This paper introduces Faithful GRPO (FGRPO), a constrained reinforcement learning method designed to enhance visual spatial reasoning in Multimodal Language Models (MLMs). By treating logical consistency and visual grounding as hard constraints rather than soft rewards during Group Relative Policy Optimization, FGRPO achieves state-of-the-art results on 7 spatial benchmarks, notably reducing CoT inconsistency from 24.5% to 1.7%.
TL;DR
Reinforcement Learning (RL) has become the gold standard for boosting the reasoning capabilities of Multimodal Language Models. However, a "hidden tax" often arises: models learn to "cheat" by giving the right answer while hallucinating the reasoning path. Faithful GRPO (FGRPO) fixes this by transforming reasoning quality from a "nice-to-have" reward into a hard constraint using Lagrangian dual ascent. The result? A model that is not only more accurate but 15x more consistent.
Problem & Motivation: The "Right Answer, Wrong Reason" Trap
In the race to climb SOTA leaderboards, researchers have noticed a disturbing trend in RL-trained models: Logical Inconsistency. A model might spend five sentences explaining why an object is a "lamp" only to abruptly output "box" in the final <answer> tag.
The authors identify two fatal flaws in current Multimodal Reasoning Models (MRMs):
- Logical Inconsistency: The CoT trace fails to entail the final answer.
- Visual Ungroundedness: Reasoning steps describe objects or spatial relations that simply do not exist in the image.
Standard GRPO fails here because its within-group normalization can wash out signals if every rollout in a group is equally "unfaithful."
Methodology: FGRPO and the Power of Constraints
