本文提出了一个针对边缘设备优化的全栈推理框架,通过 Qwen2.5 (3B/7B) 模型实现了高效的 Chain-of-Thought (CoT) 推理。核心贡献包括模块化 LoRA 适配器、动态路由 Switcher、预算强制 RL 训练以及并行测试时缩放技术。
TL;DR
大语言模型(LLM)的推理能力虽然强大,但其动辄数千 Token 的推理轨迹(CoT)在内存受限的手机端简直是场灾难。高通(Qualcomm)AI 研究团队最近发布了一项工作,通过 LoRA 模块化、动态路由、预算强制 RL(Budget Forcing)以及并行验证,成功将 Qwen2.5 转化为高效的端侧推理机,在推理 Token 节省 2.4 倍的同时,准确率提升了 10%。
背景:端侧推理的三座大山
要在手机上运行像 DeepSeek-R1 这种级别的推理模型,面临三个硬伤:
- 内存占用:冗长的推理过程会让 KV-cache 迅速挤爆手机 DRAM。
- 推理延迟:逐个 Token 生成非常耗电,且等待时间过长。
- 通用性退化:专门微调推理能力往往会让模型变“傻”,在普通对话中也开始废话连篇。
核心方法论:软硬兼施的“瘦身”计划
1. 动态自适应:按需推理 (Switcher Module)
并不是所有问题都需要思考。当你问“1+1等于几”时,模型不需要 <think> ... </think>。
作者设计了一个极轻量的 Switcher 模块(仅 8 个隐含节点的 MLP),它在 Prefill 阶段分析输入特征,判断是否需要挂载“推理适配器”(Reasoning LoRA)。
- 关键创新:为了避免切换时的延迟,团队采用了 Masked LoRA 预训练。这意味着无论是否激活推理模式,基座模型生成的 KV-cache 都是通用的,无需重新编码。
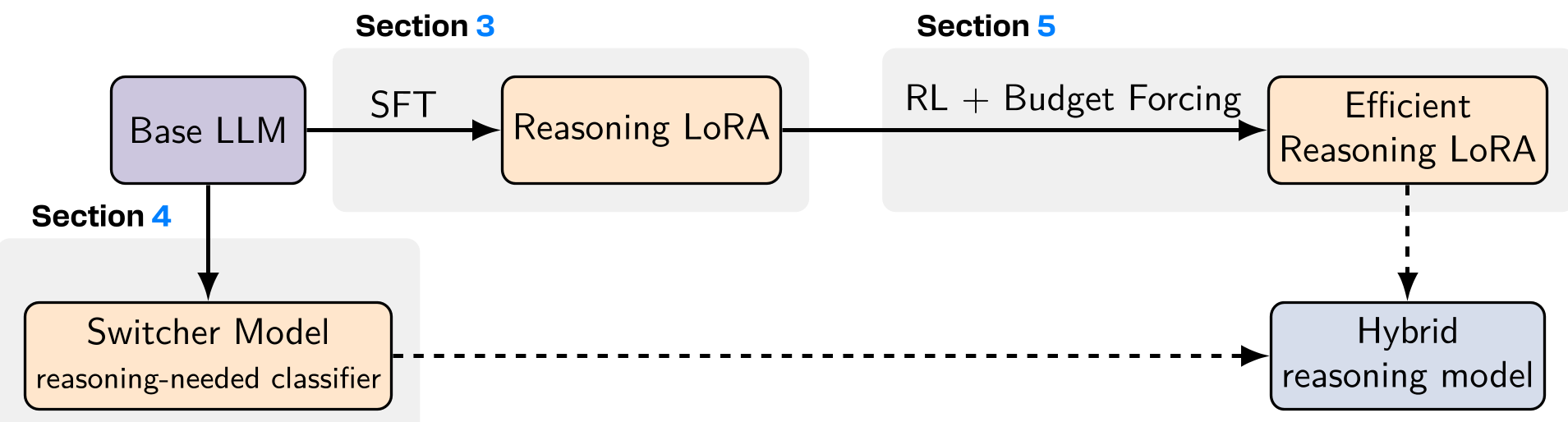
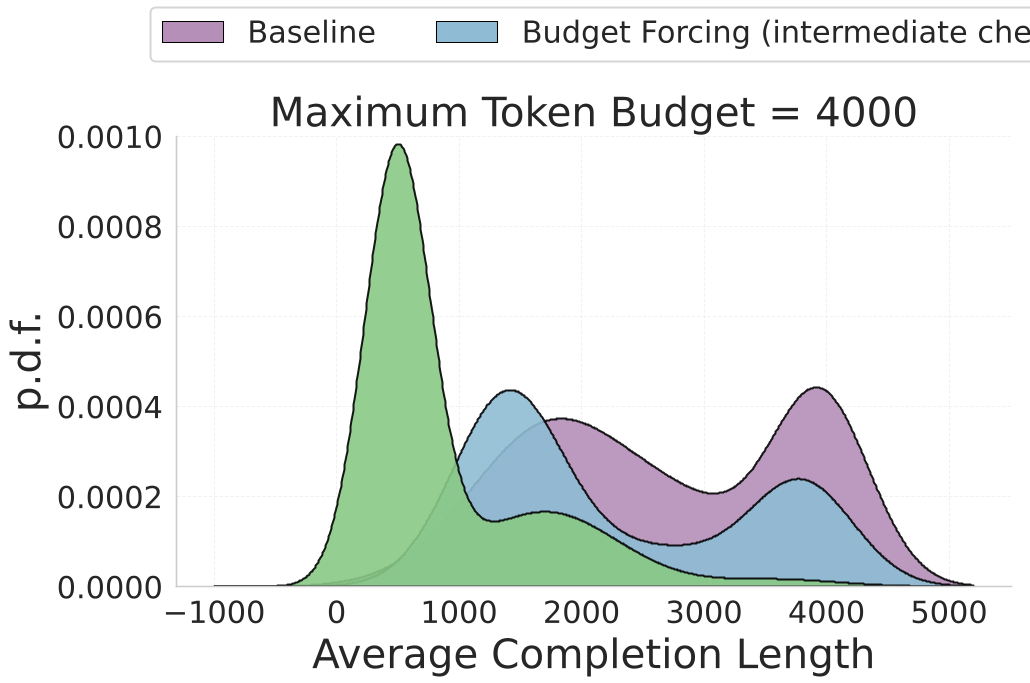
2. 预算强制 (Budget Forcing):告别“复读机”
