本文提出了 HeRL,这是一个利用事后经验(Hindsight Experience)指导的大语言模型强化学习框架。通过将未达标的细则(Rubrics)转化为上下文指南,HeRL 在指令遵循和医疗问答等开放式推理任务中显著超越了 RLVR 等 SOTA 基线。
TL;DR
在强化学习(RL)的训练中,模型往往像是在黑暗中摸索。本文提出的 HeRL (Hindsight experience guided Reinforcement Learning) 框架,通过让 LLM 阅读自己失败的原因(未达标的 Rubrics),并以此作为指南进行二次尝试,从而将“盲目试错”转变为“定向改进”。实验显示,HeRL 在指令遵循和医疗推理等任务上全面超越了传统的 RLVR 和 DPO 方法。
核心洞察:为什么要“事后反馈”?
在强化学习中,一个核心痛点是 Exploration Efficiency(探索效率)。
- 传统做法:模型生成 8 个回复,如果都错了,梯度更新就会变得非常混乱,模型不知道“正确”的方向在哪里。
- HeRL 的直觉:利用 LLM 的 In-context Learning (ICL) 能力。既然我们有评价细则(Rubrics),为什么不直接告诉模型:“你这遍写得不错,但少了‘synthesizer’这个关键词,请修改一下”?
这种“事后诸葛亮”式的反馈,能直接把模型从其当前的分布推向高奖励区域。
HeRL 框架详解
HeRL 的流程可以分为三个阶段:
- 初始采样与评价:模型生成多条候选路径,由“LLM-as-a-Judge”根据预设的 Checklist(Rubrics)给出评分和具体的未达标原因。
- 事后经验引导探索:选取分数较高但未完美的样本,将“未达标原因”作为 Prompt 再次喂给模型。
- 这里引入了 Zone of Proximal Development (ZPD) 理论:只修改那些“跳一跳够得着”的失败样本(High-reward failures),因为它们离正确答案最近,学习效率最高。
- 强化学习训练:将原始样本和改进后的样本同时纳入训练。
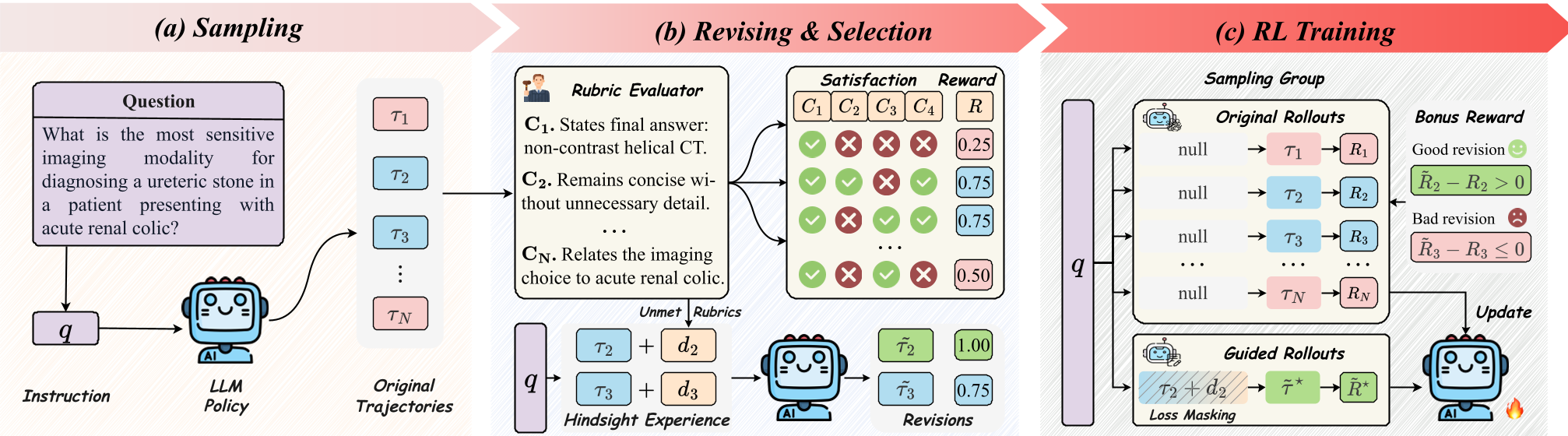 图 1:HeRL 总体框架,展示了从采样、修订到 RL 优化的完整闭环。
图 1:HeRL 总体框架,展示了从采样、修订到 RL 优化的完整闭环。
