LG AI Research introduces EXAONE 4.5, a 33B parameter open-weight Vision-Language Model (VLM) that integrates a custom 1.2B vision encoder with the EXAONE 4.0 language backbone. It achieves state-of-the-art performance in industrial document understanding and Korean contextual reasoning while maintaining highly competitive general multimodal capabilities.
TL;DR
LG AI Research has released EXAONE 4.5, their first open-weight Vision-Language Model. Moving beyond simple image captioning, this 33B parameter powerhouse is purpose-built for "Industrial Intelligence"—think parsing complex technical blueprints, performing quality control, and reasoning through multi-page documents. It supports a massive 256K context window and six languages, setting a new bar for open-weight models in specialized domains.
Problem: The Resolution Bottleneck and Domain Gap
Most current Vision-Language Models (VLMs) suffer from two fatal flaws when applied to industrial settings:
- Visual Information Loss: To save compute, models often use small vision encoders (e.g., CLIP-VIT) and aggressively truncate image tokens. This "buries" small text in documents or fine details in engineering diagrams.
- Generalization vs. Specialization: General VLMs are trained on web-scraped cats and landscapes but fail when asked to interpret an HTML table, a mathematical graph, or a Korean cultural nuance.
EXAONE 4.5 addresses these by scaling the vision component and revolutionizing the data curriculum.
