本文推出了 Ego2Web,这是首个将第一人称视角(Egocentric)视频感知与 Web 智能体执行相结合的基准测试。该研究通过 500 个高质量的“视频-指令”对,要求智能体根据现实世界的视觉语境(如识别 AR 眼镜看到的物体)在 Amazon、YouTube 等网站完成在线任务。
TL;DR
长期以来,AI 智能体被困在“数字围墙”之内。即便强如 Claude Computer-Use 或 OpenAI Operator,它们也只能在浏览器截图里打转,对你桌上放着的咖啡杯或运动鞋一无所知。Google DeepMind 近期发布的 Ego2Web 首次打破了这层隔阂,通过 500 个基于第一人称视角(Egocentric)视频的 Web 任务,迫使智能体必须先“看懂现实”,再“操作网页”。
痛点深挖:被视觉阉割的 Web 智能体
现有的 Web 智能体研究(如 WebArena, OSWorld)默认任务指令是纯文本的,或者所有信息都已存在于网页 DOM 树中。但在现实辅助场景中(例如佩戴 AR 眼镜时),用户的指令往往是模糊且高度依赖环境的:
- “帮我买一下我刚刚拿起的那个口味的燕麦片。”
- “在 YouTube 上找这个景点的旅游攻略。”
痛点在于:如果智能体无法将视频中的非结构化视觉线索(品牌、颜色、特定动作顺序)与网页上的符号化信息匹配,这种“助手”就永远无法真正融入物理生活。
核心机制:跨模态的“物理-数字”桥接
Ego2Web 的核心贡献在于建立了一套高度可靠的自动化流水线,将 Ego4D 等大规模第一人称视频库转化为可评估的 Web 任务。
1. 数据生成:从像素到决策
作者使用 MLLM(如 Qwen3-VL)对视频进行每 5 秒一帧的密集描述(Dense Captioning),形成“视频档案”。随后由 LLM 充当规划器,参考档案内容从 Amazon、Google Maps 等 18 个主流网站中挑选合适的执行目标。
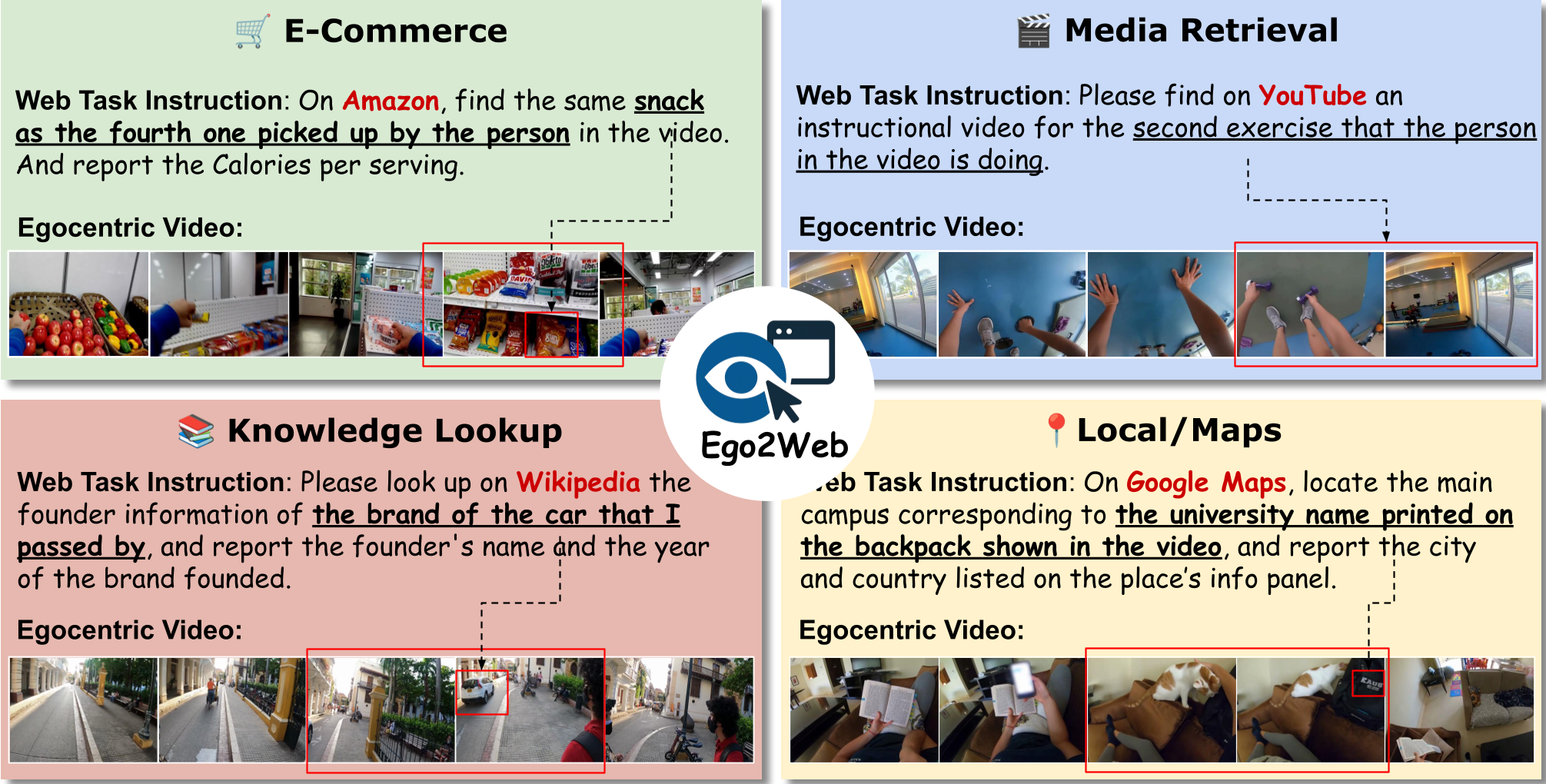 图注:智能体需要从视频中定位视觉线索(如第四个捡起的零食),然后在电商网站执行精准匹配。
图注:智能体需要从视频中定位视觉线索(如第四个捡起的零食),然后在电商网站执行精准匹配。
2. 评估突破:Ego2WebJudge
在线评估(Online Evaluation)一直是 Web 任务的难题,因为真实网页在动态变化。本文提出的 Ego2WebJudge 引入了“关键证据感知”:
