本文提出了 EffectErase,一种针对视频对象移除与插入任务的联合学习框架,旨在解决现有方法难以彻底消除物体关联效应(如阴影、反射、变形)的痛点。此外,作者还发布了目前规模最大的视频对象移除数据集 VOR,包含 60K 对高质量视频,显著提升了该领域的 SOTA 性能。
TL;DR
在视频后期处理中,移除一个物体并不难,难的是如何把它留下的阴影、镜面反射甚至是压弯的草坪效应一并“抹除”。来自复旦大学的研究团队通过 EffectErase 框架,首次利用“移除-插入”对偶学习机制,配合同步发布的超大规模 VOR 数据集,实现了对视频物体及其关联效应的高保真擦除。
痛点深挖:消失的物体,留下的“灵魂”
传统的 Video Inpainting 或 Object Removal 方法(如 ProPainter, DiffuEraser)大多遵循“Mask 指哪打哪”的逻辑。然而,物理世界是连锁反应的:一个动态物体在视频中往往伴随着复杂的环境交互:
- 光影伴生:物体虽然没了,但地面上残留的阴影和墙上的反射光仍在。
- 物理形变:比如一个人坐在沙发上,移除人后,沙发垫的凹陷处依然存在。
- 时空漂移:现有模型缺乏对物体与效应之间时空关联的显式建模。
究其原因,一是缺乏高质量的“有物体 vs 无物体”配对视频数据进行监督,二是模型缺乏对环境效应的感知能力。
核心方法论:以“插入”辅助“移除”
EffectErase 的直觉非常高级:既然移除物体很难定位其效应区域,那么通过学习如何“插入”一个物体并生成自然效应,反过来就能更精准地定位“移除”时该抹掉哪里。
1. 架构解析
EffectErase 基于 Wan 2.1 视频生成模型构建,采用 DiT (Diffusion Transformer) 作为骨干网络。
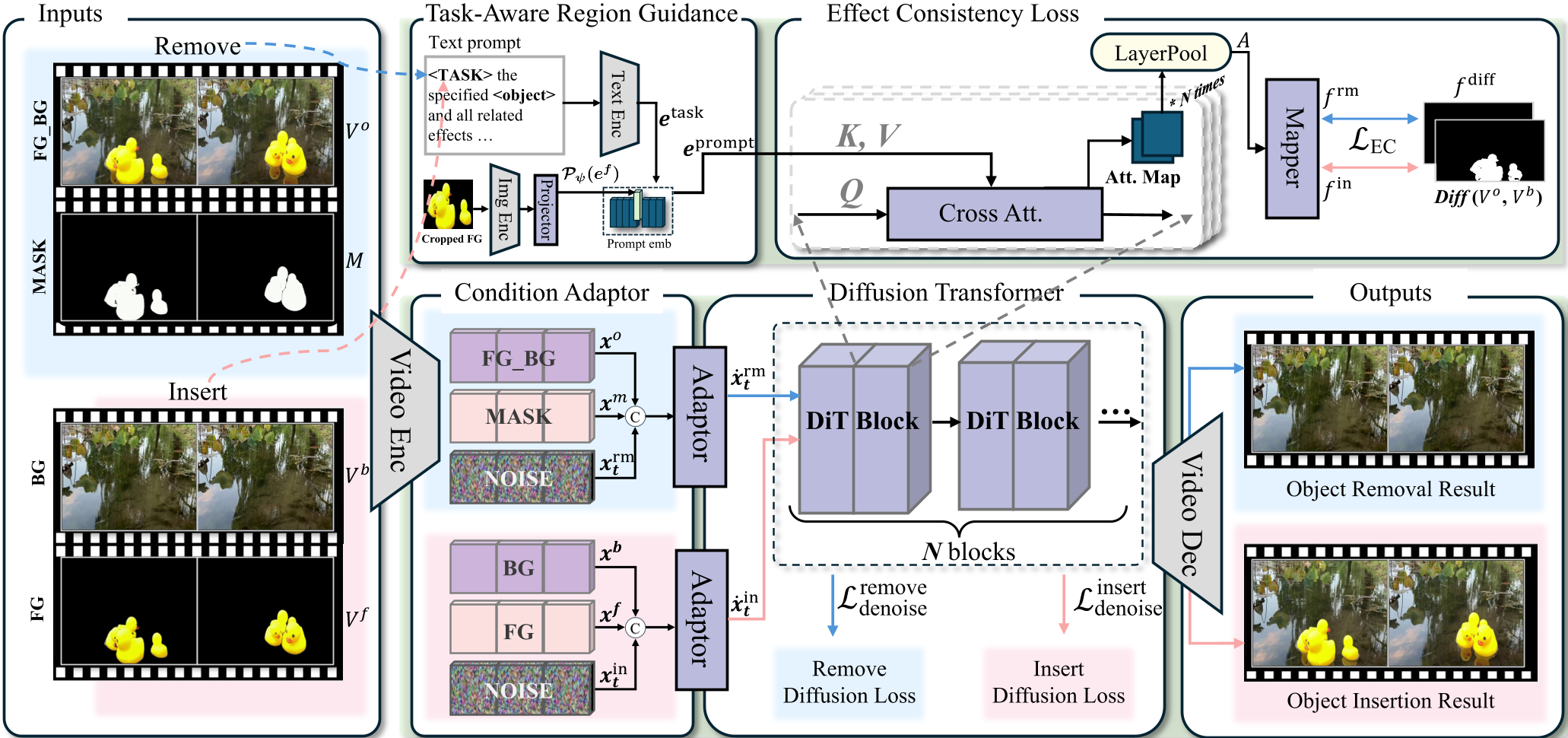 图 1:EffectErase 框架图。模型通过 Adaptor 融合条件输入,利用任务感知引导模块定位效应区域。
图 1:EffectErase 框架图。模型通过 Adaptor 融合条件输入,利用任务感知引导模块定位效应区域。
2. 关键模块
- Task-Aware Region Guidance (TARG):模型不只是接收 Mask,还通过 CLIP 提取物体特征并结合任务 Token。通过 Cross-attention,模型会自动在邻域内搜寻与该物体相关的“效应指纹”。