Methodology: Engineering for "Eyes" and "Logic"
1. Scaling the Vision Encoder
Instead of off-the-shelf encoders, LG built a 1.2B parameter vision encoder from scratch.
- GQA (Grouped Query Attention): Typically used in LLM decoders, LG applied GQA to the vision encoder to handle high-resolution inputs without the quadratic memory explosion.
- 2D RoPE: To respect the spatial nature of images (where "up" and "down" matter as much as "left" and "right"), they implemented 2D Rotary Positional Embeddings.
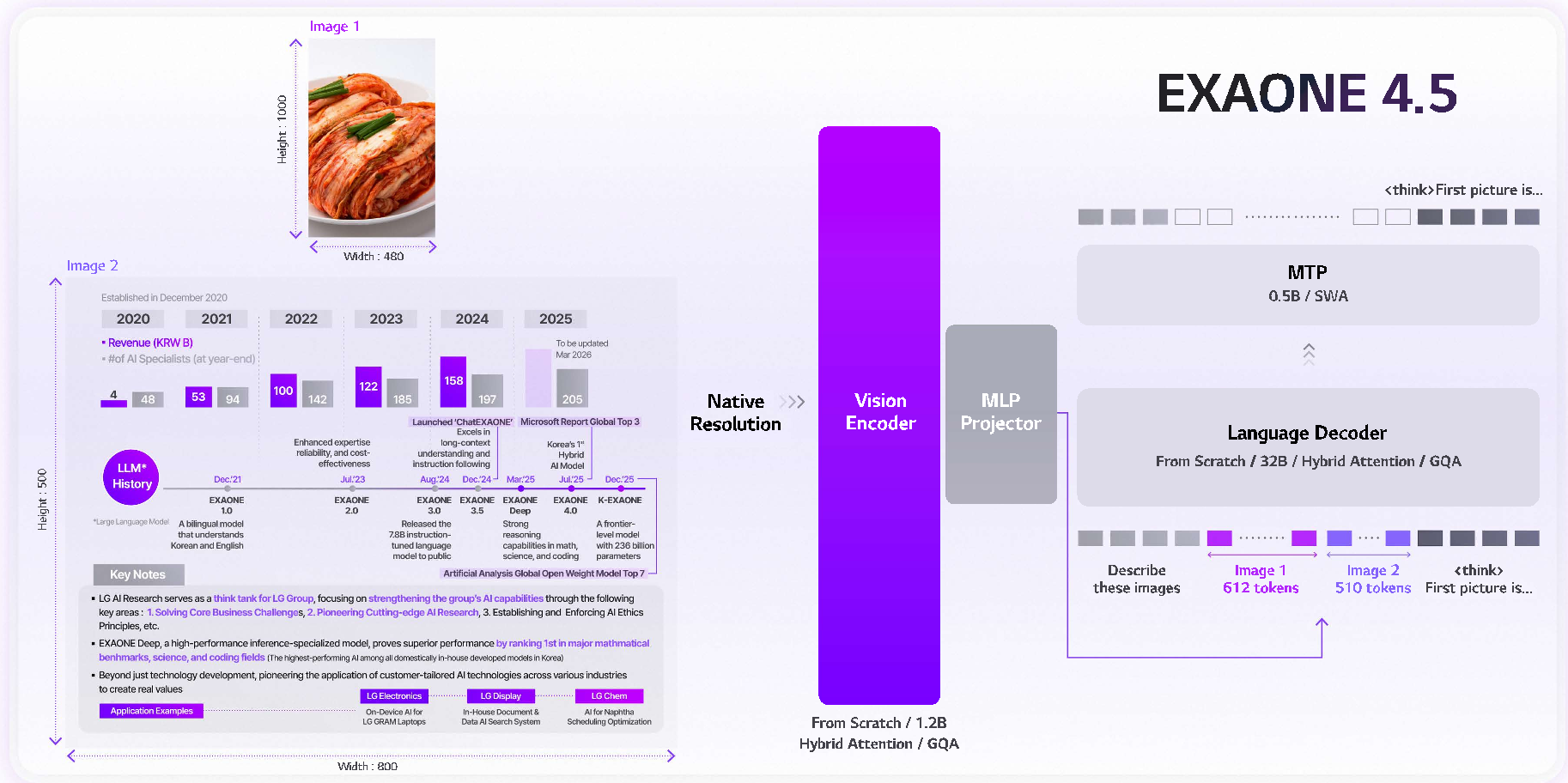
2. The 256K Context Mastery
Handling long documents requires more than just a large window; it requires stability. EXAONE 4.5 integrates context extension directly into the Supervised Fine-Tuning (SFT) phase rather than as a post-hoc patch. This ensures that the model can maintain cross-modal alignment even when the information it needs to link is tens of thousands of tokens apart.
3. Data Curriculum: Document-Centric Alignment
The pre-training followed a two-stage pipeline:
- Stage 1: General image-text alignment.
- Stage 2: Transition to "High-Density" data—OCR, STEM reasoning, and structured document parsing (converting charts to Markdown/JSON).
Experiments: Punching Above Its Weight Class
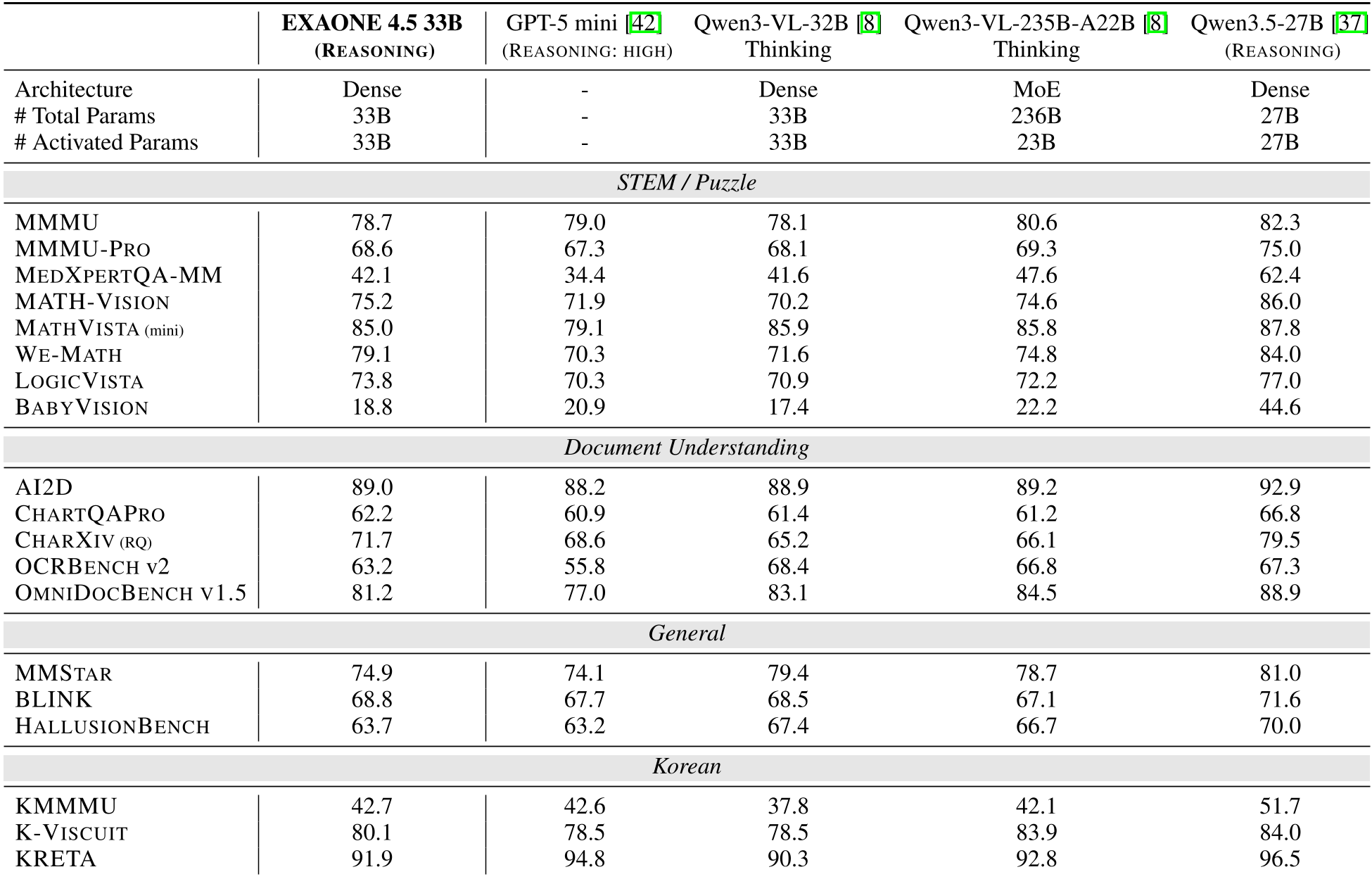
The results prove that "bigger is not always better" if your data is cleaner. Despite having only 33B parameters, EXAONE 4.5 outperformed the 235B Qwen3-VL on several high-complexity benchmarks.