- 关键点提取:将复杂指令拆解为可验证的支点。
- 截图过滤:为避免上下文溢出,仅保留与任务相关的关键网页截图。
- 视频比对:法官模型会直接审阅视频关键帧,确保智能体买到的商品或搜索的信息与视频中的实物完全一致。
实验战绩:全员表现不佳,Gemini 暂时领先
研究人员测试了包括 GPT-5.4(预测性命名/最新版)、Claude 3.7/4.5 和 Gemini 3-Flash 在内的 6 种主流智能体。
| Agent | 人类评分成功率 (SR) | Ego2WebJudge (GPT-4o) | | :--- | :--- | :--- | | BU-Gemini-3-Flash | 58.6% | 51.4% | | BU-GPT-4.1 | 44.4% | 47.6% | | Claude 4.5 | 32.8% | 27.2% |
关键洞察 (Insights):
- 视频胜过文本锚点:对于无法直接处理视频的模型(如当时的 Claude),即使提供极其详尽的文字描述,性能也远逊于能直接读取原始视频流的模型。信息的降维打击不可避免。
- 时空感知的缺失:大量的失败案例源于“时间序误解”。例如,指令要求买“第二个拿起的瓶子”,智能体往往会搞混动作顺序。
- 跨模态检索瓶颈:即便模型认出了物体,但在网页上精准定位对应参数(如特定的盎司重量、匹配的型号)依然极易出错。
 图注:一个典型失败案例。智能体因为由于时间序列理解错误,将视频中的第二个酱料误认为芥末,导致后续所有 Web 操作“南辕北辙”。
图注:一个典型失败案例。智能体因为由于时间序列理解错误,将视频中的第二个酱料误认为芥末,导致后续所有 Web 操作“南辕北辙”。
深度总结:通往具身 Web 助手之路
Ego2Web 的出现标志着智能体评估从“纯文本驱动”向“感知驱动”的范式转移。
- 它的价值:它定义了未来 AR 时代智能体的生存标准——不仅要会点按钮,还要会“看眼色行事”。
- 局限性:目前 500 条样本规模相对较小,且主要集中在主流网站,对于长尾网页的覆盖有待加强。
- 未来前景:随着多模态大模型对视频 Token 处理效率的提升,我们可能会看到真正的“原生视频智能体”,它们不再需要中间的文字转换,而是直接在像素和代码之间建立条件概率。
Senior Editor's Note: 该研究最值得关注的是其评分框架的准确性。在动态、未闭环的 Web 环境中,能达到 84% 的人机评价一致性,为未来大规模部署自动化智能体测试提供了重要的工程参考。