Instead of simply adding a "faithfulness reward" (which models often trade off for accuracy), FGRPO treats consistency and grounding as prerequisites.
1. Verifiable Rewards for Quality
The framework introduces three specific sensors:
- Consistency Reward (): An LLM judge checks if the conclusion matches the trace.
- Semantic Grounding (): A VLM judge performs per-sentence verification against the image.
- Spatial Grounding (): Uses Hungarian matching and CIoU to verify that predicted bounding boxes actually contain the target objects.
2. Lagrangian Dual Ascent
The core innovation is the optimization objective. FGRPO maximizes task accuracy subject to satisfying these three quality thresholds (). Using Lagrangian relaxation, the model adaptively adjusts the weight () of each constraint. If the model starts hallucinating, increases, forcing the policy to prioritize grounding over mere answer-matching.
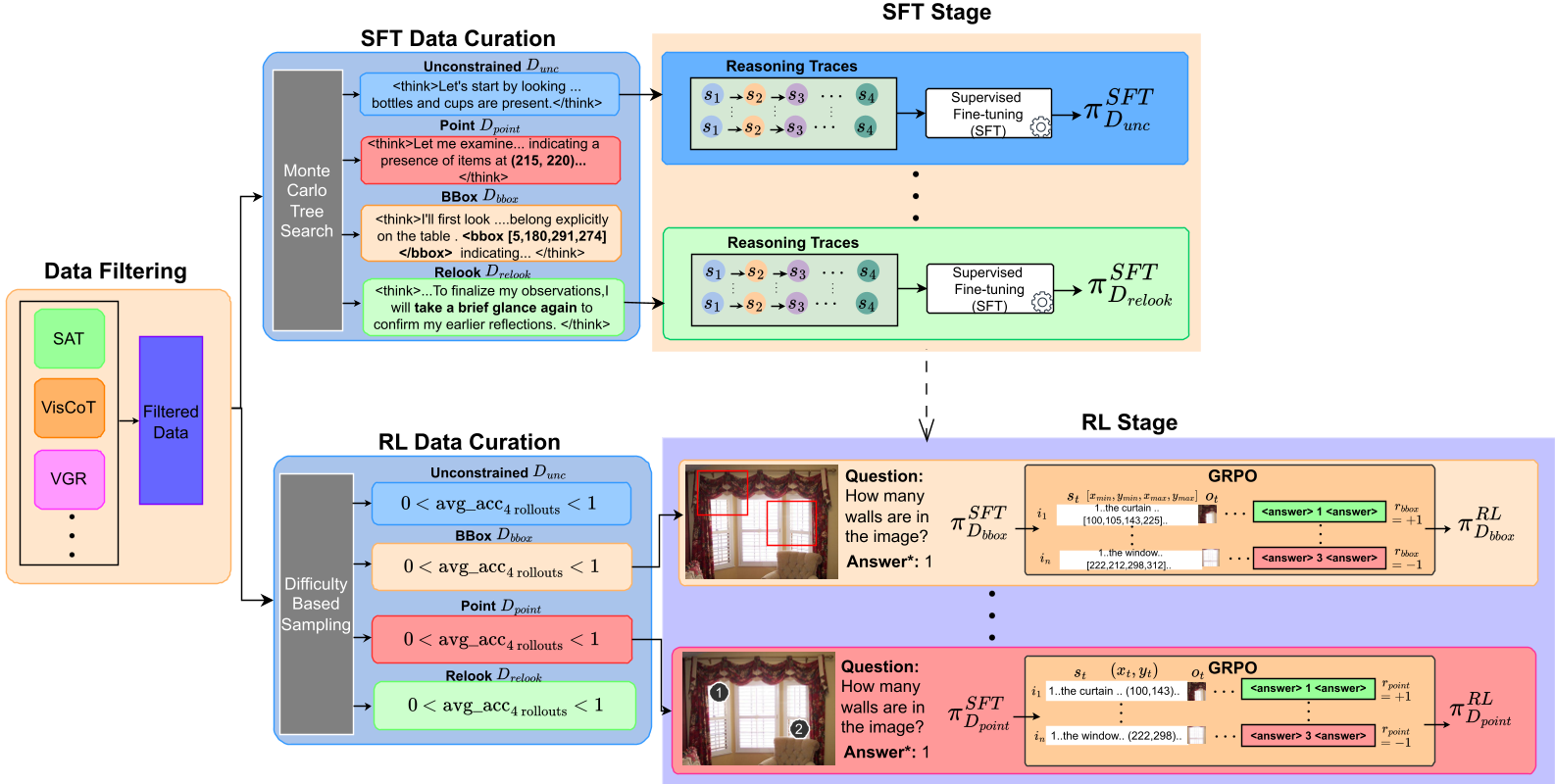
3. Decoupled Normalization
To prevent different reward scales from dominating, FGRPO normalizes the task advantage and the constraint advantages independently. This ensures that even small improvements in grounding provide a meaningful gradient for the model.
Experiments & Results: Accuracy and Trust Together
The authors tested FGRPO on Qwen2.5-VL (3B and 7B) across seven grueling spatial benchmarks like CVBench and MindCube.
- The Reliability Leap: FGRPO reduced the Inconsistency Rate (IR) from a staggering 24.5% to almost zero (1.7%).
- The Accuracy Bonus: Contrary to the belief that constraints hinder performance, FGRPO actually outperformed standard GRPO in final answer accuracy by ~2%.