Key Performance Metrics:
- Mathematical Reasoning (MATH-VISION): 75.2 (Beating Qwen3-VL-235B at 74.6).
- Document Parsing (CHARXIV): 71.7 (Beating GPT-5 mini at 68.6).
- Coding (LiveCodeBench): 81.4 (Ranking #1 among compared baselines).
Deep Insight: Why This Matters for the Industry
The true value of EXAONE 4.5 isn't just in its benchmark scores, but in its Industrial Inductive Bias. By training the model to output structured data (HTML/JSON) from images, LG is positioning this model as a "middleware" for Agentic AI.
Imagine an AI agent in a factory: it doesn't just "see" a diagram; it converts that diagram into a logic graph, references a 200-page manual (via the 256K context), and identifies a compliance error. This is the bridge toward Vision-Language-Action (VLA) models that can eventually control physical robots.
Conclusion & Limitations
EXAONE 4.5 is a formidable addition to the open-weight ecosystem, particularly for users needing robust performance in document AI and multilingual (specifically Korean) reasoning.
Limitations: Like all LLMs, it remains susceptible to hallucinations and carries biases present in its training data. Its 33B scale, while efficient, still requires significant GPU resources for 256K token inference.
Future Outlook: By releasing the weights, LG AI Research is inviting the community to extend this "industrial backbone" into even narrower domains like legal tech, medical diagnostics, and autonomous manufacturing.