本文提出了 Myriad,一种针对开放世界场景的自回归扩散模型。该方法将未来场景演化的预测建模为稀疏点轨迹(Sparse Point Trajectories)的逐步连接,在无需渲染高成本视频像素的情况下,实现了极速的多样化未来预测。
TL;DR
传统的视频生成模型在预测未来时总在忙着“画图”,而忽视了“运动”本身。Myriad 另辟蹊径,抛弃了昂贵的像素渲染,通过自回归扩散模型预测稀疏点轨迹。它不仅在速度上快了 3000 倍,更能在同等算力下探索数千个可能的未来分支,让 AI 像人类一样通过“脑补”轨迹来理解物理世界的因果。
背景定位:世界模型的“视觉税”难题
当下的生成式人工智能(如 Sora 或 Gen-2)在生成连贯视频方面令人惊叹,但在作为“世界模型”服务于具身智能或决策规划时,它们存在一个致命弱点:视觉税 (Visual Tax)。
简单来说,如果你只想知道踢一脚球后球会滚向哪里,你并不需要实时渲染出球上的纹理、草地的阴影或观众的脸。但现有的模型会将 90% 的参数和计算量浪费在这些与动力学无关的表观细节上。这导致它们在需要进行快速假设验证(Counterfactual Reasoning)时显得笨重不堪。
痛点深挖:为什么“一步到位”和“像素密集”行不通?
- 密集的负担:视频模型预测整个潜在空间,导致采样分支(Branching)极其昂贵。
- 长程推断的崩溃:许多模型尝试“一跳”预测未来几秒的结局(One-shot),但在现实世界的动态交互链中,微小的扰动会迅速放大,单次跳跃无法捕获复杂的交互序列。
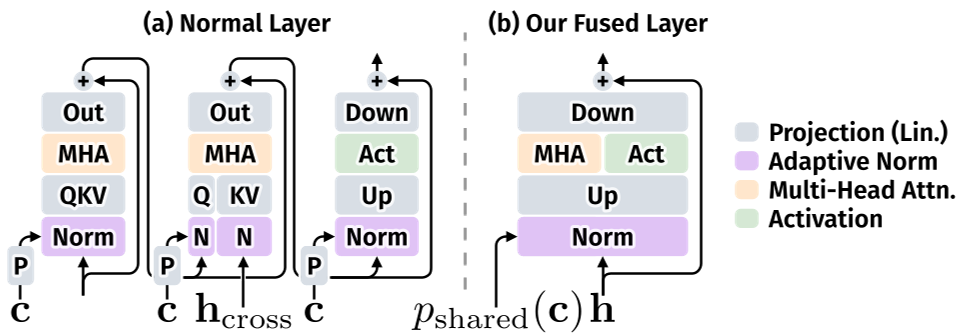 图 1:Myriad 的运动令牌构造。通过融合初始位置的“外观”和当前位置的“语境”,模型学会了理解“什么在动”以及“它在哪里动”。
图 1:Myriad 的运动令牌构造。通过融合初始位置的“外观”和当前位置的“语境”,模型学会了理解“什么在动”以及“它在哪里动”。
Methodology:动力学中心的稀疏模拟
Myriad 的核心逻辑是将动态场景简化为一组稀疏点。它的架构设计堪称精妙:
1. 运动令牌 (Motion Tokens) 的多维融合
模型不是孤立地看点,而是为每个点构建了包含“Who, What, Where”信息的 Token:
- What (外观):从初始帧的原始坐标提取特征。
- Where (局部上下文):从当前轨迹点位置提取特征。
- Who (身份):使用随机单位向量作为轨迹 ID,实现对任意数量轨迹的零样本外推。
