本文提出了 Fast-WAM,一种高效的世界动作模型(World Action Model)。通过将视频共同训练(Video Co-training)与测试时未来图像生成解耦,Fast-WAM 在不进行显式未来预测的情况下,实现了与 SOTA 方法相当的操控性能,且推理速度提升 4 倍以上。
TL;DR
清华大学与 Galaxea AI 的研究人员提出了 Fast-WAM,挑战了具身智能领域的一个主流假设:世界动作模型(WAM)必须在推理时生成未来视频。实验证明,视频预测的价值主要在于训练过程中的特征塑造(Representation Learning)。Fast-WAM 通过解耦训练建模与推理生成,实现了 190ms 的极低延迟,速度提升超 4倍,且性能依然维持在 SOTA 水平。
核心洞察:训练与推理的解耦
在传统的 World Action Models 中,模型通常被要求“先想再做”:
- 想象 (Imagine):根据当前观察,迭代生成未来几帧的预测视频。
- 执行 (Execute):基于生成的预测视频提取物理特征,再输出动作(Action)。
然而,视频去噪过程极其耗时。Fast-WAM 的核心 Insights 是:视频建模的本质是让编码器理解物理规律(如物体的运动、遮挡、力学等),这种理解可以固化在编码器的参数中。 因此,推理时完全可以略过耗时的视频生成步骤,直接从编码器的 Latent Space 预测动作。
Fast-WAM 架构:混合 Transformer 专家系统
Fast-WAM 基于 Wan2.2-5B 视频生成模型构建,采用了一种创新的 Mixture-of-Transformer (MoT) 架构:
- 共享注意力层:视频分支(Video DiT)和动作专家(Action Expert)共享部分结构,并通过精心设计的 Structured Attention Mask 控制信息流。
- 单次前向传播:推理时,模型仅对第一帧图像进行一轮 Encoding,动作分支直接访问该 Latent 结果,无需生成任何未来像素。
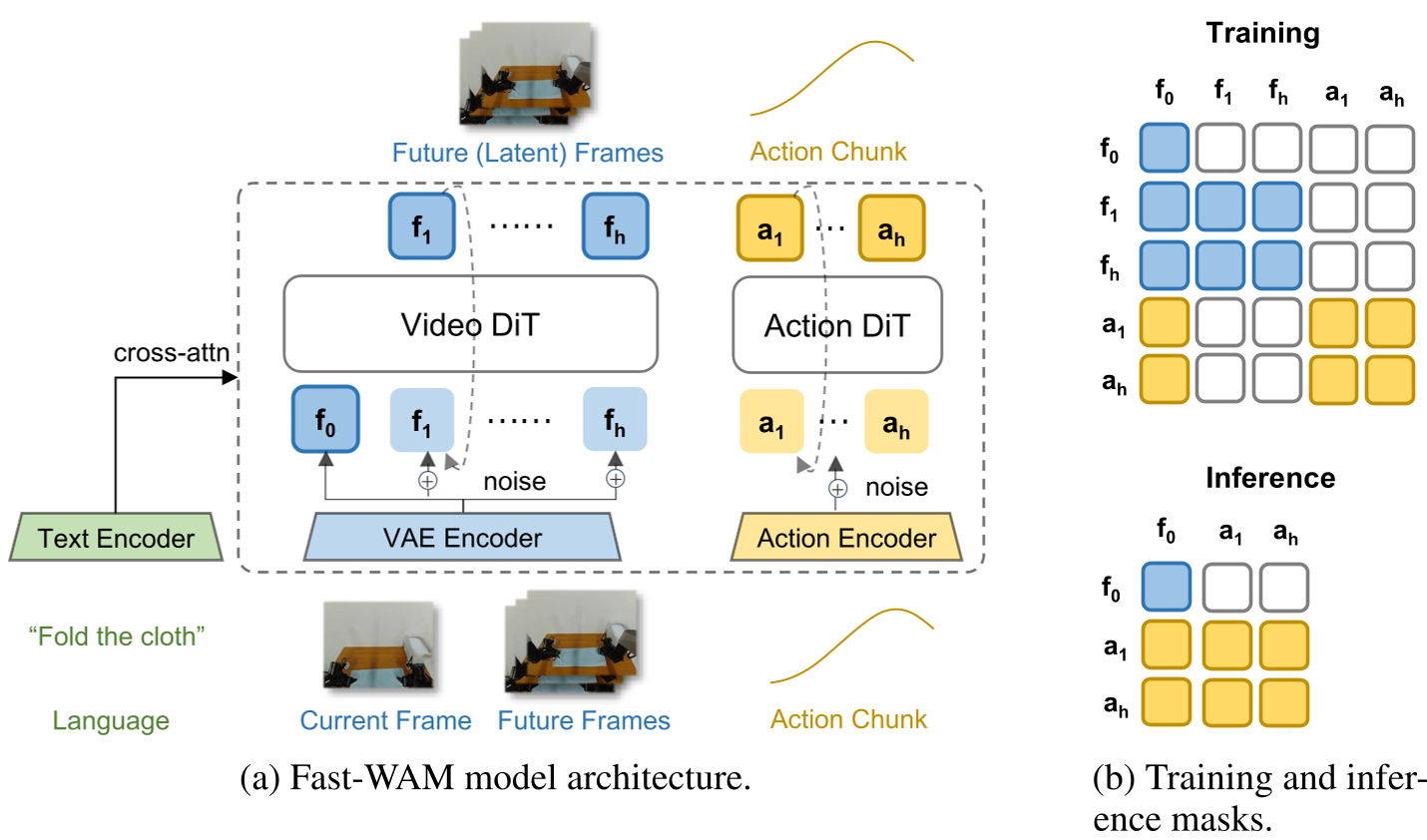
