UNITE is a novel single-stage autoencoder architecture that unifies image tokenization and latent diffusion through a shared "Generative Encoder" (GE). By training the model to serve as both a reconstructive tokenizer and a flow-matching denoiser via weight sharing, it achieves near-SOTA results on ImageNet-256 (gFID 1.73) and molecule generation (QM9) without relying on external pretrained encoders or adversarial losses.
TL;DR
For years, the recipe for Latent Diffusion Models (LDMs) has been rigid: first, train a VAE/tokenizer; then, freeze it; finally, train your diffusion model. UNITE (Unifying Tokenization & Latent Generation) flips the script. It proposes a single-stage, end-to-end framework where a single Generative Encoder performs both tokenization and denoising. By sharing weights, the system learns a "common latent language," achieving state-of-the-art generation and reconstruction results from scratch, without the need for DINO-style pretraining or GAN losses.
Problem & Motivation: The "Staging" Tax
Current state-of-the-art models (like Stable Diffusion or DiT) treat tokenization and generation as separate design problems. While convenient, this departs from the principle of end-to-end learning.
- Frozen Latents: The generator cannot influence the representation space it operates in.
- Complexity: Pipelines involve multiple training stages and different model architectures.
- Dependency: Recent "end-to-end" attempts often rely on huge pretrained teachers (like DINOv2) to act as a "semantic anchor," making them difficult to use in domains like molecule or crystal generation where such teachers don't exist.
The authors' core insight: Tokenization and generation are two sides of the same coin. Tokenization is just generation under "strong observability" (the image is visible), whereas generation is inference under "weak observability" (only noise is visible).
Methodology: The Generative Encoder (GE)
The architecture is elegantly simple, consisting of only two modules: the Generative Encoder ($GE_ heta$) and a Decoder ($D_\phi$).
The Two-Pass Workflow
In every training iteration, the GE performs a "double duty" through shared weights:
- Pass 1 (Tokenization): Image patches are processed alongside "latent register tokens." The tokens absorb the image information to create the clean latent $z_0$.
- Pass 2 (Denoising): The same clean latent $z_0$ is corrupted with noise to $z_t$. The GE then takes $z_t$ and attempts to predict the original $z_0$.
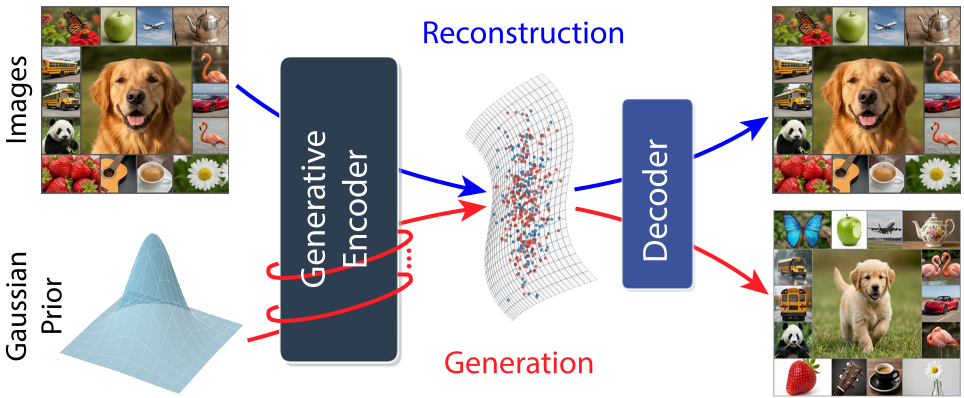
By forcing the same weights to handle both tasks, the reconstruction objective ensures the latents are informative, while the generative objective ensures they are robust and easy to model.
Experiments: SOTA Without the "Teacher"
UNITE's results are striking because they don't use the standard "cheats" (no GAN losses, no pretrained DINOv2).
