The paper introduces Efficient Universal Perception Encoder (EUPE), a foundation vision encoder designed for resource-constrained edge devices. It achieves SOTA-level universal representations across image understanding, dense prediction, and vision-language modeling (VLM) by distilling knowledge from multiple domain-expert teachers into a single compact backbone.
TL;DR
Meta researchers have unveiled EUPE (Efficient Universal Perception Encoder), a framework that produces tiny yet "all-knowing" vision encoders. By introducing a massive 1.9B-parameter Proxy Teacher as a bridge, EUPE successfully compresses the specialized knowledge of multiple domain experts (like DINOv3 for geometry and SigLIP for semantics) into efficient backbones (ViT-T to ViT-B). The result is a single model that powers VLM, segmentation, and classification on edge devices without the usual performance trade-offs.
The "Capacity Bottleneck" in Multi-Task Learning
In the current AI landscape, we have a "fragmented excellence" problem. If you want a model that understands depth, you use DINOv2/v3. If you want Zero-shot classification, you use CLIP/SigLIP. If you want a VLM that can read text, you use PElang.
For edge devices (smart glasses, phones), we cannot afford to run three different encoders. However, simply "cramming" all these experts' knowledge into a small ViT-Tiny model leads to a "jack of all trades, master of none" scenario. The authors identify the core issue: Efficient encoders lack the "Inductive Bias" or capacity to resolve the representational conflicts between multiple teachers simultaneously.
Methodology: The "Scaling Up, then Scaling Down" Recipe
EUPE discards the traditional approach of direct multi-teacher-to-student distillation. Instead, it follows a three-stage pipeline:
- Stage 1: The Unified Proxy (Scaling Up) The authors distill multiple experts (PEcore, PElang, and DINOv3) into a heavy 1.9B Proxy Teacher. This high-capacity model acts as a "knowledge aggregator," finding a latent space where semantic and geometric features coexist.
- Stage 2: Fixed-Resolution Distillation (The Transfer) The target efficient student (e.g., ViT-S) learns only from the Proxy Teacher. Learning from one "universal" teacher is significantly easier for a small model than trying to satisfy three different masters.
- Stage 3: Multi-Resolution Finetuning To handle tasks like OCR (needs high res) and classification (needs standard res), the student undergoes a final stage of training with an image pyramid.
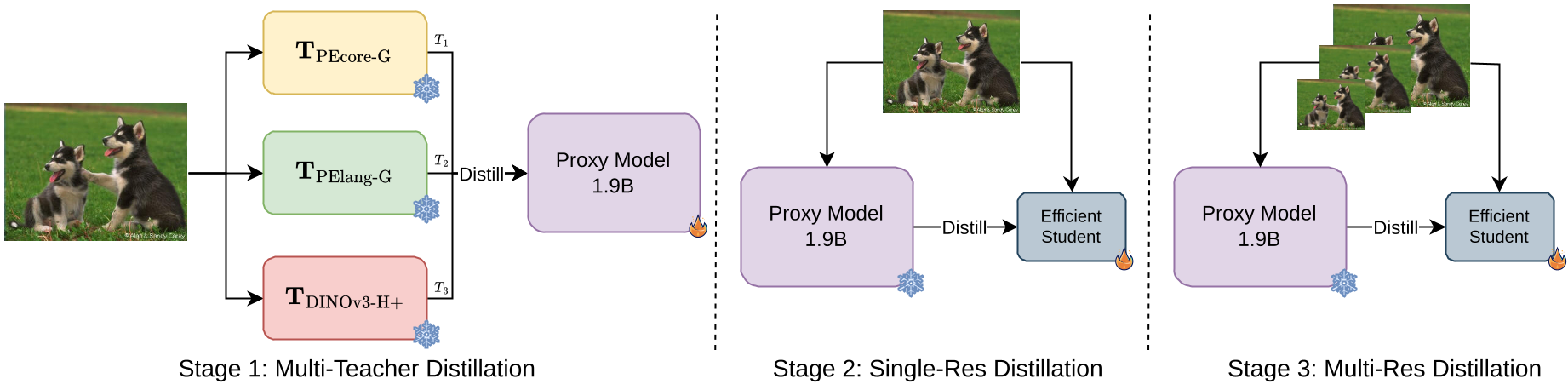 Figure 1: The three-stage pipeline: Scaling up to a Proxy, then distilling down to the edge student.
Figure 1: The three-stage pipeline: Scaling up to a Proxy, then distilling down to the edge student.
Visualizing the "Universal" Feature Space
The most striking evidence of EUPE's success is in its feature visualization via PCA. While models like CLIP produce "noisy" semantic maps and DINOv3 produces "clean" but texture-blind geometric maps, EUPE manages both.
 Figure 2: PCA projection of patch tokens. EUPE (left) maintains semantic coherence (shared colors for similar objects) while remaining sensitive to fine-grained details.
Figure 2: PCA projection of patch tokens. EUPE (left) maintains semantic coherence (shared colors for similar objects) while remaining sensitive to fine-grained details.
Performance: Beating the Specialists
The experimental results are a rare "win-win-win." EUPE-ViT-B matches the specialized DINOv3-ViT-B on ADE20k (segmentation) while simultaneously beating SigLIP2-B on vision-language benchmarks like RealworldQA and GQA.
| Task Domain | Benchmark | PEcore (Expert) | DINOv3 (Expert) | RADIOv2.5 (Agglo) | EUPE-ViT-B (Ours) | | :--- | :--- | :--- | :--- | :--- | :--- | | Image Under. | IN1k-ZS | 78.4 | N/A | 74.6 | 79.7 | | VLM General | GQA | 65.6 | 65.9 | 65.8 | 67.3 | | Dense Pred. | ADE20k (mIoU) | 37.4 | 51.8 | 49.0 | 52.4 |
Critical Insight: Why not just use a 7B Teacher?
An interesting finding in the ablation studies (Table 8) shows that scaling the Proxy Teacher to 7B parameters actually hurt the VLM performance of the ViT-B student. This suggests a "Goldilocks Zone" for teacher size: if the teacher is too large (7B vs 86M), the gap in representation becomes too wide for the student to bridge without more advanced techniques like Teacher Assistants.
Conclusion
EUPE demonstrates that for efficient AI, simplicity in the student's learning target is key. By unifying diverse knowledge into a proxy teacher first, Meta has provided a roadmap for creating versatile, high-performance encoders that can actually run on your wrist or in your glasses.
Future Outlook
The release of the EUPE model zoo (ViT and ConvNeXt variants) offers a new baseline for on-device perception. The next frontier will likely involve progressive distillation to unlock even larger teachers (7B+) for even smaller students (ViT-T).