作者观察到,很多模型虽然能做对题,但会陷入自我验证的死循环。 通过 GRPO 算法 和一种创新的 乘法软屏障(Soft-Barrier)奖励函数,模型被训练在保证正确的前提下,能量消耗最小化。
- 效果:推理长度从原来的几千 Token 压缩到了几百,平均压缩率 2.4x。模型学会了“自信下笔”,剔除了冗余的垃圾话。
3. 并行测试时缩放 (Parallel TTS):压榨硬件余力
端侧解码通常是内存带宽受限(Memory-bound)而非计算受限。利用这一点,模型同时生成多个候选答案,并通过一个**轻量级验证头(Verifier Head)**进行加权投票。这种方式几乎没有增加额外延迟,却带来了显著的精度跳升。
实验与战绩
在 Qwen2.5-7B 的实验中,经过 FPTQuant 4-bit 量化后的模型,在 MATH500 上的表现接近全精度水平。相比于未经优化的 SFT 基线,带有预算控制的 RL 模型在短字数限制下的准确率从 34% 暴涨至 62% 以上。
| 模型配置 | 1K 预算得分 | 6K 预算得分 | 平均准确率 | | :--- | :--- | :--- | :--- | | SFT 基线 (r=128) | 34% | 83% | 95% | | 预算强制 RL (本文) | 62% | 90% | 92% |
深度洞察:为什么这很重要?
这篇文章最深刻的 Insight 在于:推理密度(Reasoning Density) 远比长度更重要。 传统的蒸馏方法只是模仿 Teacher 模型的语气,而本文通过 RL 强制模型在有限的 Token 预算内寻找最优解路径。这不仅是算法的胜利,更是对端侧软硬一体化设计的最佳实践。
总结
该项研究为未来的 Agentic 工作流提供了一个蓝图:在手机端,我们不需要一个永远在思考的庞然大物,而需要一个能在毫秒间判断“是否需要思考”、并在眨眼间给出“精炼推导”的灵巧大脑。
注:本文使用的所有技术均已通过高通 FastForward 和 GENIE SDK 实现在移动设备上的导出与运行。