本文提出了 Faithful GRPO (FGRPO),一种针对多模态语言模型(MLM)的约束策略优化方法。通过将逻辑一致性和视觉接地(Visual Grounding)作为硬约束引入 GRPO 框架,显著提升了模型在视觉空间推理任务中的推理质量与答案准确度。
TL;DR
在强化学习(RL)的加持下,大模型的“刷榜”能力屡创新高,但在多模态推理领域,我们常发现模型虽然选对了答案,其推理过程(CoT)却是满嘴胡诌。本文提出的 Faithful GRPO (FGRPO) 首次通过拉格朗日约束优化的方式,在提升空间推理准确率的同时,几乎消灭了推理不一致现象,让模型真正做到“所答即所思”。
痛点深挖:正确的答案,荒谬的推理
在大模型推理从文本转向视觉空间(Visual Spatial Reasoning)时,研究者发现了一个尴尬的现象:模型学会了“作弊”。
即便使用了 DeepSeek-R1 验证奖励(RLVR)的范式,模型在处理复杂的空间关系(如:“灯在袜子的左边吗?”)时,生成的 CoT 往往表现出:
- 逻辑不一致 (Logical Inconsistency):推理了半天结论是 A,最后的
<answer>标签里却跳到了 B。 - 视觉不接地 (Visual Ungroundedness):CoT 中描述了图中根本没有的路径或物体(视觉幻觉)。
作者调研发现,现有的 SOTA 模型(如 ViGoRL, TreeVGR)均存在不同程度的此类问题。简单地将这些指标作为奖励项相加,往往会导致模型在多个目标间“拆东墙补西墙”,难以兼顾。
