EnterpriseRAG-Bench is a large-scale evaluation framework for RAG systems, featuring a synthetic corpus of 500,000 documents simulating internal company data. It spans nine enterprise platforms (Slack, GitHub, etc.) and includes 500 questions designed to test complex retrieval and reasoning tasks beyond public-domain capabilities.
TL;DR
The industry has a blind spot: we are building RAG systems for enterprises using benchmarks designed for Wikipedia. EnterpriseRAG-Bench introduces a 500k-document synthetic corpus that brings "corporate realism"—Slack noise, Jira tickets, and cross-project jargon—to evaluation. The core finding? Conventional Vector Search struggles, and the future of enterprise RAG belongs to iterative, agentic discovery.
The "Wikipedia Fallacy" in Corporate RAG
Most RAG researchers rely on BEIR or HotpotQA. While excellent for general knowledge, these datasets don't reflect the chaos of a 500-person tech company. In a real enterprise:
- Context is Scattered: A decision might start in a Slack thread, get documented in Confluence, and result in a GitHub PR.
- Semantic Overlap is High: Every document mentions the same project codenames, making vector retrieval "blurry."
- Data is Messy: Versioning conflicts and misfiled docs are the norm, not the exception.
Methodology: Building a Virtual Corporation
The authors didn't just generate random text. They built a "Company Scaffolding" for a fictional firm, Redwood Inference.
The Scaffolding Engine
- Organizational Reality: A hierarchy of people, projects, and mission statements.
- Source Diversity: Data spans 9 types, weighted by realism (Slack/Gmail make up the majority).
