本文提出了 Embody4D,这是一个专为具身智能设计的通用 4D 世界模型,能够从单目视频合成任意视角的动态 3D 场景。通过结合组合式数据合成、置信度感知噪声注入和交互感知注意力机制,该模型在具身场景的视角合成任务中达到了 SOTA 水平。
TL;DR
在具身智能(Embodied AI)的发展中,理解 3D 世界的动态演化是实现精准操控的关键。然而,现有的世界模型大多还“活在 2D 屏幕里”。本文介绍的 Embody4D 成功实现了从 2D 单目视频到支持任意视角切换的 4D(动态 3D)场景的跃迁。通过创新的数据合成管线和精细的几何约束机制,它不仅能生成高度逼真的交互视频,还能直接作为“数据工厂”,将机器人的操控成功率从 32% 暴力提升至 74%。
背景:为什么 4D 世界模型如此艰难?
具身智能体需要理解空间深度、物体遮挡以及动作导致的视觉变化。传统的 2D 视频预测模型在面对大幅度视角转换时,往往会出现“物体消失”、“机械臂扭曲”等非物理现象。这主要归结为三个难题:
- 数据荒:同时拥有多视角、动态流、多种类机械臂的真实数据集几乎不存在。
- 时空不一致:在不同视角间切换时,几何结构容易发生抖动或形变。
- 交互幻觉:机械臂捏取物体时的关键触点(Contact Points)很难在生成过程中完美保留。
核心方法:几何直觉驱动的生成架构
Embody4D 并没有盲目堆砌计算量,而是通过引入物理与几何的先验知识来约束生成过程。
1. 组合式 4D 数据合成 (Compositional Synthesis)
由于缺乏现成的 4D 训练数据,作者提出了一种“ foreground-background”组合策略。他们从 MuJoCo 中提取了 30 多种机械臂模型,在仿真环境中执行随机动作,并结合 GPT-4o 筛选出具有真实感且视角匹配的背景视频。这种方式解决了跨形态机械臂的泛化难题。
 图 1:Embody4D 的核心理念:从单目 2D 视频中提取信息并映射到 4D 空间,支持任意 POV 合成。
图 1:Embody4D 的核心理念:从单目 2D 视频中提取信息并映射到 4D 空间,支持任意 POV 合成。
2. 置信度感知的自适应噪声注入
这是本文最具“物理直觉”的创新。传统的扩散模型(Diffusion)或流匹配模型(Flow Matching)在去噪时是全图均匀分配权重的。但 Embody4D 利用点云重投影技术,判断出哪些区域是“已知的物理部分”(高置信度),哪些是“遮挡出的盲区”(低置信度)。
