型的预测往往适得其反。DDSR 提出了自适应预测融合:
- 小样本域:侧重源模型的特定领域知识。
- 大样本域:通过比较熵(Entropy)来判断谁更自信,动态分配权重。 公式直觉:,通过不确定性比例来实现知识互补。
2.2 子网络纠偏 (Subnetwork Rectification)
这是本文最具学术美感的设计。作者在目标模型中“抠出”一个子网络(Subnetwork),通过两个损失函数进行反向约束:
- 输出对齐 (Output Divergence):利用 JS 散度让全网络与子网络在输出空间保持一致,增强稳定性。
- 梯度差异化 (Gradient Discrepancy):强制两者的梯度方向产生分歧,防止共同陷入噪声数据的陷阱,就像是让两个学生从不同角度预习功课,从而提高容错性。
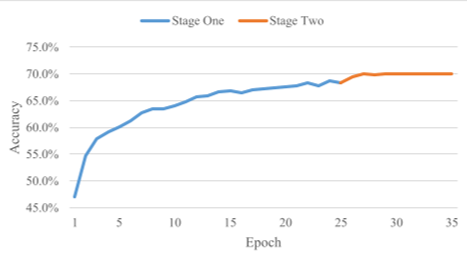
3. 实验战绩:不只是 BBDA 的胜利
在实验中,DDSR 展示了极强的竞争力,甚至在某些指标上反超了能够看到模型参数的 SFDA (Source-Free Domain Adaptation) 方法。
核心结果分析:
- Office-31: 达到了 93.1% 的平均准确率,显著高于 DINE 等早期黑盒工作。
- Office-Home: 在最具挑战性的任务(如 Rw→Cl)中,比 SOTA 提升了近 4 个百分点。
- 可视化分析: 通过 t-SNE 观察可以清楚看到,DDSR 处理后的目标域特征簇更加紧凑且边界清晰(如下图 b/d 所示)。
4. 深度洞察
DDSR 的成功证明了一个趋势:黑盒迁移不再是一个封闭的信息孤岛。
- 基础模型的降维打击:CLIP 提供的 General Semantic 为特定领域的黑盒噪声提供了“语义锚点”。
- 自适应的必要性:实验中(图 6/8)证明,固定权重的模型融合在 BBDA 中极其危险,必须根据域规模动态调整。
- 鲁棒性设计:子网络正则化有效地平衡了“学习知识”与“过滤噪声”的矛盾。
总结与局限
DDSR 为黑盒下的知识迁移提供了一套标准化的范体。尽管其在对齐类别空间上表现卓越,但目前尚未探讨类别偏移(Category Shift)——即如果目标域出现了源域没见过的新类别该怎么办?这将是未来研究的重要方向。
致读者:如果你正在处理隐私敏感或基于 API 的模型部署任务,DDSR 的双教师蒸馏思路非常值得借鉴。