本文提出了 E-3DPSM,一种基于事件相机的第一视角 3D 人体姿态估计连续状态机。通过将人体运动建模为与事件流同步的连续状态演化,并在两个主流数据集上实现了 SOTA 性能,精度提升达 19% 且时间稳定性提升 2.7 倍。
TL;DR
在增强现实(AR/VR)领域,佩戴式设备的 3D 人体姿态估计一直是核心痛点。本文提出的 E-3DPSM 摒弃了传统逐帧处理的逻辑,首次引入连续状态机概念,利用事件相机(Event Camera)的高频特性,结合 State Space Model (SSM) 和可学习卡尔曼融合,实现了高达 80Hz 的超平滑、高精度 3D 姿态追踪。
痛点深挖:为什么第一视角 3D 姿态估计这么难?
第一视角(Egocentric)姿态估计面临三大挑战:
- 极度自遮挡:摄像头位于头端,下肢经常被躯干遮挡。
- 剧烈运动模糊:快速转头或奔跑时,传统 RGB 相机产生的 Motion Blur 会让特征匹配失效。
- 计算冗余与延迟:为了平滑姿态,传统方法常需复杂的后处理(如离线 Kalman),难以满足 VR 交互实时性。
此前最强的 EventEgo3D 虽然引入了事件相机,但其本质上仍是将事件堆叠成“伪图像”,用传统的 CNN/Transformer 搬砖公式去解,忽略了事件流本质上的连续变化特性。
核心直觉:从“看图像”到“演化状态”
作者认为,既然事件相机捕捉的是“变化(Changes)”,那么模型也应该进化为状态机。
1. 时空姿态编码器 (SPEM)
SPEM 不仅仅提取空间特征,它通过 S5 状态空间层 (SSM) 维护了一个内部潜状态 (Latent State)。即便在某些时刻事件稀疏(如肢体静止),SSM 也能通过历史累积的运动信息实现“逻辑补全”。
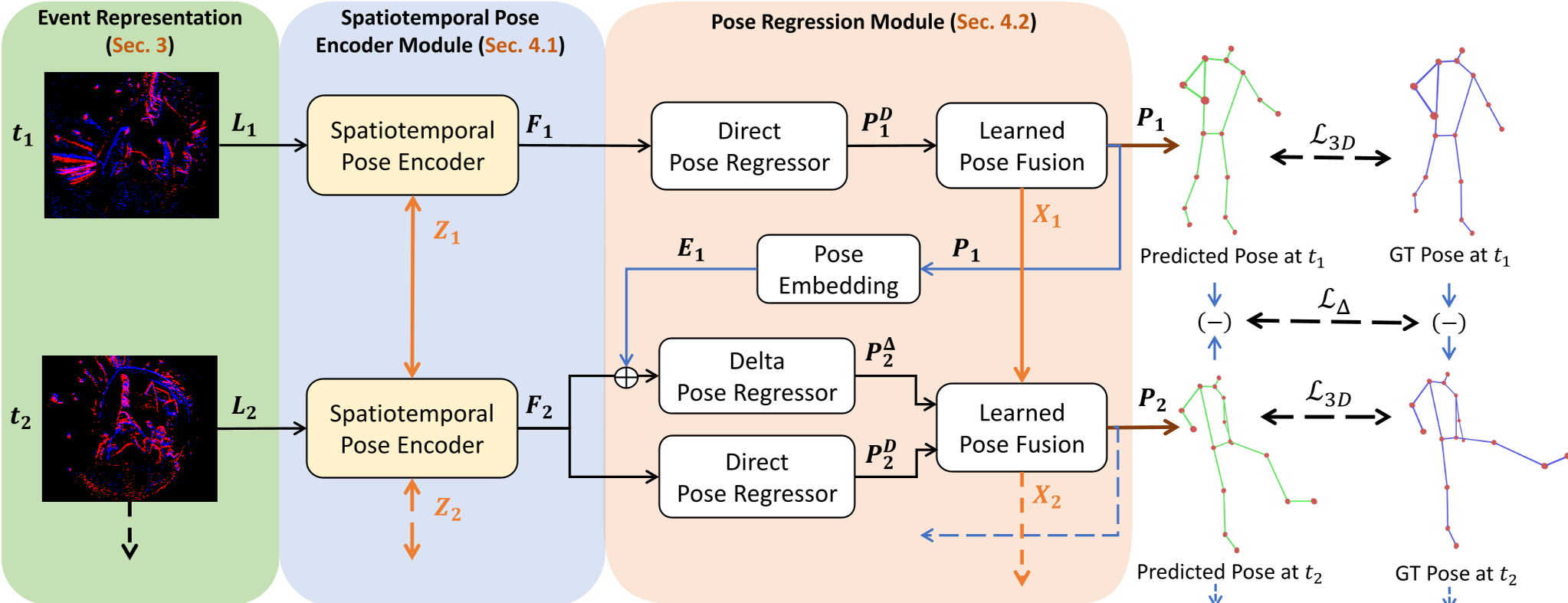
2. 增量回归与可学习融合 (PRM)
这是本文最惊艳的设计:
- Direct Pose (锚点):预测绝对坐标,防止整体跑偏。
- Delta Pose (细节):预测帧间微小的位移量。事件相机对这种位移极其敏感,这正是其强项。
- Neural Kalman Filter:不再使用人为设定的噪声参数,而是通过网络自动学习:什么时候该听 Direct Pose 的,什么时候该信任 Delta Pose。
实验结果:全方位的霸榜
在 EE3D-R 和 EE3D-W 两个高难度数据集上,E-3DPSM 展现了压倒性的优势。特别是在遮挡严重的关节(如踝关节、手腕),精度提升尤为明显。

关键战绩:
- 稳定性:时间平滑度(eSmooth)提升了 2.7 倍。
- 抗遮挡:在仅针对遮挡关节的测试中,MPJPE 误差大幅下降。
- 实时性:即便在移动端 NVIDIA 3050Ti 上也能跑到 52Hz。
结论与展望:走向全天候沉浸式交互
E-3DPSM 成功证明了:事件相机 + 状态空间模型 才是动态视觉任务的“天作之合”。它不仅解决了传统方法在暗光、高速运动下的无力感,更通过端到端的卡尔曼融合,消除了暴力堆叠帧带来的漂移顽疾。
尽管目前对于极其极端的自遮挡(如完全趴在地上的动作)仍有改进空间,但其展示的底层架构逻辑——将视觉看作连续流而非切片集合——无疑将启发未来更多的感知任务。
注:本文为学术前沿解读,源代码与预训练模型已由原作者公开于项目主页。