本文提出了 Elastic Looped Transformers (ELT),一种通过参数共享的循环 Transformer 架构实现的极高参数效率的视觉生成模型。该方法在 iso-inference-compute(同等推理计算量)下,比 MaskGIT 和 MAGVIT 等基线模型减少了 4 倍参数,并在 ImageNet (FID 2.0) 和 UCF-101 (FVD 72.8) 任务中达到了 SOTA 性能。
TL;DR
在视觉生成领域,模型深度往往与参数量成正比,这导致了巨大的内存开销。Elastic Looped Transformers (ELT) 的出现改写了这一逻辑。通过将 Transformer 层进行“循环式”权重共享,并通过创新的环内自蒸馏 (ILSD) 算法,ELT 不仅将参数量降低了 75%,还实现了“随时推理”:同一个模型,你可以根据算力水平选择跑 2 遍还是 8 遍循环,且都能获得连贯的生成结果。
核心定位
ELT 是对当前视觉生成模型(如 DiT, MaskGIT)的一次底层架构级重构,它定位在极端参数效率与弹性计算的交叉点。它不是通过剪枝或量化这种事后手段,而是从架构设计和训练目标入手,让模型学会“反复精炼”特征。
痛点深挖:为何我们需要循环架构?
现有的生成模型(如 Stable Diffusion 3 或 Sora 基座)面临两个核心瓶颈:
- 内存墙 (Memory Wall):每一层唯一的权重都需要频繁地从内存加载到计算单元,即便计算量相同,庞大的参数量也拖慢了吞吐量。
- 刚性推理:模型深度在训练后固定。如果资源受限,你很难在不重训练的情况下让一个 32 层的模型只跑 16 层。
传统的循环 Transformer 虽然能省参数,但存在收敛滞后问题:只有跑完最后一圈,图像才是清晰的。
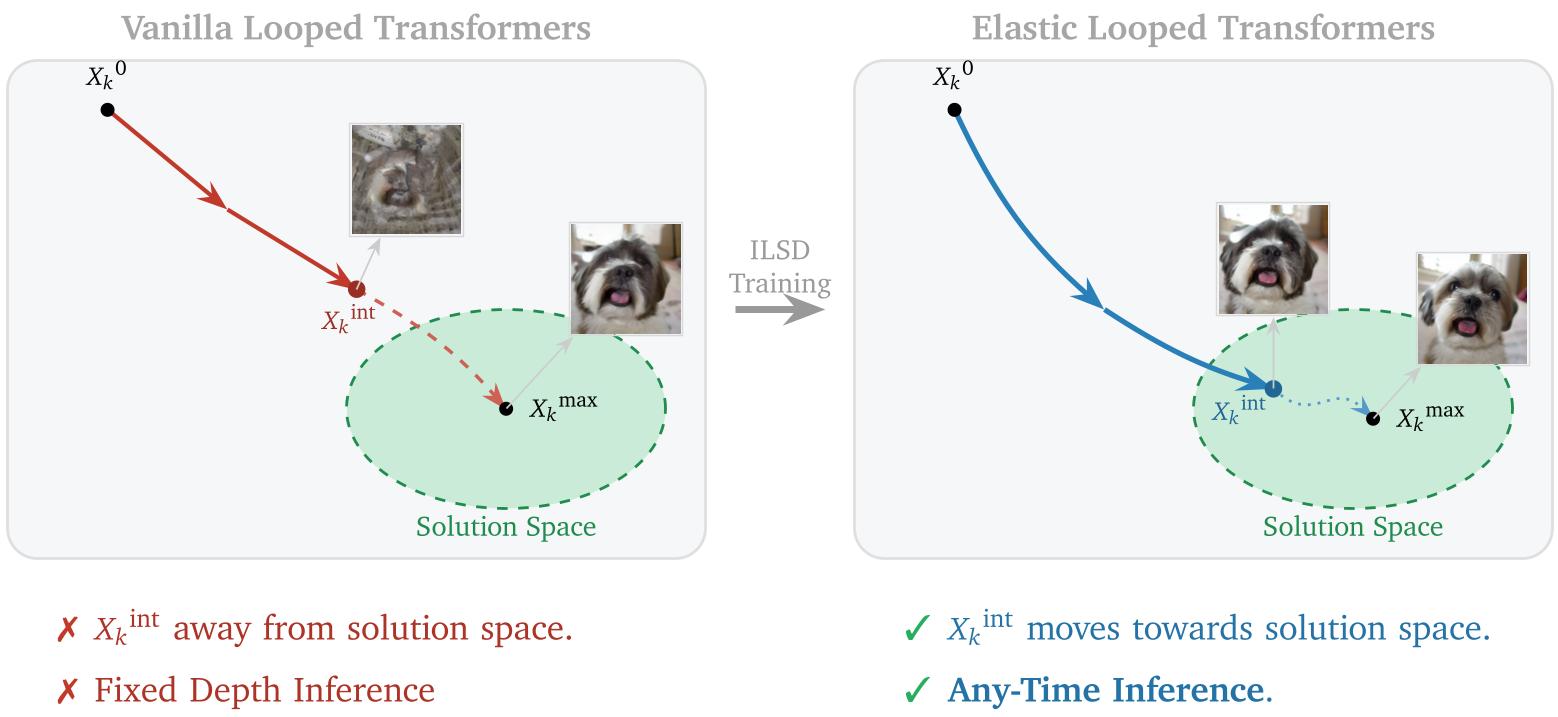 图 2:普通循环模型(左)中间态不可视,而 ELT(右)通过 ILSD 保证了中间循环的表征也是高质量的。
图 2:普通循环模型(左)中间态不可视,而 ELT(右)通过 ILSD 保证了中间循环的表征也是高质量的。
方法论详解:如何实现“弹性”?
1. 权重共享的循环块 (Recurrent Blocks)
ELT 不再堆叠 24 个唯一的层,而是定义一个包含 层的复合块 ,然后将其循环应用 次。总深度依然是 ,但存储开销仅为 层。
2. 环内自蒸馏 (ILSD)
这是 ELT 最核心的贡献。为了让模型在每一圈循环后都有实质性产出,作者提出了 ILSD:
