EmbodiedMidtrain: Solving the VLM-VLA Distribution Gap with Smart Mid-training
EmbodiedMidtrain is a mid-training framework designed to bridge the data distribution gap between general Vision-Language Models (VLMs) and robotic Vision-Language-Action Models (VLAs). By utilizing a proximity-based data engine, it selects VLA-aligned samples from massive VLM pools to create a specialized initialization that significantly boosts downstream robot manipulation performance.
TL;DR
Most Vision-Language-Action (VLA) models are built on general-purpose VLMs that have never "seen" the world through a robot's eyes. EmbodiedMidtrain introduces a specialized mid-training stage that uses a "Proximity Estimator" to cherry-pick VLA-relevant data from general web datasets. This process yields a 1.1B model that outperforms 8B+ parameters giants, proving that alignment beats scale in the embodied domain.
The "Physicality Gap": Why General VLMs Fail Robots
Modern robotics relies on fine-tuning off-the-shelf VLMs (like Llama or Qwen) into VLAs. However, there is a fundamental mismatch:
- Distributional Separation: General VLM data (e.g., LAION) focuses on object recognition and OCR, while VLA data focuses on spatial affordances and trajectories.
- Compactness vs. Breadth: VLA data forms small, dense clusters in the representation space, often far removed from the broad distribution of internet imagery.
The authors show that simply dumping VLM data into a model doesn't help because the "signal-to-noise" ratio for embodied tasks is too low.
Methodology: The Proximity-Based Data Engine
The core innovation is the Proximity Estimator. Instead of manual filtering, the researchers trained a lightweight classifier on top of frozen VLM features.
1. The Membership Game
The estimator acts as a "bouncer," learning to distinguish between:
- Positive Samples: Real robotic manipulation data (VLA).
- Negative Samples: General internet data (VLM).
2. Sample-Level Scoring
By calculating the density ratio , the model assigns a score to every VLM sample. High scores go to samples involving spatial reasoning and physical grounding; low scores go to text-heavy or abstract images.
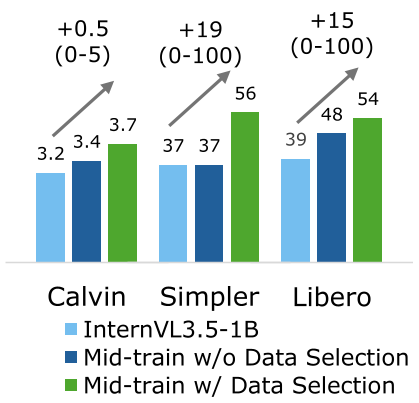 Figure 1: Visualization of the distribution gap and the mid-training pipeline.
Figure 1: Visualization of the distribution gap and the mid-training pipeline.
3. Curated Mid-training