核心方法:FGRPO 的约束之道
FGRPO 的核心直觉是:逻辑一致性和视觉真实性不应该是加分项(Rewards),而应该是必须达标的门槛(Constraints)。
1. 验证信号的定义
- 一致性奖励 ():引入一个轻量级文本 LLM 作为 Judge,判断 CoT 轨迹是否能通过逻辑推导出最终答案。
- 语义接地奖励 ():利用 VLM 将 CoT 拆解为逐句 claim,验证每一句是否符合图像事实。
- 空间接地奖励 ():针对 Bounding Box 坐标,利用 Hungarian Matching 和 CIoU 计算预测框与真值的匹配度。
2. 拉格朗日对偶上升与解耦归一化
为了强有力地执行这些约束,作者抛弃了固定的权重,采用了拉格朗日松弛法: 拉格朗日乘子 会根据当前 Batch 的表现动态调整:如果模型开始产生幻觉(接地性下降), 会增大,迫使梯度向修复该约束的方向倾斜。
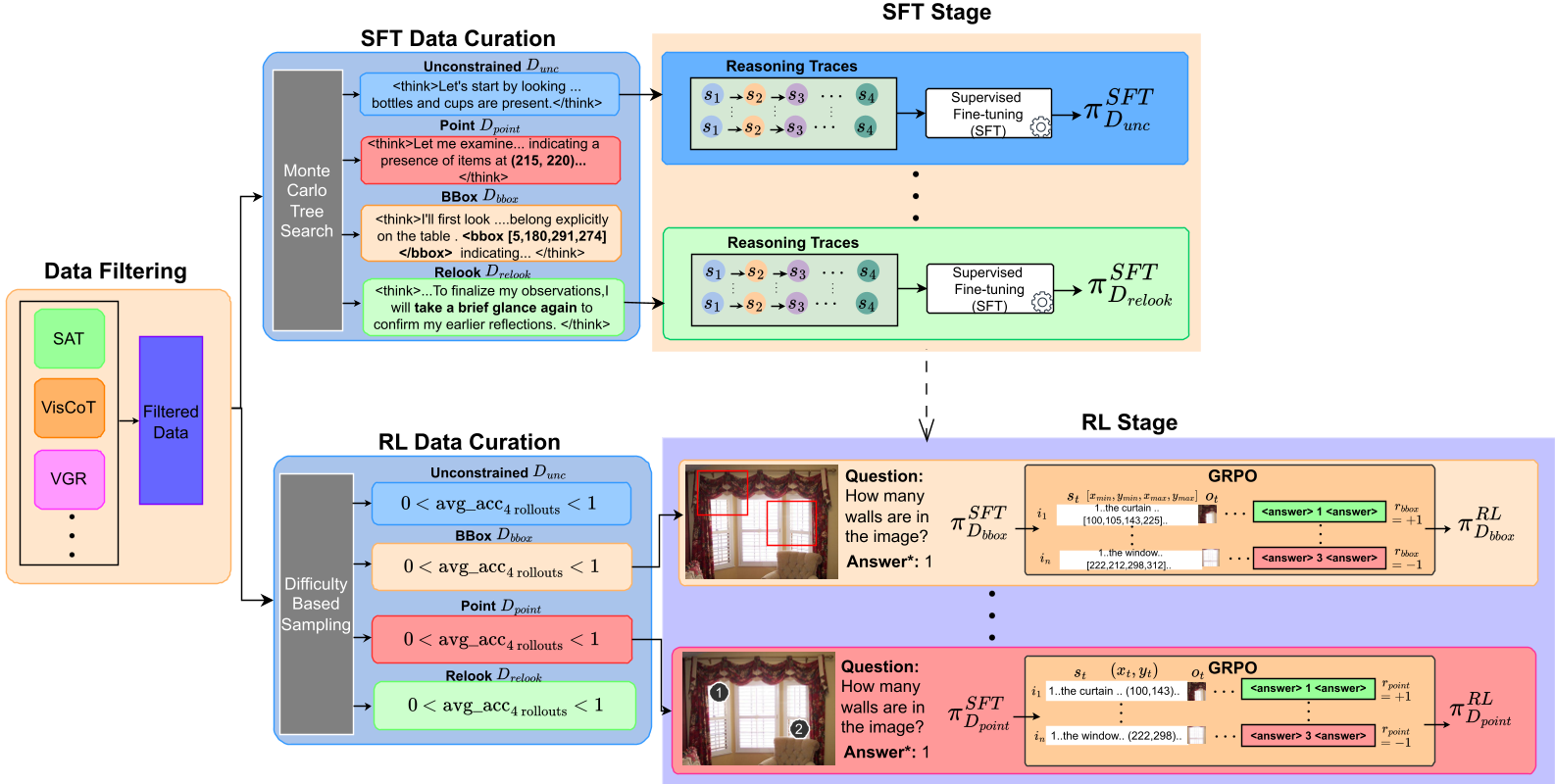
3. 解耦优势计算 (Decoupled Advantage)
这是 FGRPO 能够稳定训练的关键。在标准 GRPO 中,优势函数是在组内进行均值减法处理。如果某一约束在组内所有 rollout 中表现一致(例如全是 0),其梯度会消失。作者通过对任务奖励和各个约束奖励分别进行组内归一化,确保了每一个信号都能提供有效的梯度指导。
