本文提出了 UNITE,一种通过共享参数的“生成式编码器 (Generative Encoder)”实现统一 Tokenization 和潜空间扩散(Latent Diffusion)的端到端架构。该方法在 ImageNet-256 任务上达到了 FID 2.12 (Base) 和 1.73 (Large) 的 SOTA 性能,且无需预训练编码器或对抗损失。
TL;DR
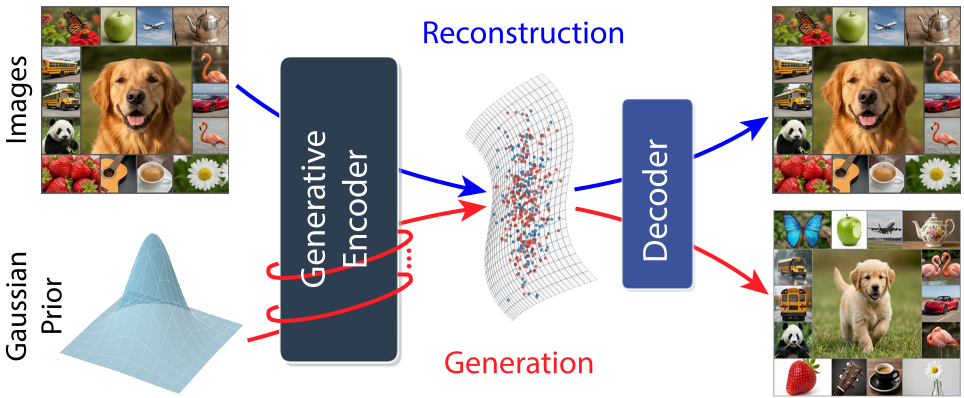
在传统的生成模型(如 Stable Diffusion)中,我们习惯先训练一个 VAE(Tokenizer),冻结它,再在其潜空间上训练扩散模型。UNITE (Unified Tokenization & Generation) 彻底颠覆了这一范式。它通过一个生成式编码器 (Generative Encoder) 同时充当 Tokenizer 和 Denoiser,不仅实现了单阶段(Single-stage)从零训练,还在 ImageNet 256x256 上以更少的参数量超越了 DiT 等经典二阶段模型。
核心洞察:观测程度的不同决定了任务属性
作者提出了一个极具物理直觉的观点:Tokenization 和 Generation 本质上是同一种潜空间推理问题。
- Tokenization(强观测):当你看到完整的图像 时,模型诱导出一个高度集中的潜变量分布。
- Generation(弱观测):当你只看到噪声 时,模型需要利用学到的先验来推断目标潜变量。 既然逻辑一致,为什么要用两个模型?
方法论:Generative Encoder (GE) 的双重人格
UNITE 的架构极为精简,仅包含一个生成式编码器 和一个解码器 。
1. 训练流程的“双通”机制
在同一个训练步中,模型执行两次前向传播:
- Step 1 (Tokenization): 将图像 patches 与 个寄存器 Tokens 拼接。通过 Attention,图像信息“蒸馏”到寄存器中,产出潜变量 。
- Step 2 (Denoising): 将 加噪得到 ,再次输入同一个 (此时不接图像 patches),要求它预测 clean latent 。
2. 停止梯集的艺术 (Stop-Gradient)
