本文提出了一种名为 Quantum Oracle Sketching 的量子数据处理框架,证明了小型量子计算机(多项式对数级量子比特)在处理大规模经典数据时的指数级空间优势。该工作在 sentiment analysis 和 single-cell RNA sequencing 等实际任务中,实现了比经典算法低 4-6 个数量级的内存需求。
TL;DR
处理海量数据时,经典计算正面临严峻的“内存墙”。加州理工与 Google Quantum AI 团队发表的最新论文证明:使用极少量的量子比特(多项式对数级),就能在分类、降维等经典机器学习任务中战胜内存空间大指数阶倍数的经典机器。核心武器是名为 Quantum Oracle Sketching 的新算法,它让量子机器能以“阅后即焚”的流式方式,直接从噪声数据中提取关键信息。
1. 痛点:被忽视的“数据加载器”成本
长期以来,量子机器学习(QML)被寄予厚望,但有一个巨大的尴尬:大多数 QML 算法假设数据已经存在于量子随机存取存储器(QRAM)中。
- 现状:构建一个纠错的 QRAM 往往需要巨大的物理开销,甚至比直接用经典计算机解决问题还贵。
- 陷阱:当你把数据从硬盘搬到量子寄存器的成本算进去时,很多所谓的“量子加速”其实已经消失了。
- 退化:如果没有大数据存储,经典算法(如 Streaming PCA)为了省内存必须牺牲精度。
2. 核心机制:Quantum Oracle Sketching (QOS)
作者提出了一种“量子草图”的思想。它不需要存储整个数据集,而是每来一个经典样本 ,就对量子态施加一个微小的旋转 。
为什么这不会因为随机性而导致去相干(Decoherence)? 通常的随机哈密顿量模拟(如 qDrift)在 个样本后误差会按 增长。但作者发现,对于对角基操作,这些误差在互不干扰的子空间内累积。通过将旋转设计为正交基上的贡献,误差缩减到了 ,这正是量子优势存活的生命线。
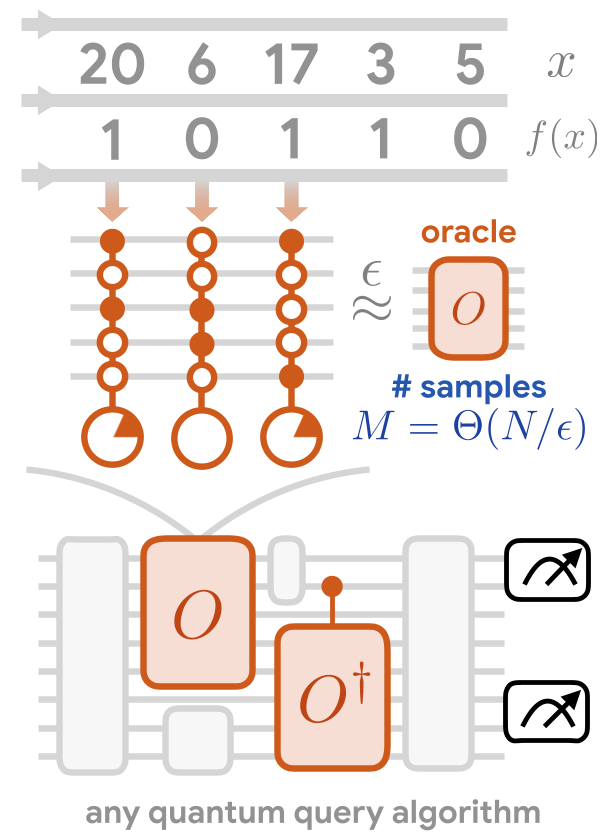 图 1: 通过随机样本增量式构建量子 Oracle 的过程及其误差收敛曲线。
图 1: 通过随机样本增量式构建量子 Oracle 的过程及其误差收敛曲线。
3. 实验验证:真实世界的“降维打击”
研究团队在 单细胞 RNA 测序(scRNA-seq) 和 IMDb 电影评论情感分析 两个真实任务上进行了基准测试。结果令人震撼:
- 内存需求差距:为了达到同样的 Explained Variance(降维质量),经典流式算法需要存储整个特征空间,而 QOS 算法通过 Qubit 叠加态实现的有效维度坍缩,使内存消耗降低了 4 到 6 个数量级。
- 逻辑比特数:所有模拟仅需不到 60 个逻辑量子比特。这意味着,我们不需要几百万个量子比特,就能在特定的大数据挖掘任务中展现出超越全球最强超级计算机内存极限的能力。
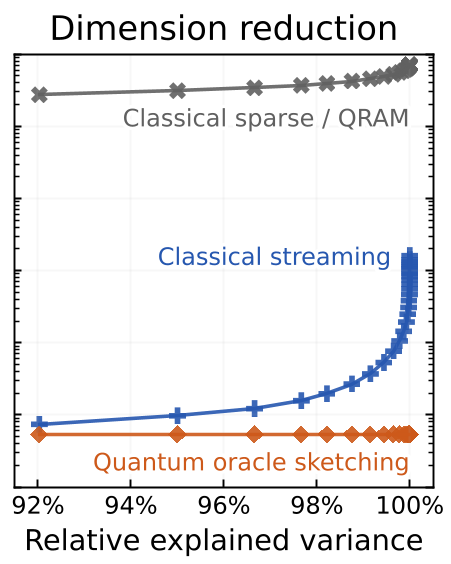 图 2:在真实数据集上,量子方法(橙色线)在机器规模与性能权衡中表现出明显的指数级优势。
图 2:在真实数据集上,量子方法(橙色线)在机器规模与性能权衡中表现出明显的指数级优势。
4. 更深层的洞察:信息论的胜利
这项研究的精妙之处在于它不仅提出了算法,还给出了 Classical Hardness(经典硬度) 的严格证明。
- 不可模拟性:作者证明了,除非经典机器的内存大小 与样本数 的乘积满足 (其中 是经典查询复杂度),否则永远无法达到量子机器的预测精度。
- 动态数据优势:在数据分布随时间漂移(Dynamic Setting)的场景下,拥有极小内存的经典机器会由于无法追踪变化而彻底失效,而量子机器凭借其在 Hilbert Space 中的高维表征能力,能以极高样本效率完成任务。
5. 总结与展望
这项研究标志着 QML 进入了“端到端量子优势”时代。它不再停留于数学玩具模型,而是直接挑战经典计算在处理海量、高维、流式数据时的物理极限。
局限性:尽管空间复杂度有指数优势,但目前量子 Oracle Sketching 仍然面临较大的时间开销(需要接收足够数量的样本),如何通过并行化(Parallelization)缩短运行时间是下一步的研究重点。
正如 Bell 不等式测试了量子非局域性,这一框架也成为了在复杂度前沿测试量子力学正确性的试金石。未来的大规模个性化推荐、基因组学分析,或许真的只需要一台几十个逻辑比特的量子终端。