2. 快速推理块 (Fast Reasoning Blocks)
为了追求极致的 Rollout 吞吐量,作者改进了 Transformer 层。通过融合自注意力和交叉注意力,减少了 Kernel 启动次数,使推理速度提升了 2 倍以上。
3. 流匹配 (Flow Matching) 后的重尾分布处理
现实世界的运动规律通常呈重尾分布(即大部分时间不动,一旦动起来可能产生剧烈位移)。Myriad 引入了一个多尺度缩放级联 (Scale Cascade),通过对输入进行 tanh 饱和处理,确保模型既能捕捉极其微小的震动,也能稳定预测巨大的运动跳跃。
实验与结果:速度与精度的双重碾压
作者在自建的 OWM (Open-World Motion) 基准测试上进行了严苛的对比。
性能对比
在同等 5 分钟的计算限制下,Myriad 由于每分钟能生成 2200 个样本(远超 SVD 的 0.7 个),它能覆盖更多的概率空间。
- ADE (平均位移误差):在 OWM 上,Myriad 的误差仅为 SVD 的 1/10 左右。
- 物理决策 (Planning):在复杂的台球规划实验中,Myriad 展现了惊人的能力。它能通过快速模拟数千种击球力度和角度,选出最优路径,准确率达 78%,而基于视频生成的基线仅为 16%。
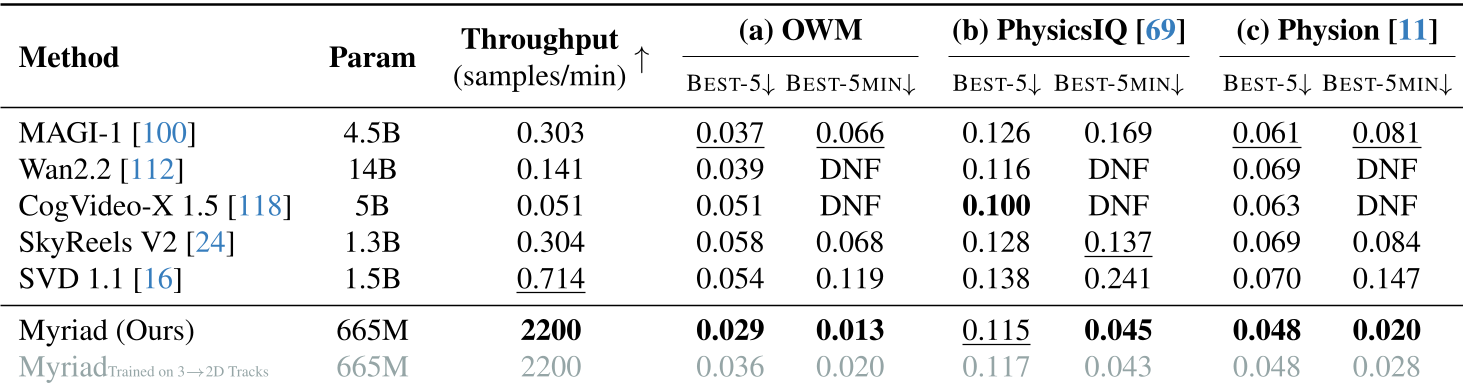 表 1:在各个物理诊断集中,Myriad 凭借极高的吞吐量在 Best-5min 指标上形成了断层领先。
表 1:在各个物理诊断集中,Myriad 凭借极高的吞吐量在 Best-5min 指标上形成了断层领先。
深度洞察:预见的本质是抽象
Myriad 的成功揭示了一个深刻的道理:智能的本质是抽象 (Abstraction)。人类在思考未来时,大脑中运行的不是 4K 视频,而是抽象的对象轨迹和因果联系。
局限性与挑战
尽管表现卓越,Myriad 目前主要假设相机静止(Static Camera)。虽然作者尝试通过 3D 到 2D 的投影来补偿相机运动,但在剧烈抖动的真实现场视频中,如何完美解耦“物体动”与“相机动”仍是一个开放性课题。
总结
Myriad 为世界模型的构建提供了一条高效、优雅的新路径。它不画图,只看路。通过对稀疏轨迹的自回归扩散,它让 AI 能够在大规模开放世界中快速迭代成千上万种假设。对于未来的具身智能和高速决策系统,这种“动力学优先”的思想或许比单纯的视频生成更具启发性。