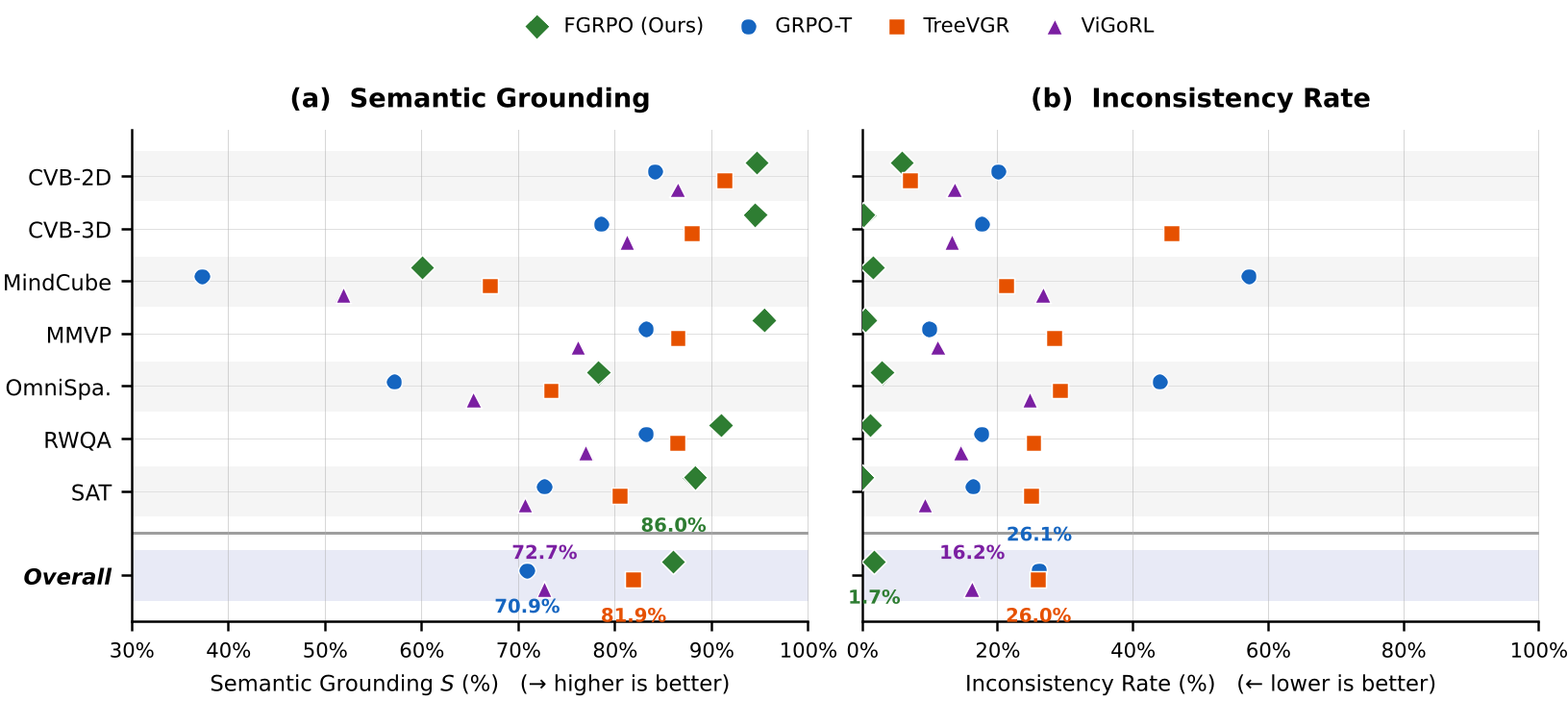
实验与结果:推理质量的质变
作者在 Qwen2.5-VL-7B 基础上进行的实验展示了惊人的提升:
- 推理不一致率 (Inconsistency Rate):从基础 GRPO 的 26.12% 降到了 1.73%,几乎消灭了逻辑跳跃。
- 空间推理准确率:在 MindCube 等极具挑战的数据集上,准确率反而提升了,证明了“正确的逻辑有助于正确的答案”。
在消融实验中,作者展示了 随着训练步数波动的曲线。可以看到,系统通过动态调整参数,实现了一种“自动驾驶”式的多目标优化,无需人工手动调权。
深度洞察:为什么这很重要?
FGRPO 的成功不仅在于刷高了分数,更在于它揭示了 MLM 训练中的一个本质问题:由于神经网络的黑盒特性,单纯的端到端结果监督(Outcome Supervision)会诱导模型通过统计偏差而非真正的推理来获取奖励。
通过将“推理过程的合规性”作为硬指标,FGRPO 为构建可解释、可信赖的多模态模型提供了一套标准化的 RL 方案。
局限性与展望
尽管表现强劲,FGRPO 目前依赖于较强的 Judge 模型(如 GPT-5 或 Qwen-72B)来生成训练信号,这对于推理资源有一定要求。未来的方向可能在于如何利用模型自身的推理反馈(Self-correction)来实现更低廉、更高效的自我约束进化。
总结:如果你正在为 RL 训练中的奖励黑客行为头疼,FGRPO 告诉我们:不要尝试平衡一切,而要学会约束一切。