视频扩散模型加速全景:从算法直觉到实时部署的跨越
Summary
Problem
Method
Results
Takeaways
Abstract
本文是学术界首篇系统性综述视频扩散模型(Video Diffusion Models, VDMs)加速技术的综述论文。文章全面涵盖了步骤蒸馏、高效注意力机制、模型压缩及缓存/轨迹优化四大核心范式,并探讨了在 Sora 等大模型时代下的实时视频生成挑战。
TL;DR
视频生成领域正经历从“能画”到“好用”的范式转移。这篇来自香港科技大学等机构的资深综述,首次拆解了视频扩散模型(VDM)加速的底层逻辑。它告诉我们:视频加速不是简单的“快”,而是在NFE(步数)、Per-step cost(单步开销)以及时序稳定性之间的系统博弈。
背景定位:为什么视频加速比图像难得多?
在图像领域,加速可能意味着从 20 步降到 1 步;但在视频领域,计算量随着帧数和分辨率呈爆炸式增长。一个 1 分钟的视频可能包含数万个 Token,在 DiT(Diffusion Transformer)架构下,Attention 操作的显存需求和延迟会瞬间击穿单张 H100 的上限。
作者指出,目前的加速研究正处于爆发期(见下图),其中“步骤蒸馏”和“稀疏注意力”是目前的两大主战场。
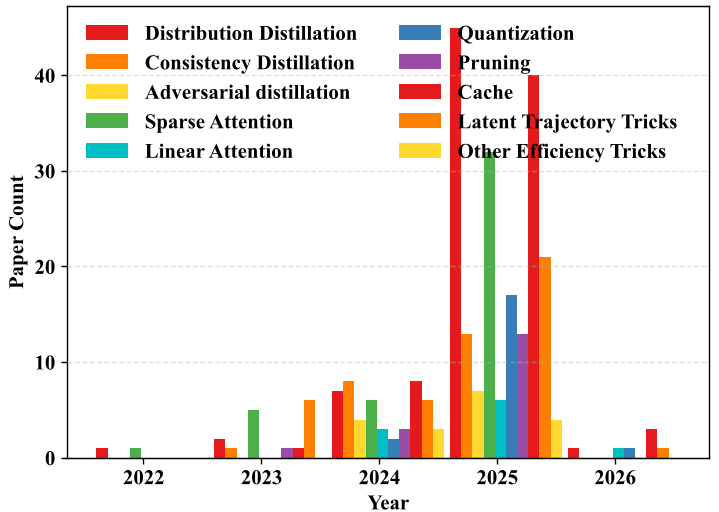
核心方法论:加速的四大支柱
1. 步骤蒸馏 (Step Distillation):消灭 NFE
这是最强力的杠杆。
- 一致性蒸馏 (Consistency Distillation):让模型学习“自洽性”,从任意噪点一步跳到轨迹原点。
- 分布匹配蒸馏 (DMD/DMD2):目前的一线技术,通过判别器和得分函数让低步数模型输出的分布向高步数模型对齐。
- 因果/实时蒸馏 (Streaming Distillation):针对实时交互场景,将传统的双向注意力模型转化为因果模型(Causal Model),解决“边收信息边生成”的暴露偏差(Exposure Bias)。
2. 高效注意力 (Efficient Attention):打破复杂度诅咒
注意力机制是视频 DiT 的头号功臣,也是显存杀手。
- 静态稀疏 (Static Sparse):固定采样模式(如 Diagonal 或 Window),对硬件友好但缺乏灵活性。
- 动态稀疏 (Dynamic Sparse):根据内容动态决定哪些 Token 重要。例如 SpargeAttention 能在推理时训练无关地跳过无关计算。
- 线性化与混合 (Linear-Hybrid):虽然理论复杂度是线性的,但在视频任务中往往会丢失细节,因此目前的 SOTA 多采用“精确+线性”的混合模式(如 SLA)。
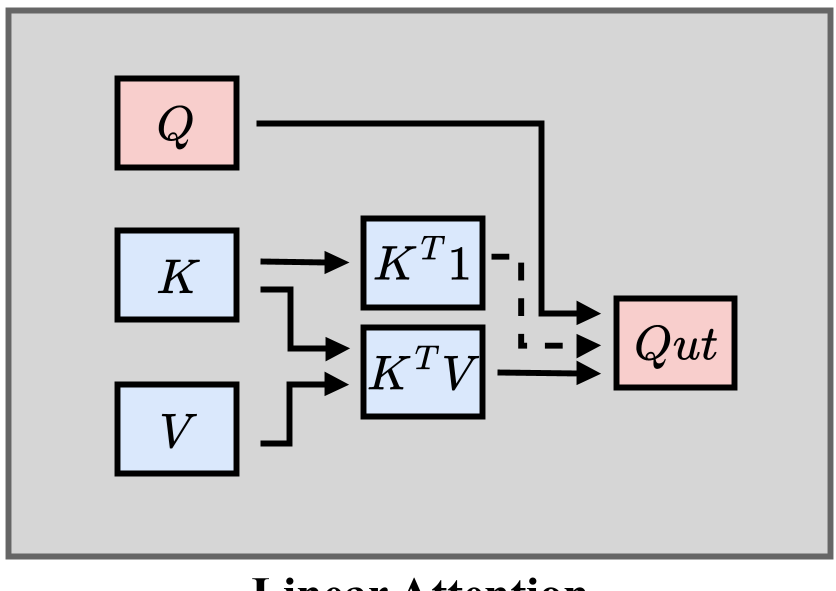
3. 模型压缩与量化 (Compression & Quantization)
- PTQ (Post-Training Quantization):对 VDM 而言,关键在于“时间戳感知”。去噪在不同阶段的激活分布完全不同,因此需要动态缩放因子(如 TaQ-DiT)。
- VAE 压缩:直接在源头截流,减少 Latent 序列的长度。
4. 缓存与轨迹优化 (Cache & Trajectory)
- 特征缓存 (Feature Cache):相邻去噪步骤的特征图其实很像,DiCache 等方法利用这种冗余跳过中间层的计算。
- 并行计算:利用底层系统的并行性(Patch Parallelism, Sequence Parallelism)来换取延迟。
实验与前沿战绩:速度与质量的权衡
论文系统对比了各种加速方案在 VBench 和 FVD 指标上的表现。在复合加速(Composite Acceleration)路径下,将步骤蒸馏与稀疏注意力结合(例如 FastVideo 项目)已经能让高清视频生成接近实时性能。

深度洞察:未来的三个关键方向
- 复合加速的“误差累积”效应:当我们同时使用 4-bit 量化、稀疏注意力和单步蒸馏时,累积的近似误差会显著降低视频的“运动丝滑度”。未来的研究重点将是显式的误差平衡与补偿机制。
- 软硬协同设计:稀疏注意力在算法上很美,但如果 kernel 实现不到位(如非对齐内存访问),实际速度可能不如暴力全量计算。Triton 和 TileLang 等底层工具将成为算法工程师的必备。
- 从离线到实时流式:生成式世界模型(World Models)需要无限长的视频流,传统的“生成 10 秒看 10 秒”模式将演变为真正的低延迟预测,这不仅是加速问题,更是状态空间管理 (KV-Cache Management) 问题。
总结
视频加速不只是一场关于 FLOPs 的数字化算法游戏,更是一场关于硬件极限、认知冗余与数学近似的精密平衡。这篇论文为我们在疯狂迭代的生成式视频浪潮中,提供了一份极具工程参考价值的航海图。