This paper provides the first comprehensive survey of efficient video diffusion models (VDMs), categorizing advancements into step distillation, efficient attention, model compression, and cache/trajectory optimization. It highlights the transition from U-Net to DiT-based architectures and evaluates methods capable of achieving SOTA high-fidelity synthesis with significant inference speedups (up to one-step generation).
Executive Summary
TL;DR: Large-scale video generation is no longer just a "quality" problem—it is a massive "systems" problem. This survey provides a structured roadmap of how the industry is moving from slow, multi-step denoising to efficient, high-throughput pipelines. By categorizing methods into distillation, sparse attention, compression, and caching, the authors reveal how the next generation of video AI will achieve real-time latency without sacrificing cinematic quality.
Positioning: This is the first systematic survey focusing exclusively on the deployment-oriented efficiency of video diffusion models, moving beyond simple image-based transfers to address video-specific temporal constraints.
The "Joint Burden" of Video Synthesis
While image generation has matured, video synthesis faces a "multiplier effect" of costs. Every additional second of video expands the number of latent tokens, increases the duration for which temporal consistency must be maintained, and forces iterative denoising to repeat expensive calculations dozens of times.
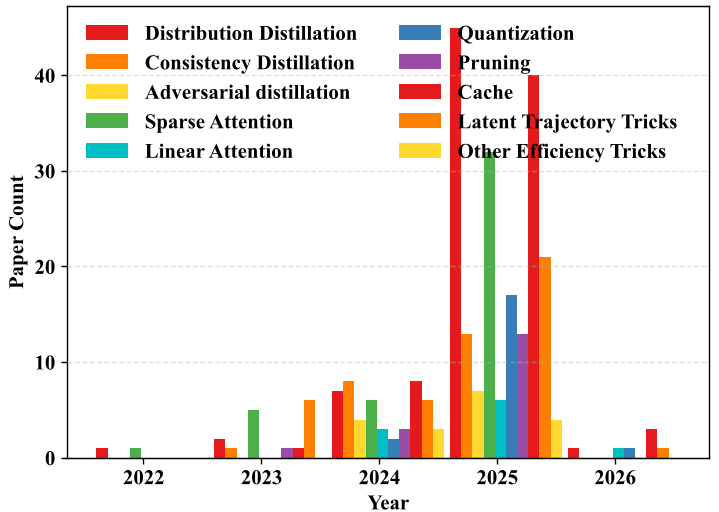
The authors highlight a critical gap: as of 2025, while image acceleration is heavily researched, video-native efficiency is only now consolidating, driven by the shift toward Diffusion Transformers (DiT) (e.g., Sora, HunyuanVideo, Wan2.1).
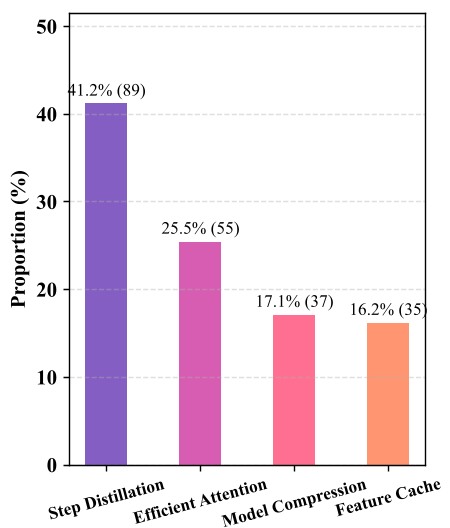
Methodology: The Four Pillars of Efficiency
1. Step Distillation (Reducing NFE)
The most aggressive lever is reducing the Number of Function Evaluations (NFE).
- Consistency Distillation (LCM): Teaches the model to map any point on a trajectory to the same origin, enabling 4-8 step sampling.
- Distribution Matching Distillation (DMD): Currently the "gold standard" for pushing models to 1-step generation by aligning the student model's distribution with a pre-trained teacher using GAN-like objectives.
2. Efficient Attention (Managing the Token Explosion)
As sequence lengths grow, the complexity of attention becomes the primary bottleneck.