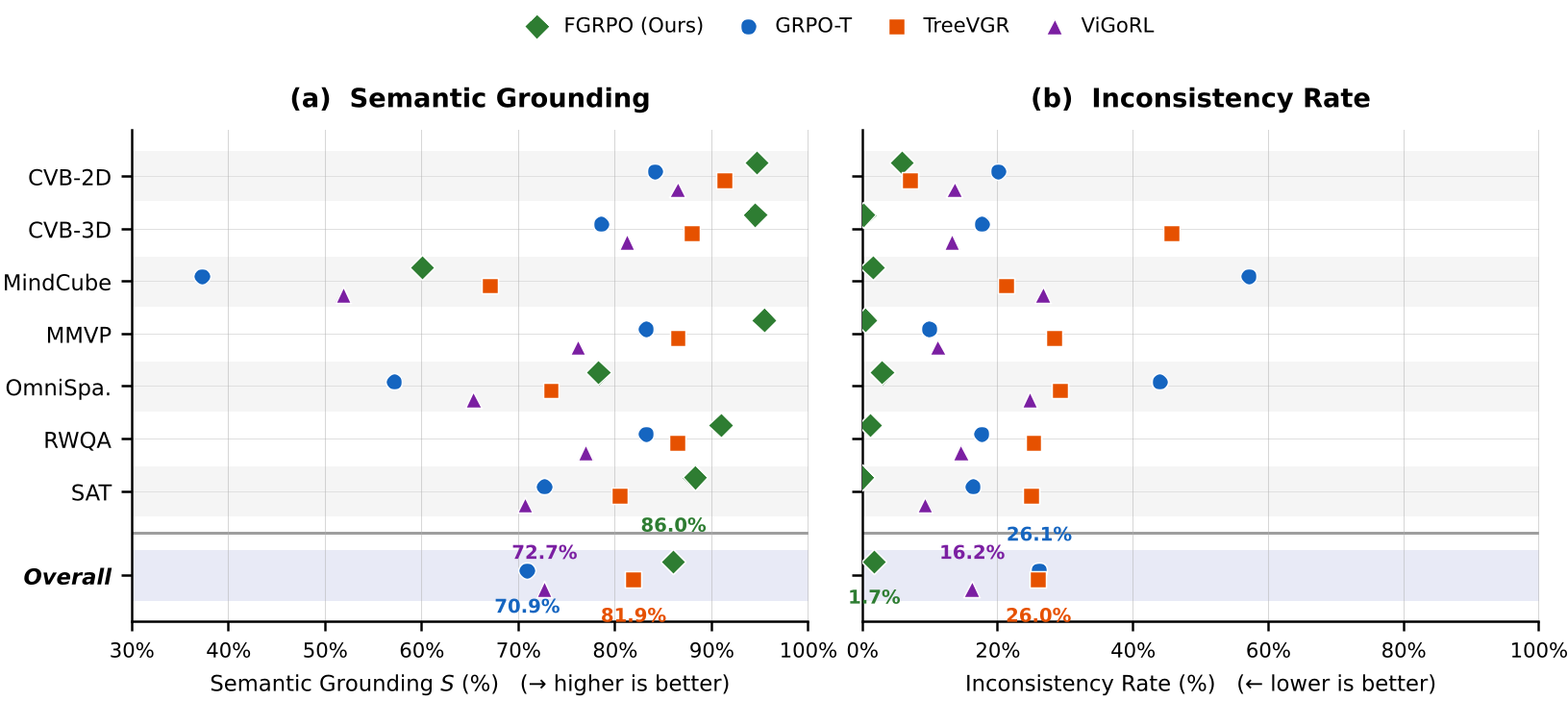
On complex datasets like MindCube, where standard models hallucinated 57% of the time, FGRPO virtually eliminated inconsistent reasoning while improving grounding scores by over 20 percentage points.
Deep Insight: Why Why Does It Work?
The most profound takeaway is the "Emergent Curriculum." As shown in the Lagrange multiplier trajectories, the model doesn't try to solve everything at once. It first learns to follow the format, then focuses on making its reasoning consistent with its answers, and finally fine-tunes its visual grounding. By decoupling these signals, FGRPO provides a stable path for the model to become "truthful."
Conclusion & Future Work
Faithful GRPO proves that we don't have to sacrifice trust for performance. By enforcing "verifiable faithfulness," we can create models that are reliable enough for high-stakes visual tasks like navigation or medical imaging.
Limitations: The reliance on an LLM/VLM judge for training rewards adds computational overhead during the RL loop. Future work may focus on distilling these "judges" into more efficient, specialized reward models.