Image Generation (ImageNet-256)
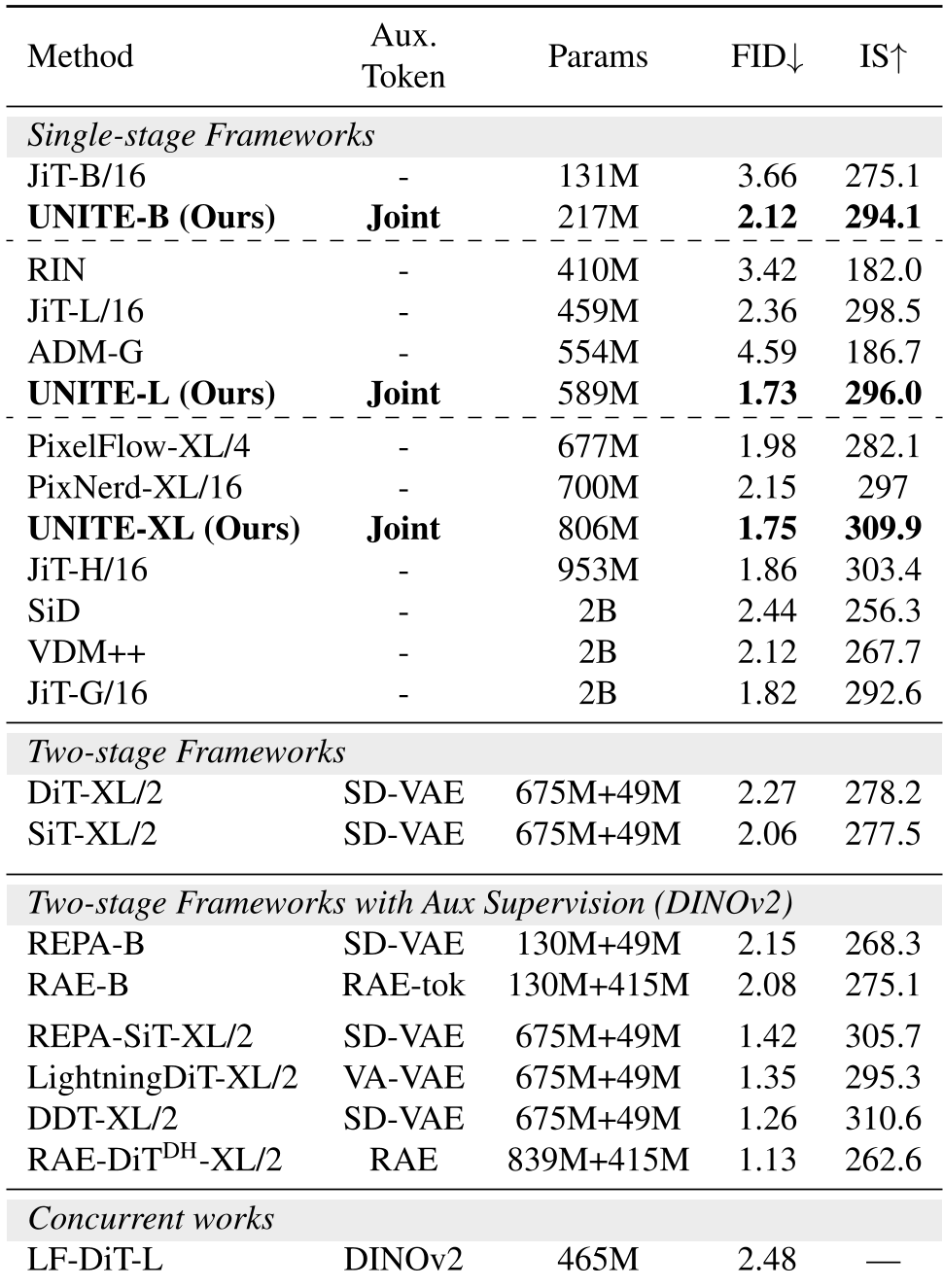
UNITE-L achieves a gFID of 1.73, outperforming established two-stage models like DiT-XL/2 (2.27). Remarkably, UNITE-B is 15x cheaper to train than methods relying on DINOv2 pretraining, because it learns everything from scratch.
Molecule & Crystal Synthesis
Because UNITE doesn't need a pretrained visual encoder, it excels in non-vision domains. On the QM9 molecule dataset, it achieved a 99.37% match rate, setting a new benchmark for unified molecular modeling.
Deep Insight: Why Does Weight Sharing Work?
The authors performed a Centered Kernel Alignment (CKA) analysis to see how similar the "Encoder" features were to the "Denoiser" features. They found that even without weight sharing, these tasks naturally align.
Weight sharing simply capitalizes on this intrinsic compatibility. The internal Attention and MLP layers are largely reused; the model only needs to adjust its layer normalization parameters to distinguish between the "Tokenization mode" and "Denoising mode."

Critical Analysis & Conclusion
Takeaway: UNITE proves that we no longer need to freeze our tokenizers. Joint training creates a more "natural" latent space that balances information density with generative stability.
Limitations:
- Linear Probing: Despite the high generative quality, the latents only achieve ~30% linear probing accuracy on ImageNet, suggesting that generative latents aren't yet "perfect" for discriminative tasks like classification.
- Complexity of Dynamics: The training can feel "adversarial," where the denoising loss might increase while the actual image quality improves—a behavior familiar to GAN researchers but potentially tricky for those used to standard diffusion.
Future Work: The unification of tokenization and generation is a gateway to the "Wake-Sleep" style of learning, potentially leading to models that can "dream" to improve their own world-modeling capabilities—a crucial step for future robotics and autonomous agents.