- Sparse Attention: Methods like SpargeAttention or Radial Attention skip low-value interactions based on spatial or temporal locality.
- Linear/Hybrid Attention: Rewriting the attention formula to achieve scaling, though often requiring retraining or "attention surgery" to maintain motion fidelity.
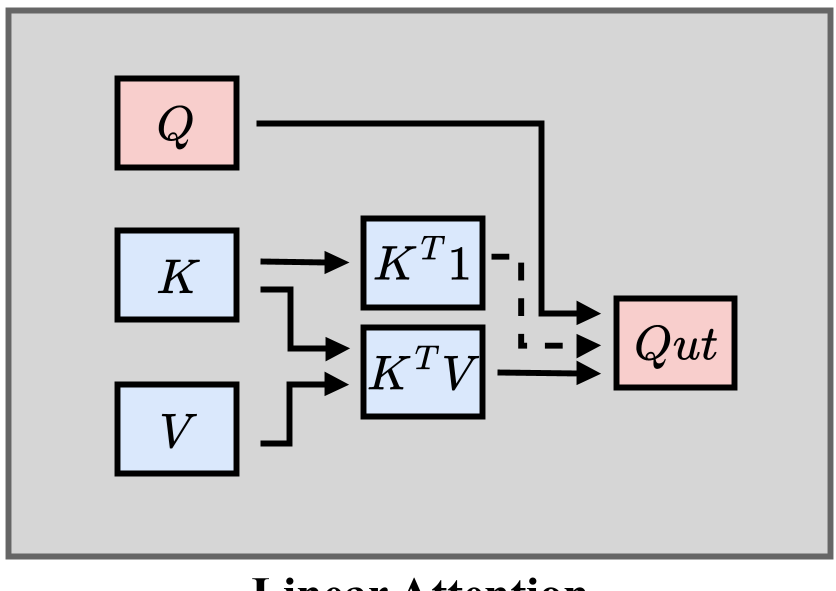
3. Model Compression (Hardware-Level Optimization)
- Quantization (PTQ/QAT): Moving tokens from FP32 to INT4/FP8. The challenge here is Timestep-Awareness—diffusion statistics change wildly as , requiring dynamic quantization scales to avoid flickering.
- VAE Compression: Reducing the "upstream" cost by making the latent space smaller so the diffusion model has fewer tokens to process from the start.
4. Cache & Trajectory Optimization
Instead of changing parameters, these methods change how we execute the model. Feature Caching (e.g., PAB, FasterCache) reuses intermediate states between similar denoising steps, drastically reducing redundant FLOPs.
SOTA Performance & Experimental Insights
The survey points to a fundamental trade-off: Composite Acceleration. When you stack 1-step distillation on top of 4-bit quantization and sparse attention, approximation errors compound.
- Key Findings: Streaming generation (chunk-by-chunk) is the fastest-growing sub-field, with methods like Self-Forcing solving the "exposure bias" where errors in one frame propagate into the next, eventually leading to "identity drift" or visual collapse.
- Infrastructure: The industry is pivoting toward Block-wide Causal Masking to allow for infinite-horizon generation within finite memory buffers.
Critical Analysis & The Road Ahead
Despite the progress, the authors identify several "Hard Problems":
- Hardware-Algorithm Mismatch: Irregular sparse masks look great on paper but run slowly on GPUs. We need "Kernel-friendly" sparsity.
- Dataset Scarcity: Most SOTA models are trained on proprietary data (Sora, Kling). Open-source research is bottlenecked by the lack of high-resolution, motion-rich datasets.
- Real-Time Interaction: The goal is 30+ FPS interactive video (e.g., world models for games), which requires a complete rethink of the bidirectional attention used in standard DiTs.
Final Takeaway
Efficient video diffusion is shifting from a post-training "trick" to a core architectural requirement. Researchers should focus on co-designing the distillation objective with the underlying sparse-attention kernels to ensure that the "Model of the Future" is not just powerful, but actually deployable.