为了防止去噪目标导致潜空间坍缩(Degeneracy),作者在去噪支线中对 使用了 stop_gradient。这意味着去噪梯度仅通过 GE 自身的权重影响模型,而不会直接通过潜变量暴力干预 Tokenizer 的产出,保持了潜空间的语义丰富性。
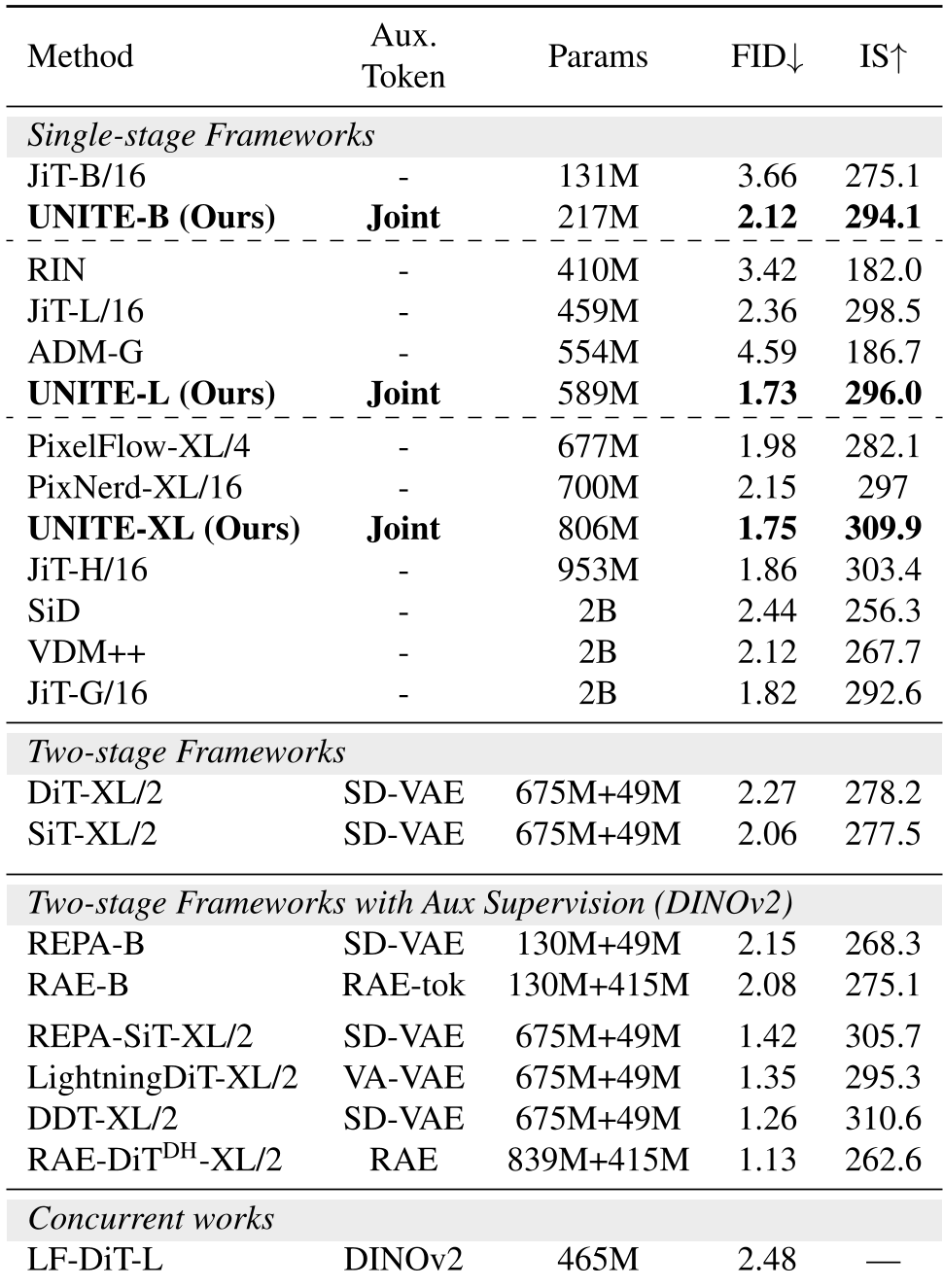
实验战绩:无需“老师”也能拿高分
UNITE 最大的优势在于从零训练(From Scratch)。当前的许多 SOTA 方法(如 REPA, RAE)都依赖于成熟的 DINOv2 预训练模型作为“支架”。
- ImageNet 256 成绩单:UNITE-L 在不使用任何外部预训练监督的情况下,FID 达到 1.73,优于使用 SD-VAE 的 DiT-XL/2 (2.27)。
- 领域通用性:在分子生成(QM9)领域,由于缺乏像 DINO 这样成熟的预训练模型,UNITE 的端到端优势得到完全释放,重建匹配率提升至 99.37%。
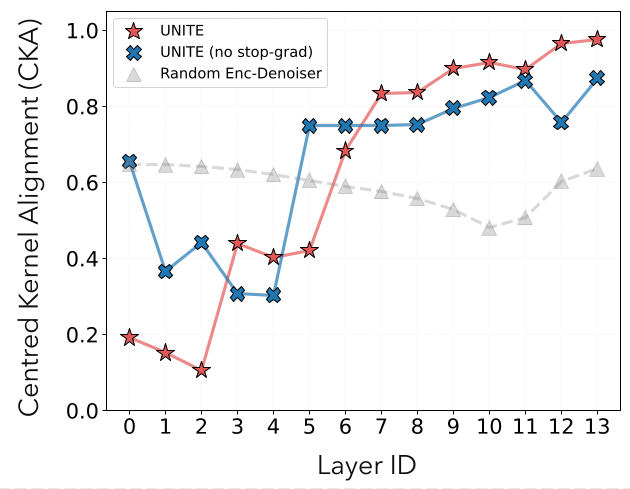
深度分析:为什么共享权重有效?
作者通过 CKA (Centered Kernel Alignment) 分析发现,即便不共享权重,Tokenizer 和 Denoiser 的内部激活层也展现出极高的对齐性。 这说明这两项任务在底层逻辑上是内在兼容的。 共享权重只是顺水推舟地消除了冗余。更有趣的是,模型通过 Normalization 层 来区分这两种模式:Attention 和 MLP 计算是通用的,而 Normalization 则负责调整不同模式下的特征量纲。
局限性与展望
尽管生成能力惊人,UNITE 的线性分类能力(Linear Probing)仅约 30%,表明高度压缩的潜变量虽然足以重建和生成,但尚未能直接作为强大的判别式特征。未来的研究可能会尝试引入 JEPA 或 DINO 式的自监督目标来增强其语义理解能力。
总结
UNITE 是一篇极具优雅感的工作。它通过回归“统一模型”的本质,证明了通过良性地混合重建与去噪目标,我们能够构建出更简洁、更高效、且不再依赖大型第三方预训练支架的生成模型方案。这对于资源受限或特定科学领域的生成任务具有重大的实战价值。