- Intentional Noise: Near-duplicates with conflicting facts and "misfiled" documents test the system's ability to filter relevant signal from noise.
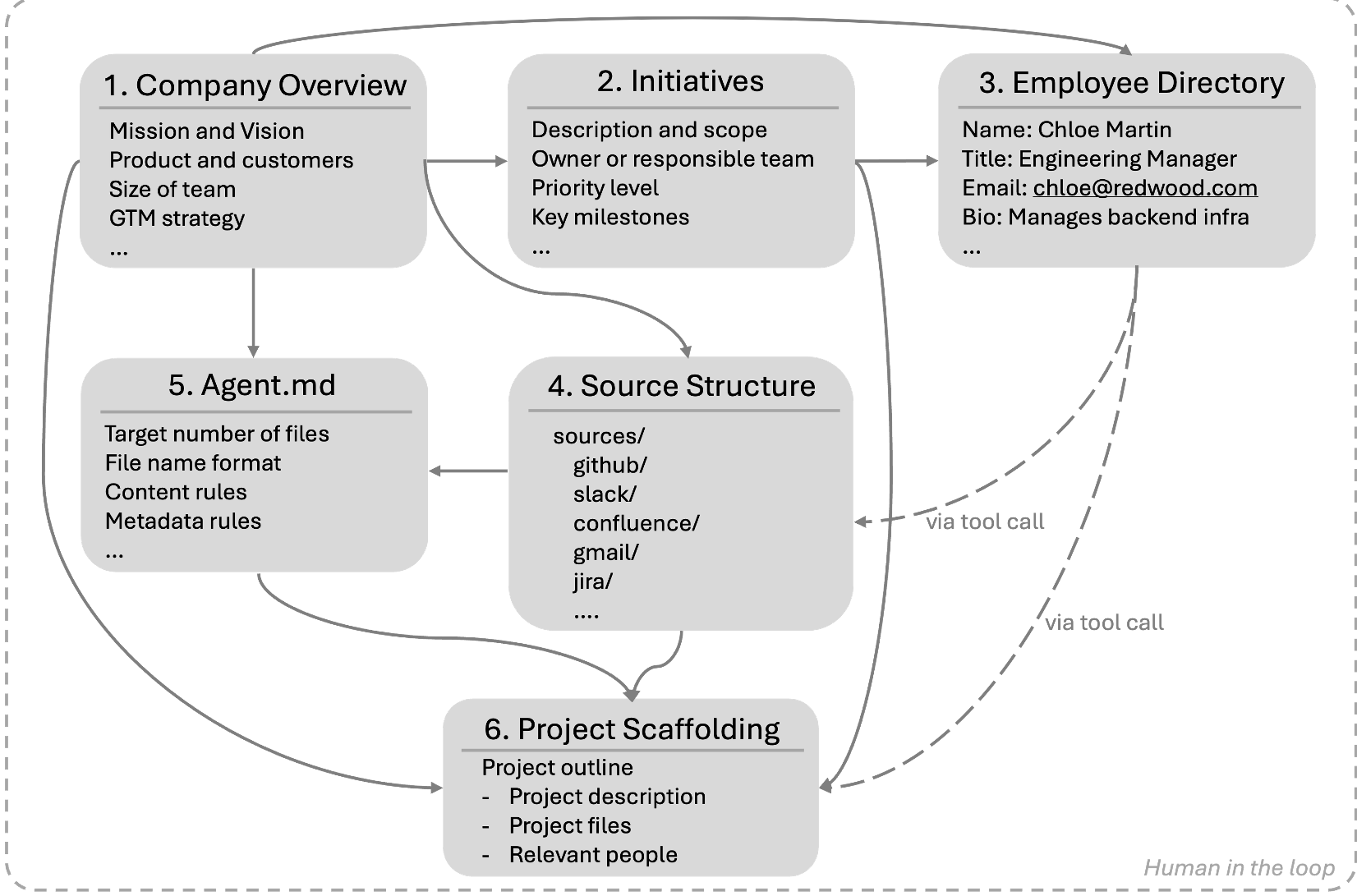 Figure 1: The generation framework uses top-level artifacts to ensure that 500,000 documents across 9 platforms share a single, coherent corporate reality.
Figure 1: The generation framework uses top-level artifacts to ensure that 500,000 documents across 9 platforms share a single, coherent corporate reality.
The Experiment: Vector vs. BM25 vs. Bash Agent
The results from the baseline evaluation were surprising even to the researchers.
- The Vector Search Struggle: Vector search, the industry favorite, underperformed significantly. This is likely because embedding models are trained on public data and lack the "internal weights" for project-specific jargon (e.g., "Project Icarus").
- The Power of the Agent: The "Bash Agent"—an LLM equipped with
grep,find, andls—excelled at Completeness. By iteratively exploring the directory structure, it found related documents that static retrievers missed.
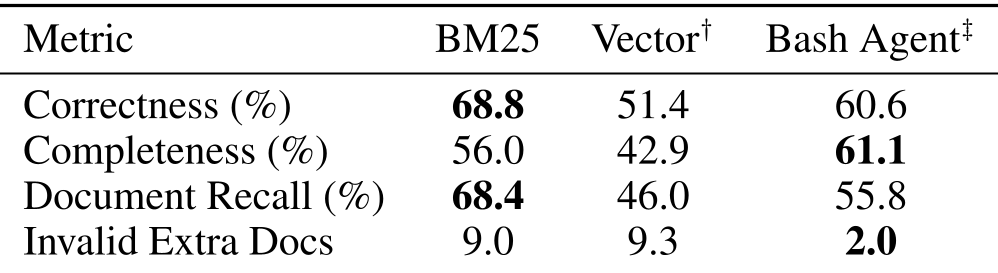 Table 1: Baseline system performance across Correctness, Completeness, and Recall.
Table 1: Baseline system performance across Correctness, Completeness, and Recall.
Why Scale Changes Everything
As the corpus grows from 5k to 500k documents, the "Local Density" (similarity between unrelated docs) increases. This means that at enterprise scale, your retriever's "Top 10" is increasingly likely to be filled with plausible-looking distractors rather than the gold evidence.