- Effect Consistency Loss (EC Loss):这是本文的神来之笔。作者利用 KL 散度约束,强制要求“把物体放进去产生的阴影区域”必须与“把物体拿走需要修补的区域”在特征空间上完成重合。
VOR 数据集:填补行业空白
为了训练这一复杂的效应感知能力,作者构建了 VOR (Video Object Removal) 数据集。这是目前已知最全面的基准:
- 规模:60K 对视频,总时长 145 小时。
- 多样性:涵盖 366 个物体类别,细分为遮挡、阴影、照明、反射、变形五大效应类型。
- 真实与合成的平衡:结合了固定相机拍摄的真实视频(利用 Ken Burns 效应增强运动)与高精细 3D 引擎渲染的合成视频。
 表 1:在多个基准测试中,EffectErase 在 PSNR 和 FVD(衡量时空连贯性的核心指标)上均刷新了纪录。
表 1:在多个基准测试中,EffectErase 在 PSNR 和 FVD(衡量时空连贯性的核心指标)上均刷新了纪录。
实验与结果:不仅擦得干净,还能插得自然
在与 SOTA 方法 ROSE 和 MinMax-Remover 的对比中,EffectErase 展现出了统治级的视觉表现。
 图 2:在处理镜面反射和复杂光影时,其他方法往往会留下模糊的伪影,而 EffectErase 能够还原纯净的底色。
图 2:在处理镜面反射和复杂光影时,其他方法往往会留下模糊的伪影,而 EffectErase 能够还原纯净的底色。
更有趣的是,由于模型学习了“移除-插入”的对偶特性,EffectErase 展现出了极其强大的 Zero-shot 物体插入 能力。当你尝试在视频中插入一个球体时,模型会自动根据当前背景光效生成匹配的接触阴影,这种一致性是传统编辑软件难以比拟的。
深度洞察与总结
EffectErase 的成功证明了:生成式任务不应是孤立的。 通过建模任务之间的逆向关系,模型能够获得跨维度的语义理解。
局限性:目前该方法仍强依赖于输入 Mask 的准确性。未来的进化方向可能是通过自然语言指令(如“移除那个正在跑的人及其阴影”)直接完成端到端的特效处理。
对于影视后期和短视频创作者而言,这绝对是改变工作流的“核弹级”进步。