图注:通过 Mask 机制,动作分支可以在训练时由于视频预测任务受益,而在推理时保持独立高效。
实验战绩:速度与力量的平衡
研究团队在 LIBERO、RoboTwin 2.0 以及真实世界的**折毛巾(Towel Folding)**任务中进行了严苛测试。
1. 性能对比:不降反升
在 RoboTwin 仿真中,Fast-WAM 取得了 91.8% 的平均成功率,不仅优于许多需要复杂预训练的模型,甚至略高于某些强制要求测试时想象的变体(如 Joint Denoising 模式的 90.6%)。
2. 推理效率:降维打击
这是 Fast-WAM 最引人注目的优势。
- Fast-WAM (190ms) vs Fast-WAM-IDM (810ms)。
- 在实时机器人控制中,数百毫秒的差异决定了动作是否连贯以及能否应对动态环境。

3. 消融实验:证明“共同训练”才是王道
最重要的发现来自对训练目标的拆解:
- 只删掉推理想象:成功率几乎没有变化(91.8% vs 91.3%)。
- 删掉训练时的视频预测任务:成功率瞬间跌至 83.8%(仿真)和 10%(真实世界折毛巾)。 这实锤了:视频预测任务是提升模型物理理解的关键,但并不需要把预测结果画出来。
深度洞察
Fast-WAM 的成功对行业有两点重要启示:
- 具身智能的路线选择:我们不必在“慢速但有物理直觉”的世界模型和“快速但盲目”的 VLA 之间二选一。Fast-WAM 证明了可以通过 co-training 实现二者的融合。
- 计算资源的分配:未来的研究重心或许应该从“如何生成更逼真的预测视频”转向“如何通过视频生成目标来蒸馏更强的动作表征”。
局限性与展望
尽管 Fast-WAM 表现优异,但它目前尚未在大规模 Embodied Pretraining 数据集上进行极致扩展。此外,在极其复杂的长程规划(Long-horizon tasks)中,显式的视觉反馈是否仍有优势,仍需进一步探讨。
总结:Fast-WAM 为世界模型卸下了“想象力”的负担,却留住了其“智慧”的内核。这可能是通向高性能、高实时机器人普适策略的最优路径之一。