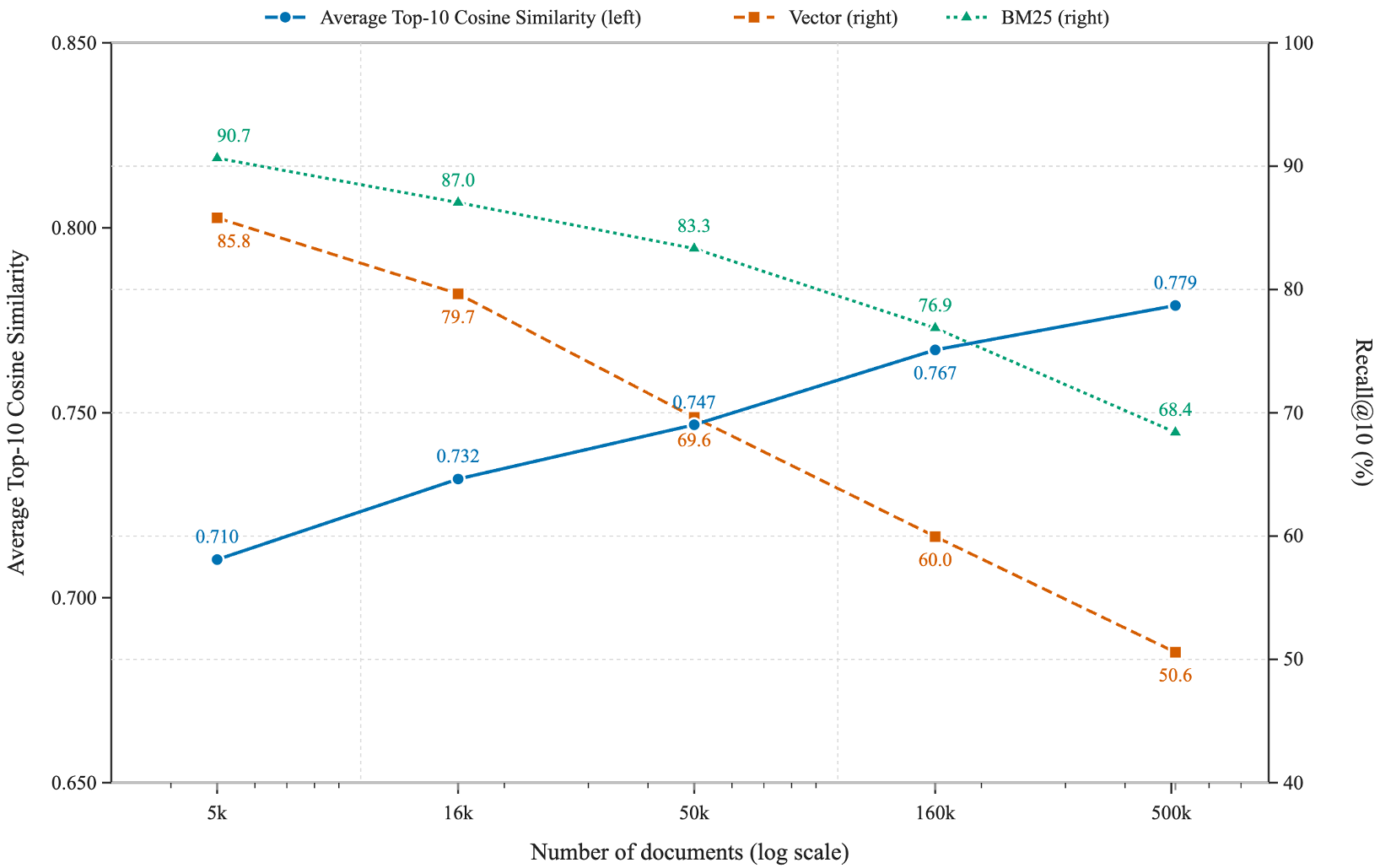 Figure 2: As document volume increases, Recall@10 drops sharply because the semantic neighborhood becomes too crowded.
Figure 2: As document volume increases, Recall@10 drops sharply because the semantic neighborhood becomes too crowded.
Critical Insight: Correction-Aware Evaluation
One of the most innovative parts of this paper is the Consensus-Based Correction. Recognizing that no 500k-doc dataset is perfect, the harness allows systems to "argue" for new gold documents. If a system finds a relevant document not in the original gold set, a panel of LLM judges evaluates its necessity and updates the benchmark dynamically.
Conclusion: Toward Agentic Knowledge Discovery
The take-home message is clear: RAG is no longer just a retrieval task; it is an exploration task. For high-stakes enterprise applications, we need to move away from "one-shot" vector lookups and toward agents that can reason about file hierarchies, reconcile conflicting updates across platforms, and understand the deep organizational context that links a Slack joke to a critical Jira ticket.
Check out the leaderboard and generate your own corporate bench at: https://github.com/onyx-dot-app/EnterpriseRAG-Bench