- 高置信度区:注入较低噪声,强制锁定纹理和结构。
- 低置信度区:注入较高噪声,给模型更多“生成自由”来填补空洞。
3. 交互感知注意力 (Interaction-Aware Attention)
为了防止机械臂在操作物体时产生形变,模型引入了基于 SAM 3 或光流的分割掩码作为 Bias。在 Transformer 的注意力计算中,显式地让 Q, K, V 矩阵更多地关注交互核心区域(如夹持器与物体的接触面),从而显著提升了物理操作的保真度。
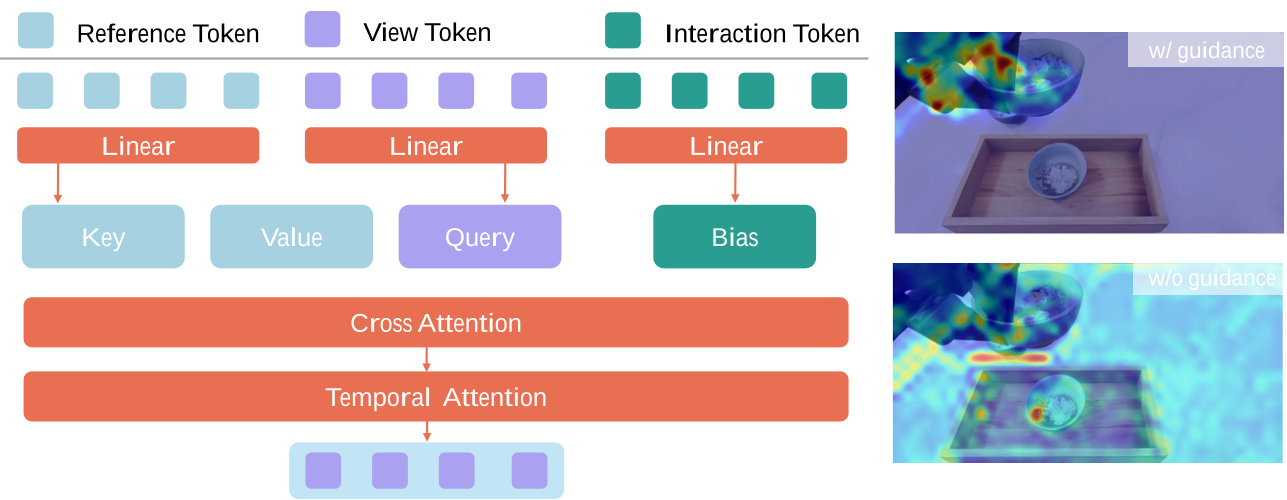 图 2:交互感知注意力机制,通过分割掩码引导模型关注动态操控区域。
图 2:交互感知注意力机制,通过分割掩码引导模型关注动态操控区域。
实验战果:通往通用数据引擎之路
Embody4D 在 VBench 视频生成基准测试中全面刷新纪录。相比之前的 SOTA 模型 TrajectoryCrafter,它在主体一致性上表现尤为强劲。
关键实验数据:
- 视觉质量:Q-Align 得分 3.997,优于所有基线。
- 真实机器人部署:在 Franka 机械臂上的 Pick-and-Place 实验中,相比单视角策略,添加了 Embody4D 合成视图的策略在 OOD(分布外)任务上的泛化能力大幅增强,整体成功率提升了 130%。
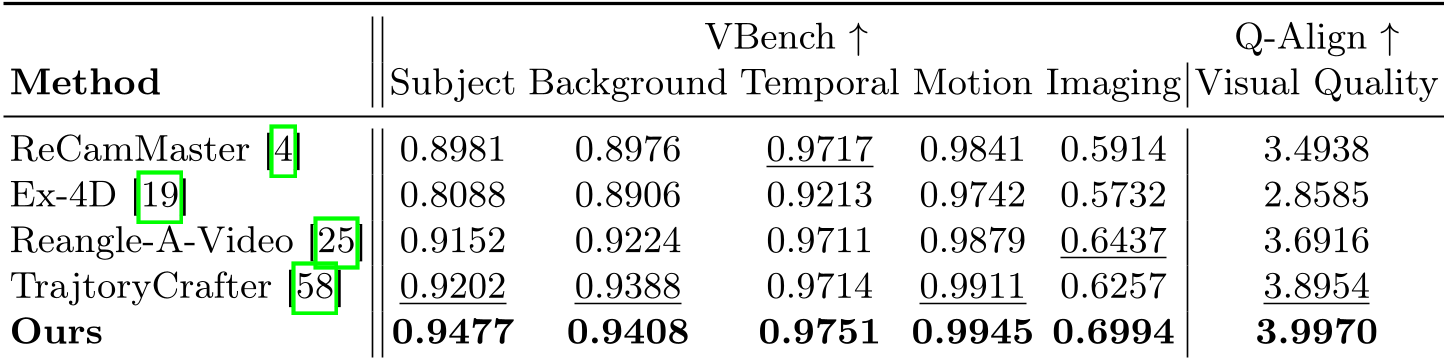 表 1:与 SOTA 方法在多项指标上的量化对比。
表 1:与 SOTA 方法在多项指标上的量化对比。
深度洞察与总结
Embody4D 的价值在于它不仅是一个“视频生成器”,更是一个“具身知识提取器”。它告诉我们,要在机器人领域应用生成式 AI,单纯的 Scaling Law 可能不够,几何引导(Geometric Grounding) 和 区域敏感的噪声调度 才是通向高性能世界模型的捷径。
局限性: 目前的模型在处理极端视角的剧烈跳转时仍有压力,且推理速度(生成 49 帧需 2 分钟)距离实时闭环部署还有距离。
未来启示: 随着万亿级参数 VLA 模型的普及,将 4D 生成能力作为预训练任务的一部分,可能会让机器人第一次真正拥有“空间想象力”。