此外,HeRL 还引入了两个关键的技术细节:
- Bonus Reward:如果一个失败的回复能通过引导被修正,那么原始回复也会获得额外奖励,因为它具有“改进潜力”。
- Policy Shaping:通过正则化的重要性采样,增强模型从低概率但高价值的改进动作中学习的稳定性。
实验战绩
HeRL 在多个架构(Qwen, Llama)和多个尺度上均取得了 SOTA。
1. 性能全线飘红
在指令遵循(IFEval)、创意写作(WritingBench)和医疗问答(HealthBench)中,HeRL 均显著优于传统的 RLVR(Verifiable Rewards)。
 表 1:HeRL 在不同模型家族上的性能对比,展示了其强大的跨领域泛化能力。
表 1:HeRL 在不同模型家族上的性能对比,展示了其强大的跨领域泛化能力。
2. 训练动力学:防止“熵崩”
传统 RL 往往会在训练早期出现 Entropy Collapse(熵崩),即模型迅速收敛到某一种套路中,停止探索。而图 5 显示,HeRL 在保持更高采样熵的同时,获得了更高的验证集奖励,这意味着它在整个训练过程中都在持续产出高质量且多样化的样本。
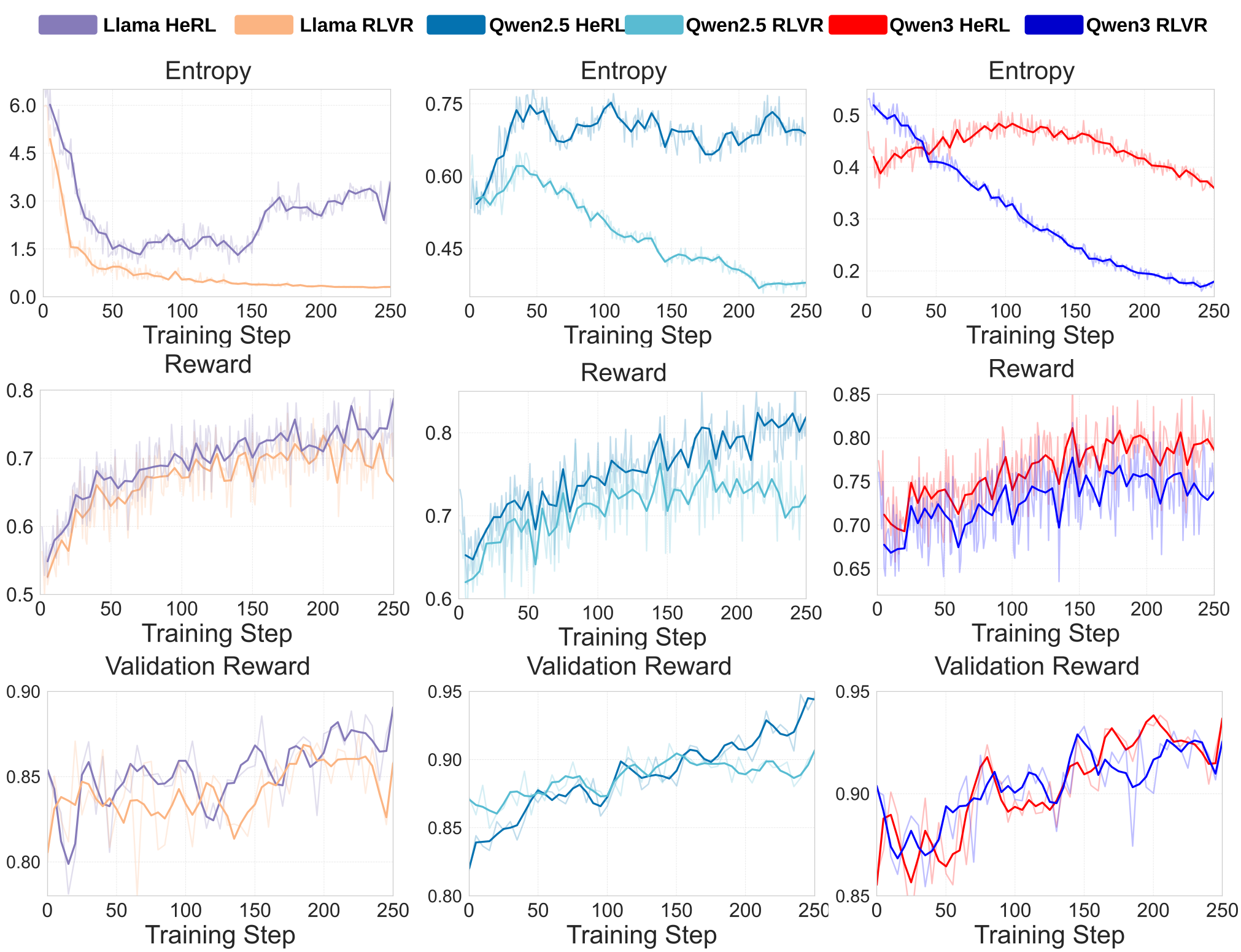 图 2:HeRL 与 RLVR 的训练动态对比,HeRL 展现了更好的训练稳定性。
图 2:HeRL 与 RLVR 的训练动态对比,HeRL 展现了更好的训练稳定性。
深度思考:能力的内化与外化
HeRL 最令人兴奋的发现之一是:训练期间的修正能力可以迁移到推理阶段。 由于模型在训练时反复练习“根据反馈修改回复”,它在测试时即使没有外界明确反馈,也能表现出更强的自我修正潜力(Experience guided self-improvement)。这为未来构建“自我进化”的推理模型(如 o1 类模型)提供了重要的理论与实践支撑。
总结与价值
HeRL 证明了:Experience is indeed the best teacher。通过将结构化的语言反馈(Rubrics)转化为探索动力,我们不再需要枯燥的数百万次随机采样,而是可以通过“教学”的方式,更优雅地对齐 LLM 的行为。
局限性:目前 HeRL 仍然依赖高质量的初始 Rubrics 选定。未来的方向可能是让模型自主生成并演进这些评价细则(Adaptive Rubrics)。