- 教师路径:运行完整的 次循环,作为目标。
- 学生路径:随机采样中间循环次数 ,不仅要拟合真实标签(Ground Truth),还要模拟“教师”在终点产生的表征。
- 课程学习:训练初期以 GT 为主,后期逐渐转为模仿教师,确保学生层能压缩教师的复杂变换。
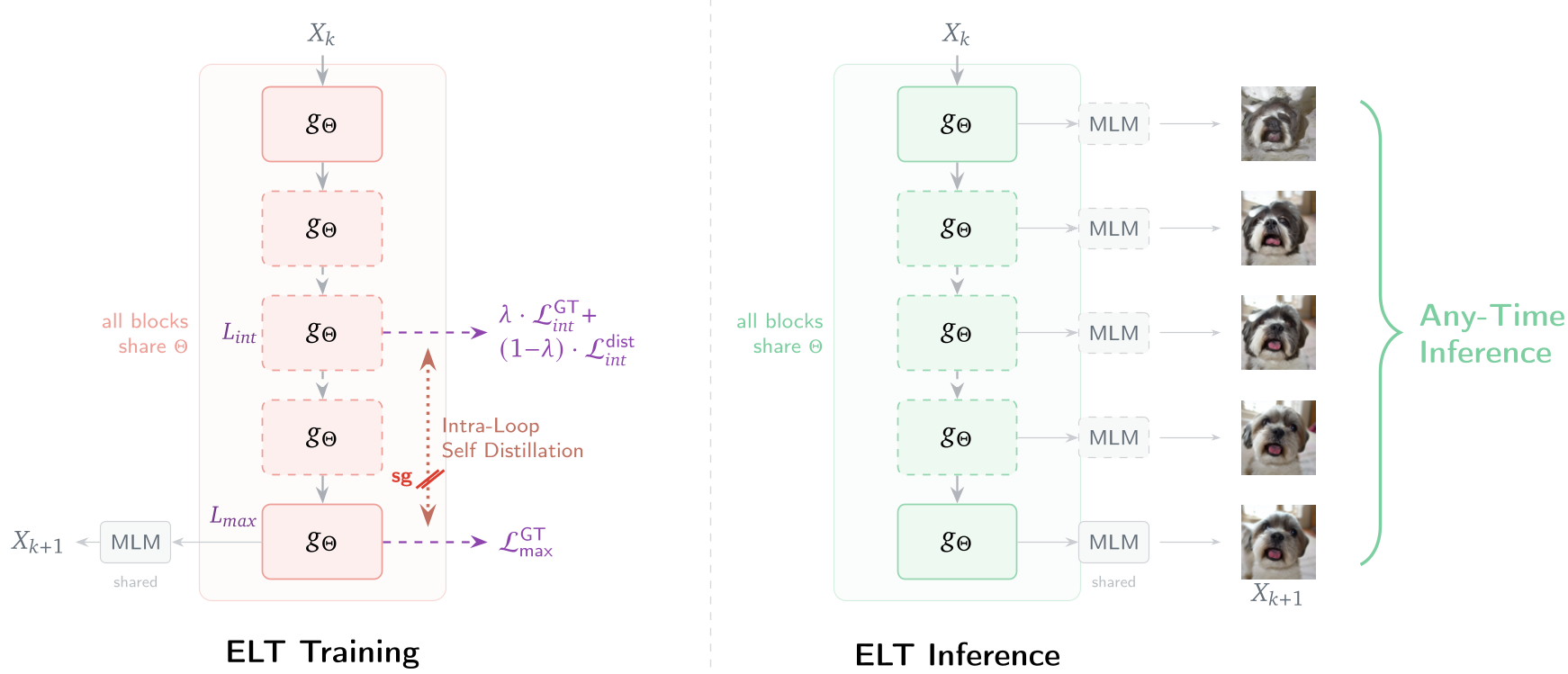 图 3:ELT 框架概览。左侧展示了训练时的双路径自蒸馏,右侧展示了推理时的“随时退出”机制。
图 3:ELT 框架概览。左侧展示了训练时的双路径自蒸馏,右侧展示了推理时的“随时退出”机制。
实验与结果:小参数也有大作为
SOTA 战绩
在 ImageNet 256x256 任务中,ELT-XL(仅 111M 参数)与拥有 446M 参数的 MaskGIT-XL 达到了相同的 FID 2.0。在视频生成任务(UCF-101)上,原本 306M 参数的模型缩减至 76M 时,性能甚至更好(FVD 从 76 提升至 72.8),这表明循环架构在小规模数据上具有更强的正则化/抗过拟合能力。
吞吐量飞跃
由于核心权重集更小,可以完全驻留在芯片级缓存(On-chip Memory)中,大幅减少了数据传输。实验显示,在 TPU 上 ELT 的吞吐量比基线高出 2.9x 到 3.5x。
