本文提出了一个名为 InconTTS 的级联对话式 TTS 框架。该方法结合了 LLM 生成的文本样式标记 (Textual Style Tokens) 与人工精选的高质量音频提示 (Audio Prompts),通过级联 Prompting 和基于 ICL 的在线强化学习 (RL),显著提升了语音合成的风格可控性、自然度与情感表现力。
TL;DR
在对话式 AI 领域,如何让机器说话不仅“清晰”而且“有感情”,一直是学术界和工业界的痛点。Meta AI 的最新研究展示了一种高效的解决方案:InconTTS。它通过将少量的音频示例(Audio Prompts)转化为上下文学习(ICL)信号,结合创新的在线强化学习优化,成功在不依赖海量标注数据的情况下,实现了超越 GPT-4o 的情感表现力。
背景定位:从“播音腔”到“共情对话”
传统的 TTS 系统要么依赖预定义的粗粒度标签(如:高兴、生气),要么需要极大规模的精细标注数据集。Meta AI 认为,对话的精髓在于上下文关联的韵律变化。该工作位于对话式 TTS 的前沿,利用大语言模型(LLM)的理解能力与级联生成架构的灵活性,探索了端到端语音交互的高级形态。
痛点深挖:数据饥渴与幻觉困局
- 标注成本极高:收集包含细微情感偏移的语音数据并进行精确标注,其成本在多语种、多风格场景下几乎无法持续。
- 后处理效率低下:为了获得高质量音频,常用方法是“多抽样+重排序”,但这极大增加了推理延迟。
- 幻觉与漂移:自回归模型在长对话中容易产生文本无关的杂音(幻觉),或者出现说话人音色逐渐变质(Speaker Drift)的问题。
核心方法:级联 Prompting + ICL 在线 RL
1. 级联 Prompting 架构
系统首先通过 LLM 生成带样式的文本标记,随后进入两个阶段:
- AR 韵律模型:接收音频 Prompt,利用 ICL 提取韵律特征。
- 扩散声学模型:负责将韵律转化为具体的音频波形,保持音色稳定。
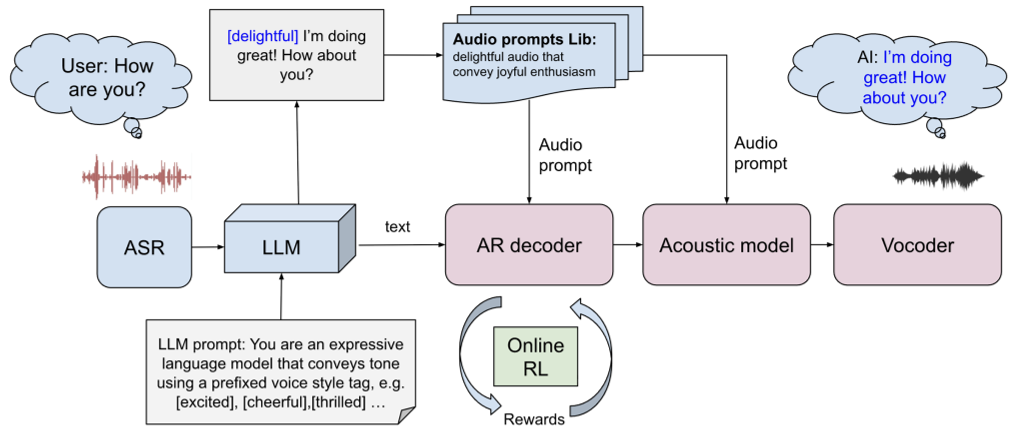 图 1:级联对话框架,结合 LLM 样式标记与音频 Prompt,通过在线 RL 进行强化。
图 1:级联对话框架,结合 LLM 样式标记与音频 Prompt,通过在线 RL 进行强化。
2. 音位对齐与审美优化
作者提出了一种巧妙的奖励函数设计,用于在线强化学习。它不仅关注音频听起来是否好听(AES-CE 评分),还引入了 CTC 损失 作为正则项。
- 为什么需要 CTC? 仅仅追求审美评分会导致模型“偷懒”,生成好听但与文字无关的内容(Reward Hacking)。CTC 确保了生成的音频与文本严丝合缝。
实验结果:情感表现力的质变
在 CVAD(清晰度、价态、唤醒度、支配度)评估框架下,InconTTS 的表现令人惊艳:
- 超越基线:相比 Zero-shot 模式,情感适合度提升了近 80%。
- 对比 GPT-4o:在情感细腻度上取得了 5.6% 的净胜率,证明了人工精选 Prompt 结合 ICL 的威力。
 表 1:不同任务下 ICL 设置相对于基线模型的 CMOS 提升。
表 1:不同任务下 ICL 设置相对于基线模型的 CMOS 提升。
有趣的是,研究还发现韵律与音色可以解耦优化。图 2 显示,在声学模型阶段降低风格的粒度,反而有助于减少多轮对话中的说话人特征漂移。
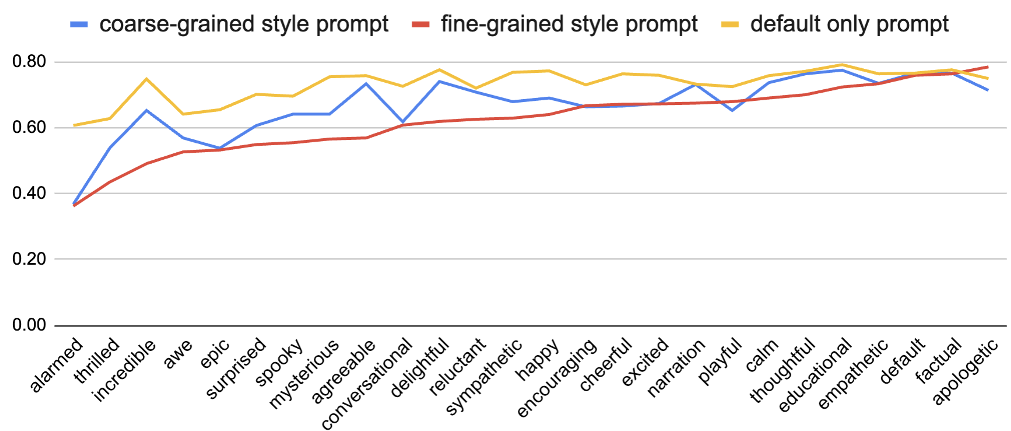 图 2:声学建模中不同风格粒度下的说话人相似度变化。
图 2:声学建模中不同风格粒度下的说话人相似度变化。
深度洞察:TTS 的未来是动态对齐
这项工作的核心价值在于提出了一种 “人机协同的闭环”:人类只需筛选极少量的种子音频,模型就能通过 ICL 泛化到无限的对话场景。
- 局限性:尽管目前效果显著,但对音频 Prompt 质量的依赖较强,未来若能实现完全自动化的高审美 Prompt 生成,将进一步释放生产力。
- 启示:未来的对话式 AI 不应仅仅是 LLM 挂载一个语音播放器,而应该是像本文这样,将语义流与表现力流深度耦合,并利用 RL 进行持续的感官对齐。
作者注:本文分析基于 Meta AI 发布的最新预印本,该技术在情感 wellness 和复杂对话场景中展现出巨大潜力。