本文推出了 EgoForge,一个目标导向的第一人称(Egocentric)世界模拟器。该方法通过单一静态图像、高层指令及可选的第三人称(Exocentric)参考图,利用 VideoDiffusionNFT 奖励引导精修技术,实现了 SOTA 级别的连贯第一人称视频生成。
TL;DR
EgoForge 是一项突破性的第一人称(Egocentric)视频生成技术。它只需一张初始照片和一句指令(如“倒杯水”),就能生成极其真实、符合物理逻辑的动作视频。通过创新的 VideoDiffusionNFT 轨迹精修技术,它在视频连贯性和意图对齐上全面超越了目前最强的视频大模型。
1. 背景:为什么第一人称模拟这么难?
在自动驾驶或通用视频生成领域,模型通常处理的是相对平稳的视角。但第一人称视角(从佩戴者的眼镜或头显出发)面临三大难题:
- 视角的剧烈晃动:人类头部运动会导致画面快速位移和旋转。
- 精细的手物交互:如倒水、切菜,对空间几何重构要求极高。
- 未知的潜示意图:未来的画面演化完全取决于“人的意图”,而不仅仅是像素外推。
以往的方法要么需要昂贵的传感器数据(如同步的 IMU 轨迹),要么在生成长视频时逻辑崩溃。
2. 核心架构:几何感知与意图对齐
EgoForge 基于 Diffusion Transformer (DiT) 架构,其核心设计包含两个关键支柱:
2.1 几何弱监督 (Geometry Weak Supervision)
为了防止生成的视频出现“物体漂移”或“逻辑违背”,作者将 DiT 的中间特征与预训练几何模型(VGGT)进行对齐。通过 余弦对齐损失 (L_ang) 和 尺度对齐损失 (L_sca),强制模型在理解像素的同时理解 3D 空间结构。
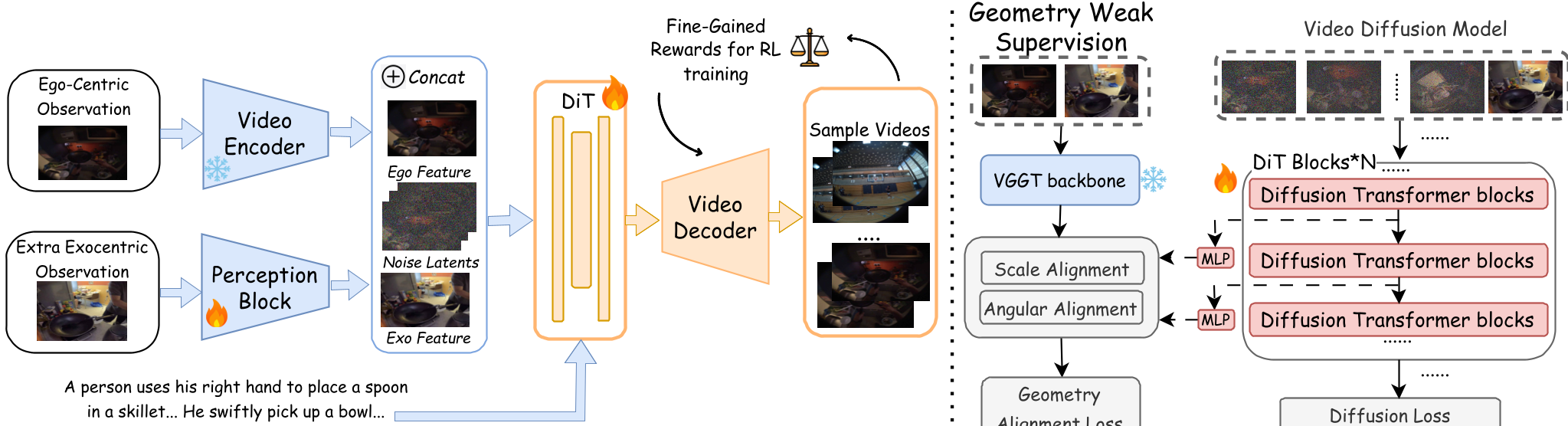
2.2 VideoDiffusionNFT:轨迹级奖励引导
这是本文的“杀手锏”。模型生成多个视频候选(Rollouts),然后由四个维度的奖励函数进行评价:
- R_goal (目标达成):最后画面是否完成了任务?
- R_env (场景一致性):背景是否在莫名其妙地变化?
- R_temp (时间因果性):动作是否符合物理规律(如先抓笔再写字)?
- R_per (感知保真度):视觉是否清晰?
通过这种 负向感知流匹配(Negative-aware flow-matching),模型学会了避开那些虽然好看但逻辑错误的路径,从而生成高度对齐的模拟效果。
3. 实验战绩:全方位降维打击
研究团队构建了 X-Ego 基準数据集,包含 1.5 万条高质量第一人称标注数据。
3.1 定量对比
实验显示,EgoForge 在关键指标上刷新了纪录:
- FVD (视频真实度) 降低 43%:生成的动作更加自然,没有常见的“果冻效应”。
- Flow MSE (运动精度) 降低 51%:这证明了该模型对第一人称特有的运动模式有极深的理解。
- CLIP-Score 提升 10.1%:生成的视频能更精准地遵循“打开冰箱拿出牛奶”等复杂指令。

3.2 定性展示:当通用大模型遇到“硬骨头”
在处理如“洗手”或“踢足球”这类长时延任务时,普通的 SOTA 模型(如 Cosmos 或 HunyuanVideo)经常出现“第三只手”或物体凭空消失的幻觉。如图 4 所示,EgoForge 能保持完美的手物几何关系。

4. 深度洞察:迈向交互式具身智能
EgoForge 的意义不仅在于生成了一段好看的视频,而在于它构建了一个**“可控的心理模拟器”**。
- 跨视角引导:它能将第三人称的参考图(Exo-view)转化为第一人称的动作序列,这为机器人模仿学习提供了绝佳的模拟环境。
- 智能眼镜应用:在 ARGO 智能眼镜上的实测证明,该模型具备处理真实世界噪声(OOD 数据)的鲁棒性。
5. 局限与未来
虽然 EgoForge 表现优异,但其计算开销依然较高(H100 集群训练超过 100 小时)。未来的方向可能在于如何将这种“离线奖励引导”转化为更高效的在线闭环控制器。
总结:EgoForge 通过引入轨迹级的强化学习反馈,成功解决了第一人称模拟中“意图-物理-感知”三者统一的难题。这是通往沉浸式数字孪生和具身智能的关键一步。