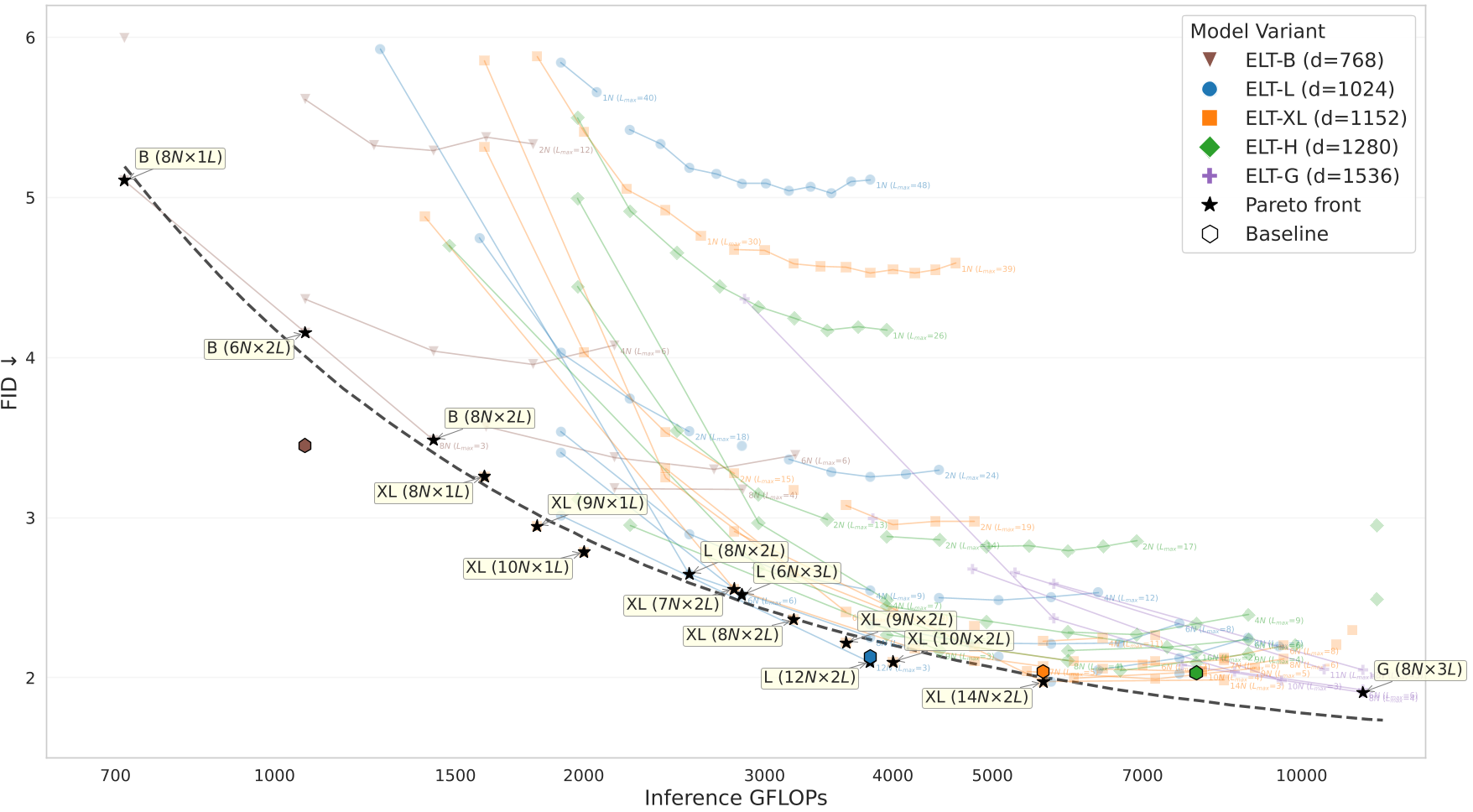 图 4:FID 与 GFLOPs 的帕累托前沿。ELT 完美覆盖了从超快推理到高质量生成的全曲线。
图 4:FID 与 GFLOPs 的帕累托前沿。ELT 完美覆盖了从超快推理到高质量生成的全曲线。
深度洞察:Any-Time 推理的未来
ELT 带来了一个非常实用的启示:对于扩散模型(Diffusion)或掩码生成模型(Masked Generative),计算量(FLOPs)不一定要与参数量绑定。
在实际部署中:
- 移动设备:可以只跑 2 次循环,快速生成低质量预览。
- 云端渲染:针对同一模型跑 8 次循环,输出精细大图。
- 一阶段生成:对于 Consistency Models 等单步生成模型,循环次数成为了唯一调节质量的动态杠杆。
局限性与总结
尽管 ELT 效率惊人,但作者也指出,循环层不能无限少(如 效果不佳),必须保证基础块有足够的表征深度。
总的来说,ELT 为视觉生成模型的工程化落地指明了新路径:不再一味追求“大模型”,而是通过“更聪明的循环”在轻量级设备上释放出 SOTA 级的表现力。这不仅是学术上的创新,更是向高效、绿色 AI 迈出的重要一步。