The top-K samples are selected to form a "Mid-training" mixture. The VLM is then trained on this subset before it ever sees an action token, effectively "pre-adapting" its neurons for the physical world.
Experimental Results: Punching Above Its Weight
The efficiency of this approach is staggering. An InternVL3.5-1B model, when mid-trained with the EmbodiedMidtrain engine, was able to rival or surpass models like OpenVLA (7.7B) and Qwen2.5VL (7B).
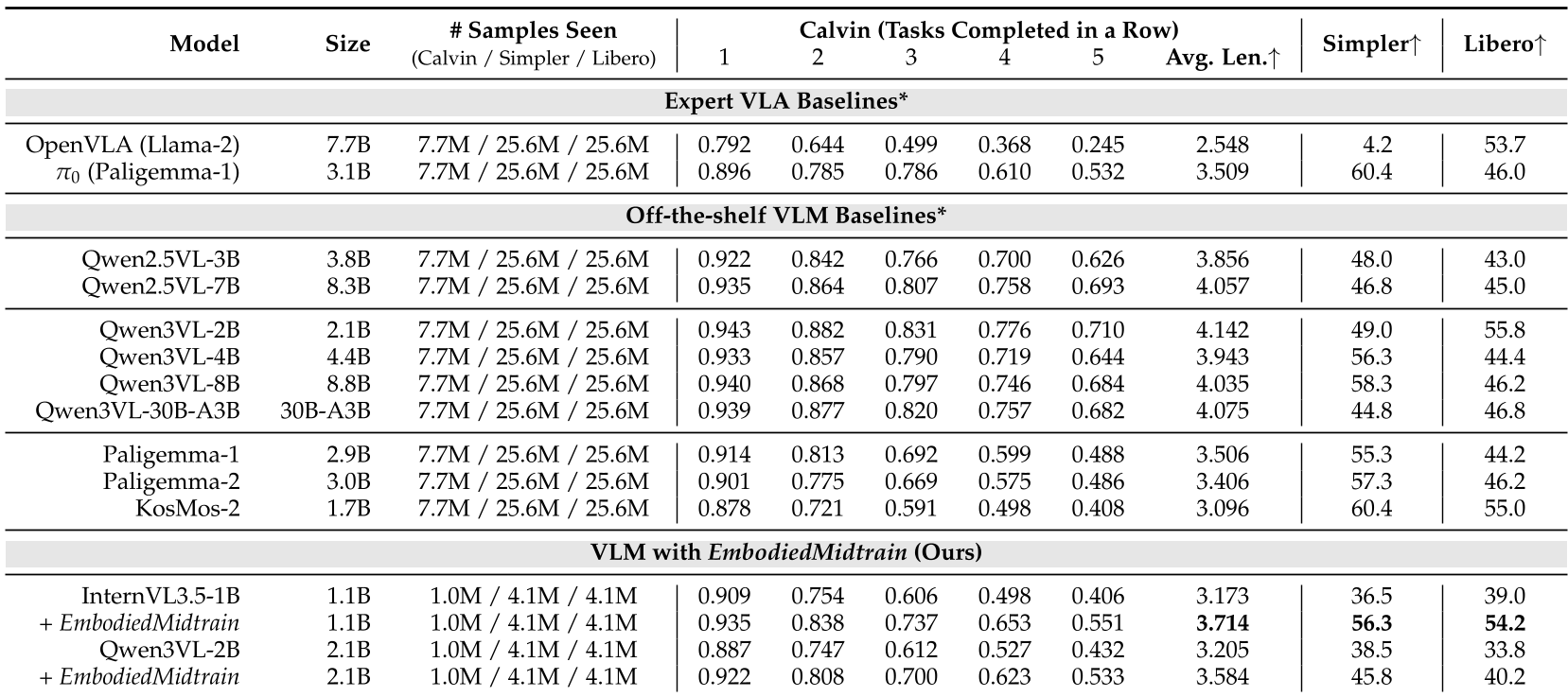 Table 1: Performance across Calvin, SimplerEnv, and Libero benchmarks.
Table 1: Performance across Calvin, SimplerEnv, and Libero benchmarks.
Key Insights from the Data:
- Early Advantage: Training dynamics show that mid-trained models start with a significantly lower error rate and higher success rate from step zero of VLA fine-tuning.
- Transferability: Data selected using an InternVL backbone also improved a Qwen3VL backbone, proving that "VLA-ness" is a universal property of the data, not just the model.
Deep Dive: What Kind of Data Does the Machine Prefer?
The proximity estimator naturally favored datasets like RefSpatial (spatial reasoning) while rejecting VCR (visual commonsense reasoning) and text-centric OCR tasks.
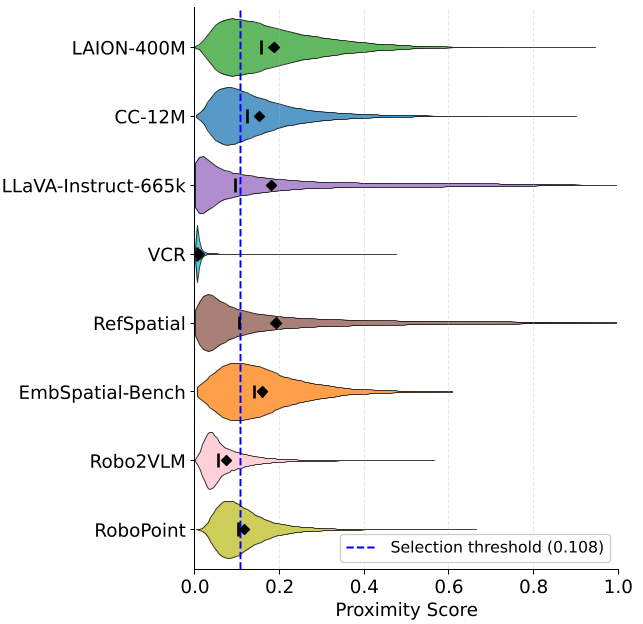 Figure 2: Violin plots showing how the estimator scores different datasets.
Figure 2: Violin plots showing how the estimator scores different datasets.
Notably, it didn't just pick "robotic" images. It selected high-diversity web images that had specific "spatial affordance" cues, such as objects being in reachable zones or scenes requiring depth perception.
Critical Analysis & Conclusion
EmbodiedMidtrain shifts the focus from "bigger models" to "better data alignment."
- Pros: Highly scalable, requires no new architecture, and dramatically reduces the compute needed for high-performing VLAs.
- Limitations: It still relies on the existence of a high-quality target VLA dataset to train the proximity estimator initially. If the target domain is extremely niche, the estimator might struggle.
- Future Outlook: This work suggests that we may soon see "Embodied Pre-trained" VLMs as a standard industry starting point, replacing generic web-trained models for all physical AI applications.
The project demonstrates that the gap between vision and action can be bridged by simply teaching the vision model to look for the right things before it starts moving.